《数据仓库与数据分析实习》专题
-
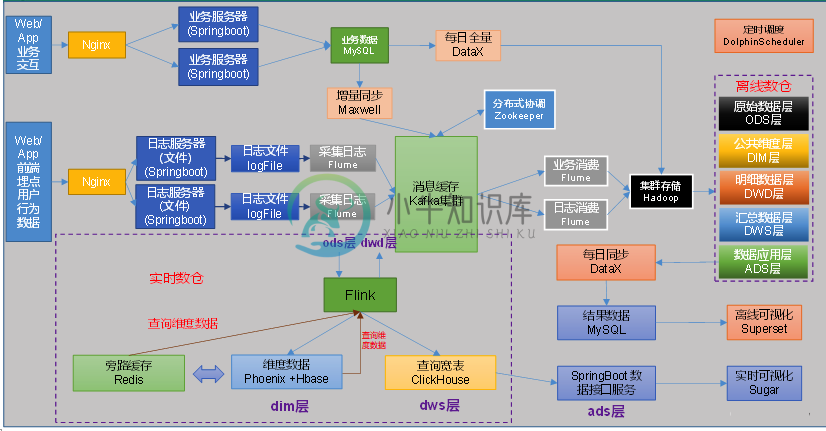 数据仓库建模过程分析
数据仓库建模过程分析主要内容:1.数据仓库概述,2.数据仓库建模概述,3.维度建模理论之事实表,4.维度建模理论之维度表,5.数据仓库设计1.数据仓库概述 1.1 数据仓库概念 数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。 1.2 数据仓库核心架构 2.数据仓库建模概述 2.1 数据仓库建模的意义 数据模型就是
-
Spring JPA数据仓库
我正在努力让Spring JPA Data为我工作,但一直在努力。问题出在这里。 我有两个域类,它们之间有一个简单的一对多关系: 我已经为每个类设置了存储库接口:CardRepository,扩展JpaRepository的用户存储库,两个存储库都注入到服务中 非常基本的设置。someMethod() 出现问题,其中我用它的标识符查询了一个用户,然后尝试获取映射@OneToMany的列表,然后发生
-
Spring数据仓库StackOverflow
在使用Spring数据存储库时发现一些奇怪的行为。 我写了这些类和接口: 当我尝试测试UserRepositoryImpl时,java。lang.StackOverflowerr被抛出 我发现save()方法存在一些问题。此外,delete()方法会引发stackoverflow。 我已经找到了解决办法。当我更改将存储库接口扩展为(例如)JpaUserRepository的接口的名称时,我的问题就
-
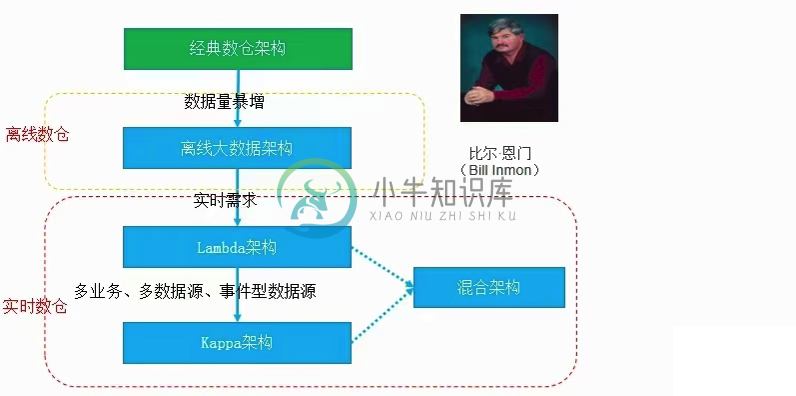 数据仓库发展
数据仓库发展主要内容:1.离线数仓,2.Lambda架构,3.Kappa架构,4.Smack架构,5.湖仓一体传统数仓 离线数仓 实时数仓 Lambda架构 Kappa架构 Smack架构 数据湖架构 仓湖一体架构 1.离线数仓 2.Lambda架构 Lambda架构是大数据平台里最成熟、最稳定的架构,它的核心思想是:将批处理作业和实时流处理作业分离,各自独立运行,资源互相隔离。 (1)Batch Laye:主要负责所有的批处理操作,支撑该层的技术以Hive、Spark-SQL或MapReduce这类批处
-
 货拉拉 数据仓库实习生
货拉拉 数据仓库实习生由于已经离职了,就发一下面经把 一面 自我介绍 项目 数仓怎么分层 数据倾斜怎么处理 join优化 实时数仓和离线数仓的定位 能实习多久 反问 数据量多少进去干什么工作对我的建议 进去主要负责什么 二面 说一下MR的执行流程 内部表和外部表的区别 其他记不太清了,主要是一些基本的数仓八股文
-
数据统计与分析
获取小程序概况趋势: $app->data_cube->summaryTrend('20170313', '20170313') 开始日期与结束日期的格式为 yyyymmdd。 API summaryTrend(string $from, string $to); 概况趋势 dailyVisitTrend(string $from, string $to); 访问日趋势 weeklyVisitT
-
数据统计与分析
通过数据接口,开发者可以获取与公众平台官网统计模块类似但更灵活的数据,还可根据需要进行高级处理。 {info} 接口侧的公众号数据的数据库中仅存储了 2014年12月1日之后的数据,将查询不到在此之前的日期,即使有查到,也是不可信的脏数据; 请开发者在调用接口获取数据后,将数据保存在自身数据库中,即加快下次用户的访问速度,也降低了微信侧接口调用的不必要损耗。 额外注意,获取图文群发每日数据接口的结
-
python实现数据分析与建模
本文向大家介绍python实现数据分析与建模,包括了python实现数据分析与建模的使用技巧和注意事项,需要的朋友参考一下 前言 首先我们做数据分析,想要得出最科学,最真实的结论,必须要有好的数据。而实际上我们一般面对的的都是复杂,多变的数据,所以必须要有强大的数据处理能力,接下来,我从我们面临的最真实的情况,一步一步教会大家怎么做。 1.数据的读取 2. 数据的处理 2.1.异常值(空值)处理
-
ebay-数据仓库面试
英文自我介绍和项目介绍 Good Afternoon, my name is Wang Longjiang,graduated from Anhui University. I have been working in the Institute of Aerospace Information, Chinese Academy of Sciences for two years. Focus o
-
 数据仓库:ELT和ETL
数据仓库:ELT和ETL主要内容:1.ETL,2.ELT,3.ELT的演变,4.ELT的工作原理,5.什么时候我们选择ELT,6.数据湖是不是很好的ELT落脚点,7.总结ETL 和 ELT 有很多共同点,从本质上讲,每种集成方法都可以将数据从源端抽取到数据仓库中,两者的区别在于数据在哪里进行转换 1.ETL ETL - 抽取、转换、加载 从不同的数据源抽取信息,将其转换为根据业务定义的格式,然后将其加载到其他数据库或数据仓库中。另一种 ETL 集成方法是反向 ETL,它将结构化数据从数据仓库中加载到业务数据库中,如我们
-
 好未来 数据仓库开发实习
好未来 数据仓库开发实习一面 项目深挖 数仓分几层,每一层的作用 事实表如何设计 维度表如何设计 数据域如何划分 业务总线矩阵的概念 如何设计完整的指标 开发中和上线后数据质量如何保证 如何设计调度,依据是什么 hive数据倾斜解决办法 hivesql常见优化手段 什么是spark宽窄依赖,起到什么作用 sql题:用户连续登录游戏的最大天数,允许间隔一天 反问 做什么业务 教培业务中的线下面授分析 网络问题迟到了一会,面
-
数据分析
有时候,对于我们的决定只要有一点点的数据支持就够了。一点点的变化,可能就决定了我们产品的好坏。我们可能会因此而作出一些些改变,这些改变可能会让我们打败巨头。 这一点和 Growth 的构建过程也很相像,在最开始的时候我只是想制定一个成长路线。而后,我发现这好像是一个不错的 idea,我就开始去构建这个 idea。于是它变成了 Growth,这时候我需要依靠什么去分析用户喜欢的功能呢?我没有那么多的
-
 敦煌网数据仓库实习生面试
敦煌网数据仓库实习生面试敦煌网(电商公司面试)(感觉像是kpi面试啊) 居然没要求开摄像头真是奇怪啊。 首先上来自我介绍,然后等我介绍到在滴滴实习的时候打断了我让我展开说说,之后就这段实习经历提问了很多,譬如如何处理数据异常,如何进行A/Btest等;接着是学校经历,问我大数据相关的课程有哪些,有看过阿里的大数据架构之类的书吗?回答没有,过(阿里的书这么受欢迎吗?啊,这就是强者盲从效应吗?)到
-
 一面数据-数据分析实习生面经
一面数据-数据分析实习生面经写在前面:这个岗位重视可视化的能力,在去年一战失败后也投过这个岗位的正职,面试前和面试中都在问有没有相应的可视化作品,对于实习生希望熟悉sql和tableau,一来就可以干活 1.自我介绍 2.对于以往实习经历和项目浅挖 3.次日留存sql代码考察 4.询问了不了解窗口函数 5.利用窗口函数计算不同品类前十GMV 6.tableau和power bi知识点考察 -技术问题一直准备的sql,DAX公
-
 知乎 数据仓库 凉经
知乎 数据仓库 凉经写在前面:这段时间经过了一段高强度笔面,但还是颗粒无收 面试 面试官进来就说:你不会flink? 我:了解的不多 那我们这次可能通过概率不大,但我们仍然可以就大数据来一波交流 实时: Flink的checkpoint Flink的反压 Flink的状态后端 离线: Kafka的有序性(不可全局有序,但可分区有序)面试官说不对??我让他下去再好好看看 Kafka一定不会丢数据嘛? Spark的内存模