《失效分析工程师》专题
-
profile 分析
算法工程师将算法移到 vsp_simulate 工程上来,除了将算法跑通,还有一项重要的功能就是优化算法,要尽可能节省内存空间,尽可能的提升算法的执行效率,本章就讲讲如何利用 profile 来快速定位哪个算法函数效率低下。 性能评测工具 gprof gprof 是 GNU Binutils 之一,它能为 Linux 程序精确分析性能瓶颈,能精确地给出函数被调用的时间和次数以及函数的调用关系,堪称
-
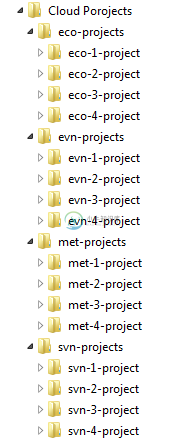 声纳Qube中的工程分离
声纳Qube中的工程分离我有一个项目结构,如下所示。 Cloud projects文件夹有四种类型的项目(eco-projects,evn-projects,met-projects,svn-projects) 每种类型的项目又包含四个不同的项目,比如在生态项目中,我们有生态-1-项目,生态-2-项目,生态-3-项目,生态-4-项目。
-
工程规约 - (一) 应用分层
1.【推荐】图中默认上层依赖于下层,箭头关系表示可直接依赖,如:开放接口层可以依赖于Web层,也可以直接依赖于Service层,依此类推。 开放接口层:可直接封装Service接口暴露成RPC接口;通过Web封装成http接口;网关控制层等。 终端显示层:各个端的模板渲染并执行显示层。当前主要是velocity渲染,JS渲染,JSP渲染,移动端展示层等。 Web层:主要是对访问控制进行转发,各类基
-
什么是词法分析?请描述下js词法分析的过程?
本文向大家介绍什么是词法分析?请描述下js词法分析的过程?相关面试题,主要包含被问及什么是词法分析?请描述下js词法分析的过程?时的应答技巧和注意事项,需要的朋友参考一下 词法分析指的是js引擎在执行前的编译过程之一。 词法分析和分词其实都是对js代码分割的一个过程。 词法分析大概分为三步骤,分析参数,分析变量声明,分析函数声明。 首先如果存在函数,分析函数的参数分别是什么。 其次 分析每一个变量
-
分析第一个C语言程序
主要内容:函数的概念,自定义函数和main函数,头文件的概念,最后的总结前面我们给出了一段最简单的C语言代码,并演示了如何在不同的平台下进行编译,这节我们来分析一下这段代码,让读者有个整体的认识。代码如下: 函数的概念 先来看第 4 行代码,这行代码会在显示器上输出“小牛知识库”。前面我们已经讲过,puts 后面要带 ,字符串也要放在 中。 在C语言中,有的语句使用时不能带括号,有的语句必须带括号。带括号的称为 函数(Function)。 C语言提供了很多功能,例如输
-
Java 多线程使用要点分析
本文向大家介绍Java 多线程使用要点分析,包括了Java 多线程使用要点分析的使用技巧和注意事项,需要的朋友参考一下 多线程细节问题 sleep方法和wait方法的异同点? 相同点: 让线程处于冻结状态. 不同点: sleep必须指定时间 wait可以指定时间也可以不指定时间 sleep时间到,线程处于临时阻塞状态或者运行态 wait如果没有时间,必须通过notify或者notifyAll唤醒
-
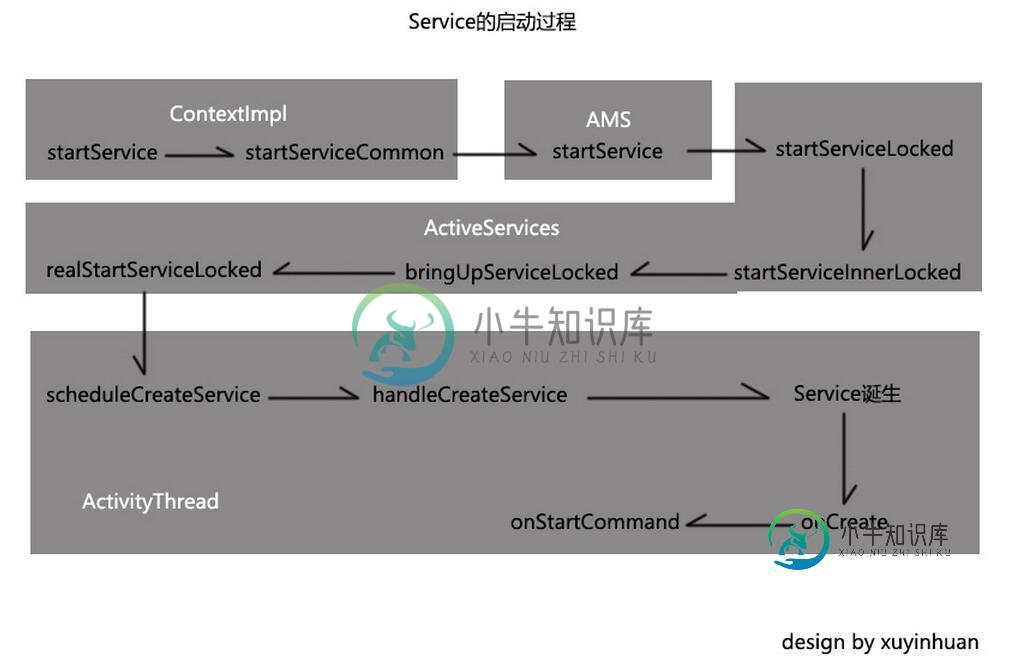 Android Service启动过程完整分析
Android Service启动过程完整分析本文向大家介绍Android Service启动过程完整分析,包括了Android Service启动过程完整分析的使用技巧和注意事项,需要的朋友参考一下 刚开始学习Service的时候以为它是一个线程的封装,也可以执行耗时操作。其实不然,Service是运行在主线程的。直接执行耗时操作是会阻塞主线程的。长时间就直接ANR了。 我们知道Service可以执行一些后台任务,是后台任务不是耗时的任务,
-
nginx源码分析线程池详解
本文向大家介绍nginx源码分析线程池详解,包括了nginx源码分析线程池详解的使用技巧和注意事项,需要的朋友参考一下 nginx源码分析线程池详解 一、前言 nginx是采用多进程模型,master和worker之间主要通过pipe管道的方式进行通信,多进程的优势就在于各个进程互不影响。但是经常会有人问道,nginx为什么不采用多线程模型(这个除了之前一篇文章讲到的情况,别的只有去问作
-
深入分析SQL Server 存储过程
本文向大家介绍深入分析SQL Server 存储过程,包括了深入分析SQL Server 存储过程的使用技巧和注意事项,需要的朋友参考一下 Transact-SQL中的存储过程,非常类似于Java语言中的方法,它可以重复调用。当存储过程执行一次后,可以将语句缓存中,这样下次执行的时候直接使用缓存中的语句。这样就可以提高存储过程的性能。 Ø 存储过程的概念 存储过程Procedure是一组为
-
以编程方式分析jar文件
问题内容: 我需要以编程方式计算给定jar文件中已编译类,接口和枚举的数量(因此我需要三个单独的数字)。哪个API对我有帮助?(我不能使用第三方库。) 我已经尝试过非常棘手的方案,这似乎并不总是正确的。即,我将每个ZipEntry读入byte [],然后将结果提供给我的自定义类加载器,该加载器扩展了标准CalssLoader并将此byte []发送到ClassLoader.defineClass(
-
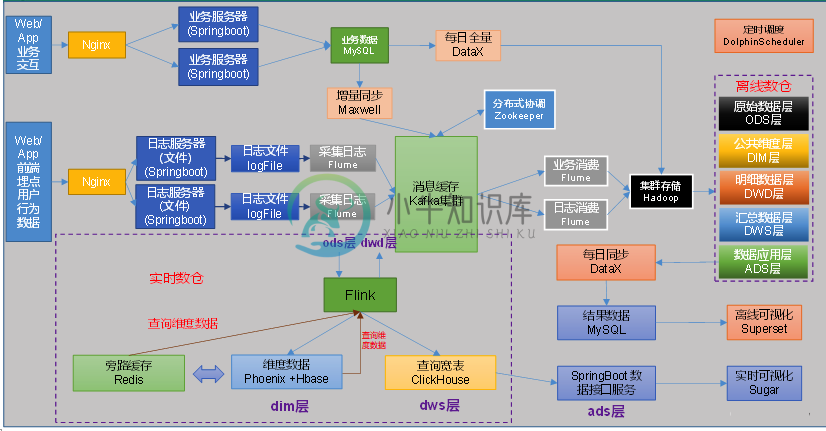 数据仓库建模过程分析
数据仓库建模过程分析主要内容:1.数据仓库概述,2.数据仓库建模概述,3.维度建模理论之事实表,4.维度建模理论之维度表,5.数据仓库设计1.数据仓库概述 1.1 数据仓库概念 数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。 1.2 数据仓库核心架构 2.数据仓库建模概述 2.1 数据仓库建模的意义 数据模型就是
-
Redis中主键失效的原理及实现机制剖析
本文向大家介绍Redis中主键失效的原理及实现机制剖析,包括了Redis中主键失效的原理及实现机制剖析的使用技巧和注意事项,需要的朋友参考一下 作为一种定期清理无效数据的重要机制,主键失效存在于大多数缓存系统中,Redis 也不例外。在 Redis 提供的诸多命令中,EXPIRE、EXPIREAT、PEXPIRE、PEXPIREAT 以及 SETEX 和 PSETEX 均可以用来设置一条 Key-
-
分析或未分析,选择什么
问题内容: 我仅使用kibana搜索ElasticSearch,并且我有几个只能接受几个值的字段(最坏的情况,服务器名,30个不同的值)。 我确实了解分析对像这样的更大,更复杂的字段执行的操作,但是对于那些简单的小字段,我却无法理解分析/未分析字段的优点/缺点。 那么,对于“有限的一组值”字段(例如,服务器名:server [0-9] *,没有特殊字符可以打破),使用analyd和not_anal
-
缓存失效风暴
看下这个段伪代码: local value = get_from_cache(key) if not value then value = query_db(sql) set_to_cache(value, timeout = 100) end return value 看上去没有问题,在单元测试情况下,也不会有异常。 但是,进行压力测试的时候,你会发现,每隔 100 秒,数据库的
-
Storm-Kafka喷口失效
我使用storm0.9.4和storm-kafka:0.9.0-wip16a-scala292作为从kafka0.7读取的依赖项。 我们的Kafka保留政策是7天。 我从经纪人的最新偏移量开始读取。