《大数据分析》专题
-
创建分区时的Kafka数据行为
我正在测试在一个正在运行的系统中添加Kafka分区,但我不清楚如果您将分区添加到一个现有的主题中,Kafka如何管理现有的数据。 例如: 我有一个主题为的Kafka实例,有一个分区和一个副本。 生产者组开始插入该主题,消费者组开始消费。 我更改主题以添加另一个分区。 在本例中,主题数据发生了什么?是在两个分区之间重新平衡,还是只有新生成的数据才会使用新分区?
-
spring数据jpa可分页排序错误
我使用了spring boot(1.3.5)、spring-data、spring-data-jpa、JPA(hibernate/hsqldb)。 代码: 控制器: 我试着 也是,但不起作用。 浏览器输出: SQL无效!额外的“:”和重复的“ASC ASC”。 控制台输出:
-
十分钟搞定 Pandas - 二、 查看数据
详情请参阅:基础。 1、 查看DataFrame中头部和尾部的行: In [14]: df.head() Out[14]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.11
-
jQuery EasyUI 数据网格 – 自定义分页
pre { white-space: pre-wrap; } 数据网格(datagrid)内置一个很好特性的分页功能,自定义也相当简单。在本教程中,我们将创建一个数据网格(datagrid),并在分页工具栏上添加一些自定义按钮。 创建数据网格(DataGrid) <table id="tt" title="Load Data" url="data/datagrid
-
C语言内存分布之数据段
内存分布之数据段 不管我们以后是自己写代码还是读别人的代码,都应该想想这个变量默认存储的位置。在我们以后的嵌入式开发中,技巧性的代码越来越多的时候,我们可能把某一些代码放在一段。我们可以通过修改变量或者代码默认放置的段,让它被放到其它的段中。我们也可以自己定义一个新的段。 随着运行,栈空间是随时会变化的。栈空间临时的去存储一些变量,当我们进入一个函数,系统就会在栈空间去分配一片内存去保存这个函数里
-
 得物 数据开发 kpi面13分钟
得物 数据开发 kpi面13分钟1.Java的数据结构相关 2.HashMap怎么解决哈希冲突的 3.HashMap和HashSet区别 4.Spark shuffle 5.Maven会用吗,怎么解决版本冲突? 6.实习相关 反问 做什么的?用什么? 偏底层,主要是做Spark和Flink底层的一些东西
-
python 如何分批查询Oracle的数据?
python 如何分批查询Oracle 就是比如数据库有几万数据第一次查询前100以此类推一直到查询到所有数据
-
 滴滴数据分析面试8~10|数科部日常实习Offer
滴滴数据分析面试8~10|数科部日常实习Offer滴滴-数据科学与智能部-数据分析日常实习,通常两面或一面。 面经8,一面30多分钟+二面30多分钟,已Offer 1. 自我介绍。 2. 分别介绍最近两段实习里(手子与滴滴)印象深刻的项目经历:项目策略的目的、分析方法、遇到的困难、解决办法、产出成果。 3. 最有成就感的一段经历,为什么有成就感?(讲了一堆分析方法,但面试官想考察的是性格和品质,比如自驱去发现问题/被动完成任务哪种更能激励我) 4
-
如何在数据类中启动固定大小的数组
我试图研究它,但没有找到答案。我正在创建一个数据类,在该类中,我想创建一个固定大小的数组。我尝试了以下3个选项: 但是都不行。然而,这确实有效: 如何在数据类中初始化固定大小的字符串数组
-
 某乙方软件公司-数仓实施-大数据开发
某乙方软件公司-数仓实施-大数据开发1.自我介绍 2.学校是哪里的,家庭成员,父母做什么的 3.能接受加班,能出差吗? linux服务器之间的文件传输命令 怎么查看日志 什么是中间件(中间件) 4.sql熟悉吗,增删改查的命令有哪些。 5.有啥想问的? 6.未来规划 正如我所写的那样,很简单,但是我还是有些忘了没答上来。 面试难度,因为我有些简单的都没答上来,好像提前结束了。可以试着冲一冲。
-
在Excel VBA中使用SQL的“分组依据”功能对数据进行分组
问题内容: 我有两个表(1&2)应该合并到第三(3)个表中。 表1:F_Number,A_Number, A_Weight 表2:A_Number,A_Country表3:F_Number,A_Country,A_Weight 第三表应按F_Number分组,求和A_Weight,其中A_Country具有相同的值。到目前为止,表的联接工作正常: 结果是一个像这样的表: F_Number; 一个国
-
按两列对数据帧分组并获取计数
我有一个熊猫数据框,格式如下: df: 现在我想将其分为两列,如下所示: 输出: 我想得到每一行的计数,如下所示。预期产出: 如何获得我的预期输出?我想找出每个“col2”值的最大计数?
-
Spark Scala-将结构数组拆分为数据帧列
我有一个包含结构数组的嵌套源json文件。结构的数量因行而异,我想使用Spark(scala)从结构的键/值动态创建新的数据框架列,其中键是列名,值是列值。 这里有一个由3个结构组成的数组,但这3个结构需要动态地拆分为3个单独的列(3个的数量可能会有很大的变化),我不知道如何做到这一点。 请注意,数组中的每个数组元素都产生了3个新列。 我认为理想的解决方案与本SO帖子中讨论的类似,但有两个主要区别
-
Apache Flink[在scala中]计算流数据的分位数
我想用Scala计算Flink中流数据的分位数。我的问题类似于但比这一个更简单,flink计算中位数。我认为这可以通过定义一个自定义聚合函数来实现,但我正在寻找一些Scala示例。我已经看了本章中的例子https://github.com/dataArtisans/flink-training-exercises但是没有完全找到我要找的东西。我计算了总和,平均值,我想计算第95个百分位数。 我希望
-
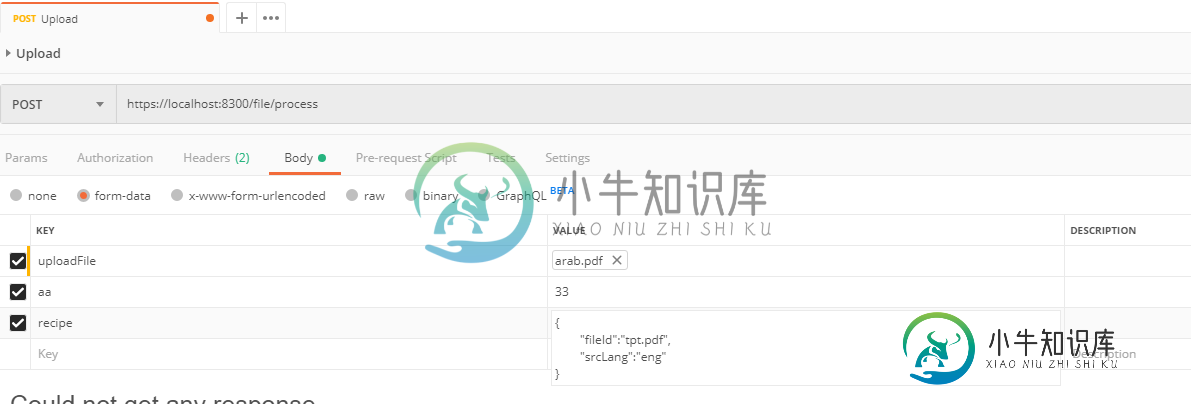 接收多部分表单数据json参数为空
接收多部分表单数据json参数为空我正在尝试从接收包含3个参数的多部分请求: 一个 一个 我在控制器中接收到和fine,但json的所有字段都为NULL。会有什么问题吗? JSON 控制器 邮差