《大数据分析》专题
-
 蔚来-数字系统数据分析师-一面面经
蔚来-数字系统数据分析师-一面面经7月18号约面试,7月19号下午面试。面试官挺和蔼的,但是我感觉是kpi面试。 面试内容:1、自我介绍。 2、因为简历没有实习经历,面试官询问了一下。 3、问会什么编程软件,Python,Sql,介绍了一下会的库和算法。 4、反问环节面试官介绍了一下工作内容等。 有友友投了一样的岗位可以一起交流呀! #蔚来面试##数据分析#
-
根据分辨率绘制不同大小的形状
因此,我有一个SurfaceView类绘制所有对象。 例如,当我画一个圆时,我必须指定一个大小 有没有办法根据屏幕分辨率和密度的大小来调整尺寸 因为我在画圆时,我希望它在低分辨率设备上的大小与在高分辨率设备上的大小相同。 当绘制半径为50px的圆时,较小屏幕上的圆比较大屏幕上的圆大。 有什么想法吗? 编辑:我知道在创建一些布局时,我可以使用密度像素。但我不是在做布局,我是在surfaceview上
-
Yii实现MySQL多数据库和读写分离实例分析
本文向大家介绍Yii实现MySQL多数据库和读写分离实例分析,包括了Yii实现MySQL多数据库和读写分离实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了Yii实现MySQL多数据库和读写分离的方法。分享给大家供大家参考。具体分析如下: Yii Framework是一个基于组件、用于开发大型 Web 应用的高性能 PHP 框架。Yii提供了今日Web 2.0应用开发所需要的几乎一切
-
python数据分析:关键字提取方式
本文向大家介绍python数据分析:关键字提取方式,包括了python数据分析:关键字提取方式的使用技巧和注意事项,需要的朋友参考一下 TF-IDF TF-IDF(Term Frequencey-Inverse Document Frequency)指词频-逆文档频率,它属于数值统计的范畴。使用TF-IDF,我们能够学习一个词对于数据集中的一个文档的重要性。 TF-IDF的概念 TF-IDF有两部
-
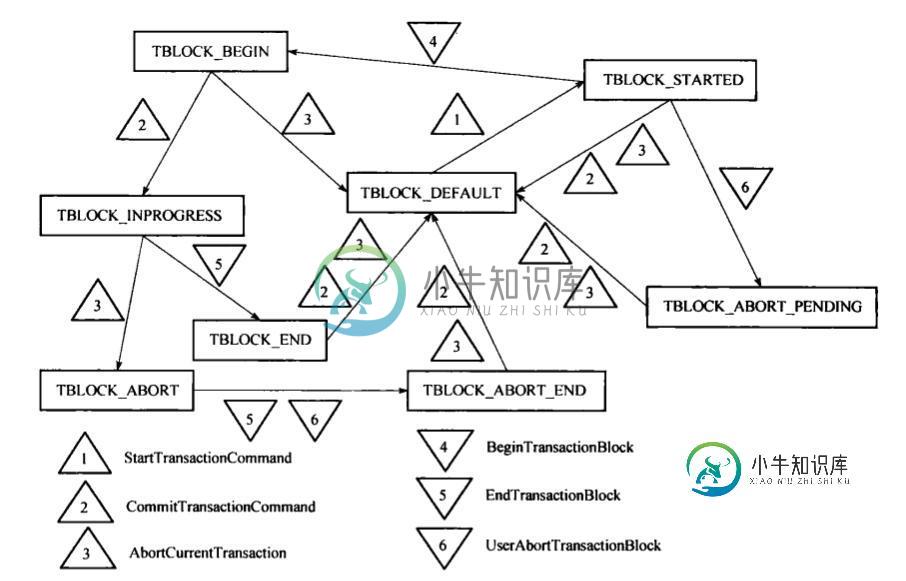 PostgreSQL数据库事务实现方法分析
PostgreSQL数据库事务实现方法分析本文向大家介绍PostgreSQL数据库事务实现方法分析,包括了PostgreSQL数据库事务实现方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PostgreSQL数据库事务实现方法。分享给大家供大家参考,具体如下: 事务简介 事务管理器:有限状态机 日志管理器 CLOG:事务的执行结果 XLOG:undo/redo日志 锁管理器:实现并发控制,读阶段采用MVCC,写阶段采用锁控
-
Regex用于分析数据库列,如JDBC ResultSet
我正在使用JDBC从查询结果中获取列。 例如: 我想在运行查询之前解析它们。本质上,我希望为列标签创建一个数组,该数组将与resultSet所期望的值相匹配。get**方法。出于说明的目的,我想用这个替换上面的循环,并得到相同的结果: 这看起来很简单。我可以用一个简单的正则表达式解析我的语句,该正则表达式接受SELECT和from之间的字符串,使用列分隔符创建组,并从组中构建arrayOf列。但是
-
如何进行探索性数据分析(EDA)?
本文向大家介绍如何进行探索性数据分析(EDA)?相关面试题,主要包含被问及如何进行探索性数据分析(EDA)?时的应答技巧和注意事项,需要的朋友参考一下 EDA的目的是去挖掘数据的一些重要信息。一般情况下会从粗到细的方式进行EDA探索。一开始我们可以去探索一些全局性的信息。观察一些不平衡的数据,计算一下各个类的方差和均值。看一下前几行数据的信息,包含什么特征等信息。使用Pandas中的df.info
-
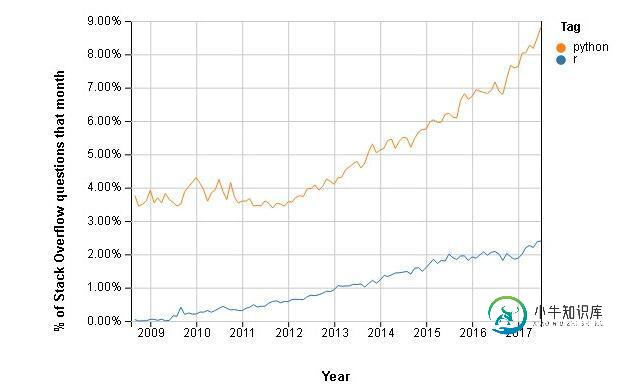 R vs. Python 数据分析中谁与争锋?
R vs. Python 数据分析中谁与争锋?本文向大家介绍R vs. Python 数据分析中谁与争锋?,包括了R vs. Python 数据分析中谁与争锋?的使用技巧和注意事项,需要的朋友参考一下 当我们想要选择一种编程语言进行数据分析时,相信大多数人都会想到R和Python——但是从这两个非常强大、灵活的数据分析语言中二选一是非常困难的。 我承认我还没能从这两个数据科学家喜爱的语言中选出更好的那一个。因此,为了使事情变得有趣,本文将介绍
-
ASP.NET数据库缓存依赖实例分析
本文向大家介绍ASP.NET数据库缓存依赖实例分析,包括了ASP.NET数据库缓存依赖实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了ASP.NET数据库缓存依赖,分享给大家供大家参考。具体如下: 一般在ASP.NET中,Cache类最酷的特点是它能根据各种依赖来良好的控制自己的行为。以文件为基础的依赖是最有用的,文件依赖项是通过使用 Cache.Insert 并提供引用文件的 C
-
实例分析ORACLE数据库性能优化
本文向大家介绍实例分析ORACLE数据库性能优化,包括了实例分析ORACLE数据库性能优化的使用技巧和注意事项,需要的朋友参考一下 ORACLE数据库的优化方式和MYSQL等很大的区别,今天通过一个ORACLE数据库实例从表格、数据等各个方便分析了如何进行ORACLE数据库的优化。 tsfree.sql视图 这个sql语句迅速的对每一个表空间中的空间总量与每一个表空间中可用的空间的总量进行比较 表
-
Spring对不同数据的批处理分析
我有一个场景,文件有不同的类型。文件分为页眉、正文和页脚三部分。标题可以是2类型dipend,根据标题大小,我需要使用标记器和范围来解析内容。 页脚也一样,这取决于正文大小和页脚长度,需要解析页脚内容。 我查看了PatternMatchingCompositeLineMapper和fixedlenghttokenizer,但没有找到为范围指定条件的方法,也没有找到在页脚中共享正文内容以检查长度的方
-
深入分析Mongodb数据的导入导出
本文向大家介绍深入分析Mongodb数据的导入导出,包括了深入分析Mongodb数据的导入导出的使用技巧和注意事项,需要的朋友参考一下 一、Mongodb导出工具mongoexport Mongodb中的mongoexport工具可以把一个collection导出成JSON格式或CSV格式的文件。可以通过参数指定导出的数据项,也可以根据指定的条件导出数据。 mongoexport具体用法 参数说明
-
 快手 数据分析日常实习 面试
快手 数据分析日常实习 面试笔试: 投递后很快就收到了hr的回复,发了一个word文档作为笔试题,24h内完成,不是很难 几道SQL题(窗口函数),一道业务题(给了一个生活场景,问你的分析思路,我写了swot分析),几道python题(关于数据处理和数据整理,主要考点是pandas) 一面20min: 1.自我介绍 2.在上一段实习中选一个能体现分析能力的项目的介绍,挖得很深,问了很多方法上的细节和原因 3.抖音和快手的区别
-
 字节电商数据分析——一面凉经
字节电商数据分析——一面凉经今天面了电商数据分析一面,来写写面经,感觉问的问题倒是不难可惜自己没准备好,还是蛮可惜的,emo中~ 面试下午五点开始,面试官胖胖的很可爱,像我的博士学长哈哈~但是还是很紧张,可能是第一次面大厂 SQL题: 1:dense_rank(),rank()和row_number()三个函数的区别 2:用户登录日期的最大间隔是多少 这个我当时有点慌,采用了计算用户连续登录天数的做法,当时也想到了用
-
 boss直聘数据分析师一面面经
boss直聘数据分析师一面面经面试时长38nin 逃不掉的自我介绍 介绍项目,没有深挖 统计学: 说一说样本量计算方法? 假设检验两类错误? 当流量不平衡时两类错误的变化?比如说ab测试,a和b的样本量不相等。----我没回答上来 参数检验和非参数检验讲一讲? 代码题: python生成斐波那契数列,判断一个数是否是素数。 sql累计登录天数 你有什么要问我的吗? 感觉已凉😭 今早HR通知一面通过,约的明天二面