《广告投放》专题
-
 【投稿】海康威视嵌入式软件开发面经汇总
【投稿】海康威视嵌入式软件开发面经汇总公号:嵌入式校招君 嵌入式软件开发最强攻略一篇就够了!《嵌入式软件开发笔试与面试手册》:https://blog.nowcoder.net/zhuanlan/jvN8gj 以下是海康威视嵌入式面经汇总 一 一面:自我介绍项目 项目中的自己主导部分项目中的难点蓝牙传输特性TCP的传输丢失解决树莓派和单片机的区别(楼主做树莓派的,但感觉这个问题没答好) 过了一周受到二面通知 二面: 自我介绍 选一个印
-
Jasper报告为子报告设置了不同的java bean收集数据适配器
有人能告诉我如何为子报表设置不同的数据适配器吗?我似乎找不到使用不同连接的示例/教程。本质上,我正在创建一个基于JavaBean集合的报告,我正在努力迭代一个嵌套的对象集合,所以我想我会创建一个子报告,该子报告使用不同的JavaBean集合数据适配器集到主报告中JavaBean对象所包含的ListArray对象(我希望这是清楚的?)。 因此,例如,我可能有对象供应商,它作为JavaBean集合数据
-
使用SUBMIT在ABAP中将数据从一个报告传递到另一个报告
本文向大家介绍使用SUBMIT在ABAP中将数据从一个报告传递到另一个报告,包括了使用SUBMIT在ABAP中将数据从一个报告传递到另一个报告的使用技巧和注意事项,需要的朋友参考一下 您的语法似乎没有任何错误。请验证您是否正确声明了变量。如果正确定义了它们,请尝试扩展语法检查以查看错误。可以通过转到PROGRAM => Check => Extended Syntax Check来进行扩展检查。
-
python基于socket实现网络广播的方法
本文向大家介绍python基于socket实现网络广播的方法,包括了python基于socket实现网络广播的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python基于socket实现网络广播的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的Python程序设计有所帮助。
-
python实现广度优先搜索过程解析
本文向大家介绍python实现广度优先搜索过程解析,包括了python实现广度优先搜索过程解析的使用技巧和注意事项,需要的朋友参考一下 广度优先搜索 适用范围: 无权重的图,与深度优先搜索相比,深度优先搜索法占内存少但速度较慢,广度优先搜索算法占内存多但速度较快 复杂度: 时间复杂度为O(V+E),V为顶点数,E为边数 思路 广度优先搜索是以层为顺序,将某一层上的所有节点都搜索到了之后才向下一层搜
-
是否有广泛的现代Java编码约定?
问题内容: Sun的“ Java编程语言代码约定 ”最近一次更新是在1999年4月。十年后,该语言以及常规用法发生了很多变化。还有更多最新的,被广泛采用的标准吗? 大多数准则都省略了指定文件编码和行尾的规定。Sun建议混合使用制表符和空格。Eclipse IDE默认为Eclipse的标准,即仅选项卡。在Maven的风格指南只是空格。许多样式指南(例如JBoss)都遵循Sun的指南,但是更喜欢使用K
-
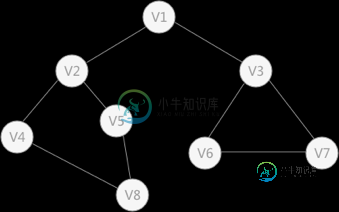 深度优先搜索和广度优先搜索
深度优先搜索和广度优先搜索主要内容:深度优先搜索(简称“深搜”或DFS),广度优先搜索,总结前边介绍了有关图的 4 种存储方式,本节介绍如何对存储的图中的顶点进行遍历。常用的遍历方式有两种: 深度优先搜索和 广度优先搜索。 深度优先搜索(简称“深搜”或DFS) 图 1 无向图 深度优先搜索的过程类似于树的先序遍历,首先从例子中体会深度优先搜索。例如图 1 是一个无向图,采用深度优先算法遍历这个图的过程为: 首先任意找一个未被遍历过的顶点,例如从 V1 开始,由于 V1 率先访问过了,所以
-
无队列的非递归广度优先遍历
在由具有指向父节点、兄弟节点和第一个/最后一个子节点的节点表示的通用树中,如: 是否可以在不使用任何其他帮助程序结构(如队列)的情况下执行迭代(非递归)广度优先(级别顺序)遍历。 所以基本上:我们可以使用单节点引用进行回溯,但不能保存节点集合。它是否能够完成是理论上的一部分,但更实际的问题是,它是否能够在不回溯大片段的情况下高效地完成。
-
 兴业银行广州分行-金融科技,润
兴业银行广州分行-金融科技,润面试官还是挺好的,开了摄像头 两分钟: 1,自我介绍; 2,优缺点 3,如何克服你的缺点; 4,是否接受轮岗-轮一年以上,竞聘,不一定能回来; 5,学校成绩如何? 不到两分钟就结束了,估计是觉是我不会去桂圆,所以就不再问下去了。#秋招##面经##校招#
-
 浦发银行广州分行信息科技岗
浦发银行广州分行信息科技岗1.一分钟自我介绍,包括熟悉的语言以及做过的项目?优缺点? 2.为什么选择浦发? (“因为互联网行情不好”,于是我凉了)
-
 广州诗悦网络游戏测试一二面
广州诗悦网络游戏测试一二面10.01 笔试 10.14 一面技术面(30min) 1.自我介绍 2.为什么不选开发而选择测试 3.测试流程 4.bug的生命周期 5.回归测试不通过怎么解决。 6.对炉石传说卡牌退环境的看法 7.对明日方舟的看法 8.了解诗悦吗 9.你的沟通能力怎么样 10.简单谈一下你组织的活动是怎么安排的 反问 1.诗悦最吸引你的地方 2.在诗悦印象最深刻(最快乐)的事情是什么 3.哪个项目组 4.对我
-
13 广度遍历和深度遍历二叉树
给定一个数组,构建二叉树,并且按层次打印这个二叉树
-
正确使用大型广播变量的提示?
问题内容: 我正在使用一个大约100 MB腌制的广播变量,与之近似: 在具有3个c3.2xlarge执行程序和m3.large驱动程序的群集上运行,并使用以下命令启动交互式会话: 在RDD中,如果我坚持对该广播变量的引用,则内存使用量将激增。对于100 MB变量的100个引用,即使将其复制100次,我也希望数据使用总量不超过10 GB(更不用说在3个节点上30 GB)。但是,运行以下测试时,我看到
-
如何在SQL中进行广度优先搜索?
问题内容: 给定一棵存储为关系的树: 如何获得给定节点的所有后代?例如,对于1,我要(1、2、3、4、5、6),对于3我要(3、4、5),对于7我要(7、8、9)。 我正在通过脚本(Python,但这没关系)执行此操作,因此我可以执行以下操作: 但是,如果有一些时髦的SQL可以让我在一个查询中执行此操作,那将是非常棒的。 问题答案: 如果您有能力更改表定义,则使用嵌套集而不是直接父链接会使此问题更
-
将stdClass对象转换/广播到另一个类
问题内容: 我正在使用第三方存储系统,无论出于什么原因,无论输入什么内容,它都只会返回stdClass对象。因此,我很想知道是否有一种方法可以将stdClass对象转换/转换为给定类型的完整对象。 例如: 我只是将stdClass转换为数组并将其提供给BusinessClass构造函数,但是也许有一种方法可以还原我不知道的初始类。 注意:我对“更改存储系统”类型的答案不感兴趣,因为它不是关注点。请