《大数据开发实习生》专题
-
开发资源 学习资源一览表
A collection of awesome Ruby libraries, tools, frameworks and software. The essential Ruby to build modern Apps and Web Apps. Inspired by the awesome-* trend on GitHub. The goal is to build a categori
-
 火花数仓实习生笔试
火花数仓实习生笔试1、返回每个部门工资排名前二的员工() A、使用ROW NUMBER()函数并通过子查询过滤 B、使用RANK()函数并通过子查询过滤RANK <2 C、使用DENSE RANK()函数并通过子查询过滤RANK <=2 D、使用NTILE(2)函数 2、SQL排序时希望特定某个值排在最后(如null、Unknow等) A、ORDER BY column name ASC B、ORDER BY co
-
 北大信研院Java实习一面(40min)
北大信研院Java实习一面(40min)一、HR提问: (1)InnoDB / MyISAM(√) (2)聚簇索引 / 非聚簇索引(√) (3)MySQL大表优化(√) (4)水平分表策略(√) (5)List / Set(√) (6)HashMap中JDK1.6 / 1.7的区别(√) (7)红黑树的查找过程(×) (8)HashMap扩容过程(√) (9)sleep() / wait()(√) (10)两个大文件怎么找出相同的数字(
-
 某大厂产品经理实习面经
某大厂产品经理实习面经噢,是我面别人,哈哈哈。 1. 自我介绍 主要是让小朋友别紧张,趁机再读一遍候选人简历。 2. 问问为啥想干产品经理 防一手小朋友没想明白,干两天跑路了啥的。 尤其我怕小朋友听那些"产品经理是离CEO最近的工作"听多了,以为是来当CEO的,入职之后再给我裁了。 3. 讲讲最牛逼的这段项目/实习是干啥的 看看小朋友废话多不多,防一手讲个五分钟都讲不到重点。入职以后该耽误我下班打游戏的时间了捏。 两三
-
 【25暑期实习】Soul大模型一面
【25暑期实习】Soul大模型一面面试时长40分钟 自由交流15分钟 面试官小姐姐超超超超温柔 1. 自我介绍 2. 问大模型实习项目,做了什么,用了什么开源模型,主要是chatglm和llama 3. 有没有尝试过改原模型的设计,比如结构或者loss函数?为什么不? 3. 说一下chatglm或llama与传统transformer结构的区别,有哪些改动,和可以借鉴的地方?主要从模型结构、layer norm、激活方式、位置编码
-
 大众汽车(CARIAD China)Android实习面经
大众汽车(CARIAD China)Android实习面经9月就在实习僧投了,一直没有响应,一直到12月好像原本的实习生准备离职了所以腾出了一个HC才想要招人 一面(2023/12/7 45min) 如何实现一个循环链表?树的遍历方式有哪些? 项目介绍,聊项目 如何实现跨线程的数据和UI更新?Handler机制和回调 Activity和Fragment的生命周期?Activity和Fragment之间如何数据传递? Android里面如何去调用c、c++
-
 25届Java比特大陆实习面经
25届Java比特大陆实习面经1、垃圾回收算法和对应的垃圾回收器,然后问了cms和g1的回收过程。(g1的回收过程没打出来) 2、偏向锁、轻量级锁、重量级锁的内容以及锁的升级过程。 3、cas是什么,aqs是什么,aqs的节点是怎么加入到队列的。(我说最后一个节点的next=当前节点,当前节点的pre=最后一个节点,他说这样存在并发安全问题,然后我不知道怎么办了) 4、aop怎么做的,springboot的自动装配原理。 5、
-
 科大讯飞Java日常实习凉经
科大讯飞Java日常实习凉经#科大讯飞# 主要针对项目问(做的苍穹外卖) 1.redis在项目中怎么应用的?缓存了什么 2.说说对jwt的了解,往细一点说 3.优惠券库存超卖的问题是怎么实现的?如果两个人同时去抢这个优惠券怎么办?(加锁,锁粒度为优惠券的标识) 4.如果用户下单,在规定的时间内没有支付,对于这种失效情况要怎么做?(mq延时消息,加个定时mq) 5.对数据结构了解的怎么样? 6.最近刷题有遇到哪一题印象比较深的
-
 科大讯飞AIGC算法实习面试
科大讯飞AIGC算法实习面试项目问题: 1、增强纠错译码项目是怎么做的?目前有几个人在做? 2、该项目未来方向是利用bert来提取自然冗余信息,具体怎么做? 3、NLP的发展历史?(attention+transformer+bert) 4、bert的两个应用场景?(完形填空+给一句话预测下一句) 5、你生活中是怎么使用大模型的?(chat-gpt?文献检索+代码解读+图像生成) 6、yolo和R-CNN区别? 7、目标检测
-
 大二前端第一次实习面经
大二前端第一次实习面经楼主是第一次面试,在boss上随便海投了几十家公司,收到了几家的笔试邀请,做了其中一家的笔试(不知名小公司),时长1h30min,运气好过了,之后开始约面试 一面:1h 1.自我介绍。面试官:你现在大二是吗,这么急就出来找实习啊。我:呵呵,是啊找实习要趁早 2.get和post的区别 3.缓存,说说强缓存和协商缓存 4.cookie和webstorage的区别(这个我老熟了) 5.项目相关 6.怎
-
 一汽大众 暑期实习 无消息
一汽大众 暑期实习 无消息5.21起 5.22投 开发管理工程师(开发管控)-数字化管理 挂 产品开发工程师(座舱电子) 5.27测评 2天内完成 normstar 单选x3(政治正确) 1min 工作场景抉择x25 20min 选词填空x15 8min 单选x30(找规律、语病、图表阅读、文段阅读)30min 性格测评(以下更符合你实际情况的一项是)x10 5min 观察表情和体态推断x18 12min 心理测评x23
-
为大数据生成最佳UUID
“...如果这不可行,RFC4122建议使用命名空间变体,如类型5 UUID。” 我计划使用Java生成UUID,并引用了API https://docs.oracle.com/javase/8/docs/API/Java/util/UUID.html 通过维基百科:
-
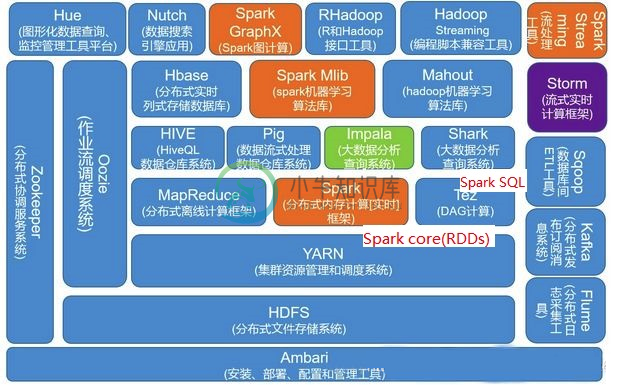 大数据生态圈的理解
大数据生态圈的理解HDFS是整个大数据架构的底层,它提供了一个文件系统 Spark(Spark core(RDD)) 和 MapReduce 是一个层级,是一种操作计算框架,MapReduce相当于一个别人写好的 java程序,它并不需要在服务器上启动相应的服务,甚至可以在本地run Hive => MapReduce Hive 操作MapReduce(底层是 MapReduce) Spark SQL=> Spar
-
 度小满JAVA后开实习面经
度小满JAVA后开实习面经视频面 2.15 , 16:00, 45min 1. 自我介绍 2. 简单的聊了一下项目 3. 递归的一些特点 递归的两个重要时间点,前序和后序,前序多用于回溯,后序多用于动态规划,递归的出口; 4. HTTP , TCP ,Socket之间的关系 HTTP是应用层协议,使用了传输层协议TCP来保障数据报文能够传输给对端,TCP使用了Socket来进行网络通信; 5. 端口的作用 主要用于传输层识
-
 滴滴日常实习后开一面
滴滴日常实习后开一面项目 1.微服务按照什么思想拆分的 2.什么叫做微服务,高并发解决的是什么问题,高并发的瓶颈在哪里 3.模块间使用同一台数据库实际上并不能提高并发,如何提高数据库的一个并发量。 4.消息队列的使用 数据库 5.如何实现主从数据库同步的 6.联合索引,最左前缀匹配原则 7.如果你自己设计一个类似Redis的缓存系统,你会考虑哪些问题(先整体设计,再设计细节) 8.Redis常用的数据类型以及他们的应