《数据开发工程师》专题
-
开发命令行工具 - 完善工具
在前面的章节中,已经介绍了如何通过request请求有道词典的接口、使用colors给命令行工具添加颜色等。毕竟那些都是组成我们这个工具的一些部分内容,现在我们需要的是如何将之前学习到的内容组成一个完整的工具。 获取参数 在第一节中介绍了TJ的commander.js工具,不过由于node-translator并不需要获取很多参数,所以完全可以直接获取命令行中的参数。 查阅Node.js的文档后,
-
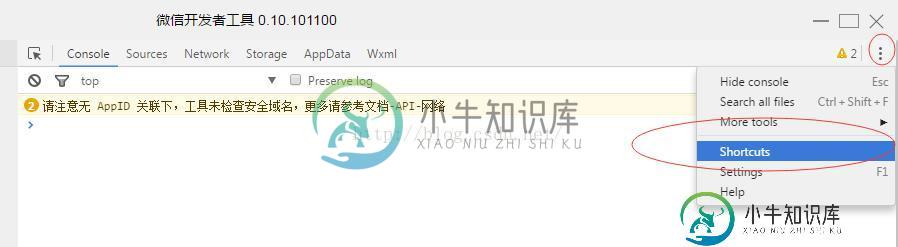 微信小程序 开发工具快捷键整理
微信小程序 开发工具快捷键整理本文向大家介绍微信小程序 开发工具快捷键整理,包括了微信小程序 开发工具快捷键整理的使用技巧和注意事项,需要的朋友参考一下 微信小程序 微信开发者工具 快捷键,最近学习研究微信小程序,用了不少快捷键,索性记录下来,后续如果有其它的快捷键继续增加, 微信小程序已经跑起来了.快捷键设置找了好久没找到,完全凭感觉.图贴出来.大家看看. 我现在用的是0.10.101100的版本,后续版本更新快捷键也应该不
-
Android开发自学笔记(二):工程文件剖析
本文向大家介绍Android开发自学笔记(二):工程文件剖析,包括了Android开发自学笔记(二):工程文件剖析的使用技巧和注意事项,需要的朋友参考一下 无论使用何种IDE开发Android,集成官方Android SDK并创建Android工程之后,该工程都会默认包括一整套Android项目文件,这个工程都可以直接run在你的真机或者模拟器上。 本文主要简单剖析这个默认的完整的一套项目工程的文
-
开发工具的使用 - Chrome Dev Tool使用教程
得益于Google V8的快速,和对HTML5和CSS3的支持也算比较完善,HTML类的富客户端应用在Chrome上无论是流畅性还是呈现的效果,都是比较出色的,这对于开发者,特别是对于那些喜欢研究前沿技术的前端开发者来说,是很重要的。 对于本文,作为一个Web开发人员,除了上面的原因以外,与我们开发相关的,就是Chrome的开发者工具。而本文,就是要详细说说Chrome的开发者工具,说说我为什么认
-
 上海柏楚电子科技C++开发工程9.29
上海柏楚电子科技C++开发工程9.29图形研发工程师?我都忘了投的什么了 8道题,没有IDE,代码题也是写纸上上传 图形题 层序遍历,中序遍历,求后序 图形题 不重复N个数找K个最大的,K很小?K很大?写出算法思路、空间复杂度、时间复杂度? 不相邻的数 和最大(dp思路和代码) 五位密码?(考智力?) 圆与多边形位置关系(思路+伪代码) 严格递增再严格递减数组,二分法找最大值代码。
-
 星环科技 数据产品工程师 (凉经)
星环科技 数据产品工程师 (凉经)9.2 一面 18min 自我介绍 介绍下做过的项目 科研经历 反问 。。。无了 都没专业问题 听着像是搞实施,写文档,还得出差驻场那种 --------------- 9.14 收到 9.19二面通知 9.19 二面 50min 自我介绍 项目介绍 数仓分层概念 拉链表具体细节?更新数据得方式? #秋招#
-
 联想 - 数据分析工程师一面面经
联想 - 数据分析工程师一面面经8月31日一面,两位面试官,2V1,时长约1小时,两位面试官都很温和,整体的面试体验感觉很好,面试氛围超好 自我介绍 针对所修专业开始提问 你的专业做数据分析相比于统计学/数学有什么特殊之处? 你的专业做数据分析有什么优势? 介绍其中一段实习经历 实习中使用到的一个预测模型处理的数据大约有多少条记录?时间跨度有多长?用的训练集占多少? 对于这个项目,当时是怎么分工的? 有遇到什么问题,是怎么解决的
-
 三一重能提前批 大数据工程师
三一重能提前批 大数据工程师写个面经,至今唯一的面试,攒攒人品,正式批还没有收到面试,大家一起加油吧! 8.28 一面 22min 多面app 第一次面试 面试官很好,一直用“您”,迟到了5分钟一上来道歉 1.自我介绍 2min 2.问实习和项目,选出一个影响最深的,说出原因及得到了什么样的结果 3. 开放性问题 1.作为大数据工程师应当在整个公司中发挥什么样的职责 2.模拟场景 ,在制造业下大数据拥有什么样
-
 tplink 大数据分析工程师 春招面经
tplink 大数据分析工程师 春招面经- 3/9笔试 - 选择题大概三四十个 - 问答题10个,涉及python,HSFS八股,Java八股 - 3/14一面,全是快问快答25min - 问简历,项目介绍,项目中提到的模型被揪出来问了细节 - 常见的机器学习算法讲讲,深度学习会多少呢? - 编程语言?希望会Java - 各种排序算法,时间复杂度,随便介绍几个呗 - Python的装饰器 - 指针和引用的区别(这是C++,但是当时并不知
-
 民生银行秋招数据工程师(凉经)
民生银行秋招数据工程师(凉经)参加数据工程赛道竞赛 终面:(20min) 1.自我介绍 2.技术类: 过拟合与欠拟合 监督学习与无监督学习 3.项目类: 自选项目介绍 数据治理项目问是否从数据源开始治理 RFM模型车主生态价值的指标选取
-
 比亚迪大数据技术工程师一面
比亚迪大数据技术工程师一面电话技术面,业务部门直接打电话,看到很少有牛友发这个岗位所以记录一下。 大概十五分钟左右,也可能是我答的不好所以问题比较少。 1.自我介绍 2.hadoop生态 3.hdfs读写 4.spark运行机制 5.hive内外表区别 6.常用编程语言 7.反问 面试官人很好的,我最先开始没接到电话,给我打了好几次,不太清楚的问题也没有过多为难。不过太久不面好多都忘记了,答的并不全面估计凉了。
-
 京东数据应用工程师一二三面
京东数据应用工程师一二三面timeline: 8.27一面(当晚发二面)---8.28二面(结束发三面)---8.30三面 一面-hr面 语速较慢,和蔼 1.工作内容和想象的不一样怎么办 2.评价其余互联网企业(大概是) 3.base地选择 二面-业务主管面 语速正常,专业性强,深挖项目 1.项目模型 2.机器学习八股简单问了问 3.业务题(感觉答得有点乱,面试官帮我梳理了夸我答的还不错) 三面-大leader面 超级专业
-
 三一重工(Java开发)-10.5
三一重工(Java开发)-10.51、自我介绍。 2、应该是看简历提问,谈谈对微服务的理解。 3、项目中,自己具体负责的哪些模块。 4、熟悉哪些设计模式。 5、垃圾回收机制的理解。 6、项目中遇到的哪些问题?具体解决方式。 7、反问环节。问啥啥也不知道! 全程15分钟,网上说offer都发的满天飞了,早超了!随缘! #三一重工##Java开发#
-
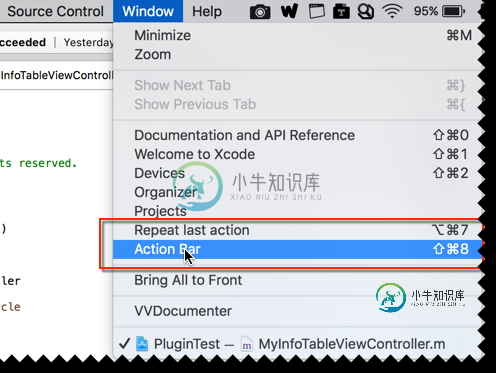 浅谈Xcode 开发工具 XCActionBar
浅谈Xcode 开发工具 XCActionBar本文向大家介绍浅谈Xcode 开发工具 XCActionBar,包括了浅谈Xcode 开发工具 XCActionBar的使用技巧和注意事项,需要的朋友参考一下 XCActionBar 是一个用于 Xcoded 的通用生产工具。 下载地址:https://github.com/pdcgomes/XCActionBar 基本命令: (1)「command+shift+8」或者双击「command」键可
-
设置工具“开发”要求
TL;DR:在运行? 我正在使用setupols构建我的第一个python包。我将要求指定为: 在开发过程中,我一直在安装软件包(在虚拟环境中),其中包括: 和卸载: 这个包使用entry_points来安装一些命令行脚本,所以这为我设置了命令,并允许我在测试命令的同时编辑这个包。 我还有一些用于开发的依赖项。。。sphinx扩展和其他一些东西(使用包不需要的东西)。我现在只是在虚拟环境中手动安装