《数据开发工程师》专题
-
 【京东零售3面已开奖】数据开发工程师
【京东零售3面已开奖】数据开发工程师10.1 -1面:面试官在家,聊的很开心,后边几乎都是我在说自己做了什么,感觉很尊重人 10.11 -2面:面试官很亲切,一开始想电话面,然后问我在哪,我说在面试平台上,又改到了平台面(很尊重了。期间问了各大组件各大知识,加一些场景比如下游不支持事务和幂等,怎么来做精准一次,就是会问一些没有答案的问题,然后根据你的答案提出问题,直到不会。(名场面:你遇到OOM吗;我遇到过;那你谈谈什么时候遇到OO
-
 【龙湖科技已开奖】数据平台开发工程师
【龙湖科技已开奖】数据平台开发工程师1面:问了大数据平台知识 2面:聊天30分钟 3面:聊天13分钟 开奖应该是白菜32-28#2023秋招offer#
-
 海信 大数据开发工程师(一面凉经)
海信 大数据开发工程师(一面凉经)今天早上刚洗漱完,托舍友的福十点才刚准备出寝室门,突然一个电话打进来,说是海信的想给我进行简短的电话面试,我寻思这种面试会问什么问题随即应允。但没想到会把我问成这样...... 开局问我自己本科和研究生都学了些什么,然后不依不饶的追问我研究生学了什么?接着问我在实习期间做的数仓的底层架构和数仓设计,问从后端到前端的数据流程,问存储介质是什么,接着问数据是怎么流转的一连串问题让我难以招架;之后问我在
-
 中科曙光大数据开发工程师一面
中科曙光大数据开发工程师一面1、计算机网络: (1) TCP的三次握手和挥手 (2)OSI7层模型,每层分别有什么作用 (3)对哪个层的了解比较多一些,平时用得最多是哪一层 (4)传输层的协议有哪些 (5)是否对ip协议有了解,ip协议的分类等 2、数据结构 (1)数据结构的分类 (2)红黑树、平衡二叉树查找的过程、原理 (3)hash,hash冲突,解决hash冲突时单链表长度过长的问题 (4)大小堆 3、算法 (1)堆排
-
 德拓-外包面试-大数据开发工程师
德拓-外包面试-大数据开发工程师1.自我介绍 2.数据采集相关,怎么把kafka中的数据采集到mysql中? 忘了 3.hive,两张表的重复数据,怎么去重? 回答distinct,group by ,开窗取第一条, 开窗函数是哪个? 没回答上来 4.udf函数写过吗,flink消费kafka中的数据写过代码吗,需要看代码? 5.使用java干过那些代码? 面试时长:10分钟,面试效果,差 不足:对于简历上的内容,回答支支吾吾,
-
 美团大数据开发工程师-转正实习
美团大数据开发工程师-转正实习发帖求好运 部门:基础研发平台-数据科学与平台部 --------- 一面:57min 1.自我介绍; 2.讲最熟悉的项目; 3.爬虫遇到的问题,如何处理的呢; 4.mysql:left join \ right join \ full join,用一个案例讲一下; 5.数据仓库了解吗; 6.Hashmap的原理了解吗; 7.Hadoop了解吗; 8.NameNode了解吗; 9.HDFS为什么安
-
 凉经 24届 tx 软件开发-数据工程
凉经 24届 tx 软件开发-数据工程摘要 数据工程的全流程(数仓建设-数据接入-数据运维-数据分析-数据挖掘)的各个阶段都有涉及... 自我介绍,问了我在百度和蔚来做的工作(数仓),对简历项目中对数据倾斜的发现、解决方法和效果 回答是通过sparkUi中task的输入量和运行时间发现,解决方法是用count估算不同维度下各value的数据条目,然后数量最多的top key进行再赋值后与其他表join 感觉这个地方可以从spark运行
-
 腾讯 软件开发-数据工程 是KPI吗?
腾讯 软件开发-数据工程 是KPI吗?不知道是不是KPI,感觉这个过程也有点奇妙。 刚从腾讯云智回来,9月底的时候,突然就邀请我面试了?!没有打电话问时间。而且最重要的是,我不符合他的岗位要求呀,我不会大数据的东西呀,简历上也没写,结果他突然捞我了。那时候我就已经开始担心是不是KPI。 不过我那时候才刚回校太累了,就延期,好家伙结果面试官直接给延期到国庆后。 然后面试那天,面试官提前15分钟进入会议。我那时候本来在等时间到,结果会议突
-
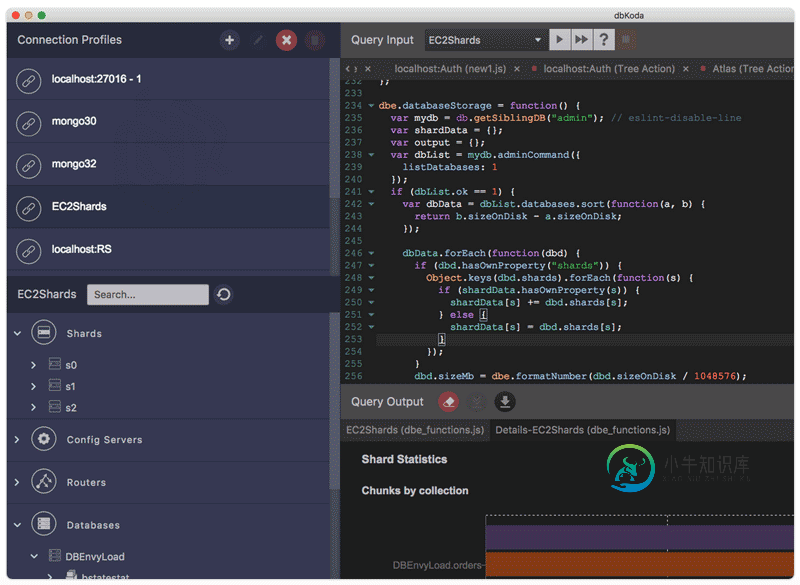 MongoDB开源数据库开发工具dbKoda
MongoDB开源数据库开发工具dbKoda本文向大家介绍MongoDB开源数据库开发工具dbKoda,包括了MongoDB开源数据库开发工具dbKoda的使用技巧和注意事项,需要的朋友参考一下 Southbank Software公司最近发布了 dbKoda 0.6.0 ,这是该软件的 首个发布版 。dbKoda是一款开源的 MongoDB 开发工具,采用JavaScript、 React 和 Electron 开发。下图显示了dbKod
-
 神策数据-后端开发工程师 3面面经
神策数据-后端开发工程师 3面面经一面 8.30 50min 1.java常用的容器,数组和链表区别?hashmap,put的过程 2.解决hash冲突的方式?(开放定址法(线性探测法、平方探测法前后寻找)、链地址法、建立公共溢出区) 3.上面解决hash冲突引出了threadlocal,threadlocal为什么需要要用弱引用?(把源码从头到尾讲了一遍,面试官说理解的不错) 4.AQS用过吗?提供哪些接口? 5.TCP、Ip
-
 oppo 数据开发工程师 1 2 3面 已意向
oppo 数据开发工程师 1 2 3面 已意向一面 8.9 30min 自我介绍 职业规划 维度建模方法有哪些 数仓理解 hive有哪些复合数据类型 hive与关型数据库有什么区别 hive数据倾斜 kafka高吞吐 flume有哪些类型的channel,如何选择 大规模用户下,实际业务进行中会有哪些难点,需要怎么解决 反问 面试官人挺nice,问的问题都耐心解释了 综合面 8.11 20min 没问技术,主要太菜了,跟hr面有点像 hr面
-
 京东 数据开发工程师 一面面经 已凉
京东 数据开发工程师 一面面经 已凉40min 面试官问的很细,来自数据平台,技术感觉很强很全面。 warm-up 自我介绍 有其他意向吗?能来北京吗 挑一个做得好的项目介绍下全流程 难点在哪,讲一下 ElasticSearch ES有用到集群吗?有设置分片吗?有设置副本吗?副本数是多少? 你是怎么建立索引的?为什么这么建立索引? Hive 离线处理有用过Spark 吗?没有,主要用的是Hive 说一下Hive 构造UDF 的过程?
-
 网易云音乐 大数据开发工程师 1面
网易云音乐 大数据开发工程师 1面30min 1. 自我介绍 2. 为什么走大数据 3. 项目介绍 4. hive和spark的区别 5. MR和spark有哪些区别,分别适用什么场景 6. 为什么不选择spark做离线 7. 开窗函数有哪些 8. 数仓怎么设计的 9. ODS层存在的意义 10. DWD和DIM怎么设计的,有什么指标 11. DWS层存放的哪些指标 12. 下一步准备学习什么?怎么学习? 反问 1. 部门做什么业
-
 多益网络 —— 大数据开发工程师 —— HR面挂
多益网络 —— 大数据开发工程师 —— HR面挂HR面感觉挺好的不知道咋挂了 1、自我介绍 2、如何看待实习和学校学习 3、期望薪资 (感觉是这个问题,我答的是:该岗位一般是10k-15k,所以我觉得不能少于10k) 3、为什么来广州,为什么不在武汉找工作 4、手里有Offer 吗,不满意的点,(我答的薪资和公司文化) 5、抽取的问卷题,物业不让养狗,怎么看 今天看到消息,挂掉了,没搞懂为何挂了,自我感觉答得还不错,也不紧张 心里还好没有多大落
-
 58同城大数据开发工程师面经(一面)
58同城大数据开发工程师面经(一面)开局自我介绍,然后问我两段实习经历,分别做了什么?照实回答,问我有没有接触过BI工具,我说是内部封装好的;日常工作,处理的数仓规模,人员规模,主要负责内容,处理的数据的大小。之后让我写一道题目,求连续三天消费金额大于100的用户ID,不想用排序函数再写了所以用了LAG函数来写,面试官给了我一个不置可否的表情(坏了可能写错了......)然后说我明白你的思路了,我解释说因为不想用排序函数来写所以尝试