《大数据开发实习》专题
-
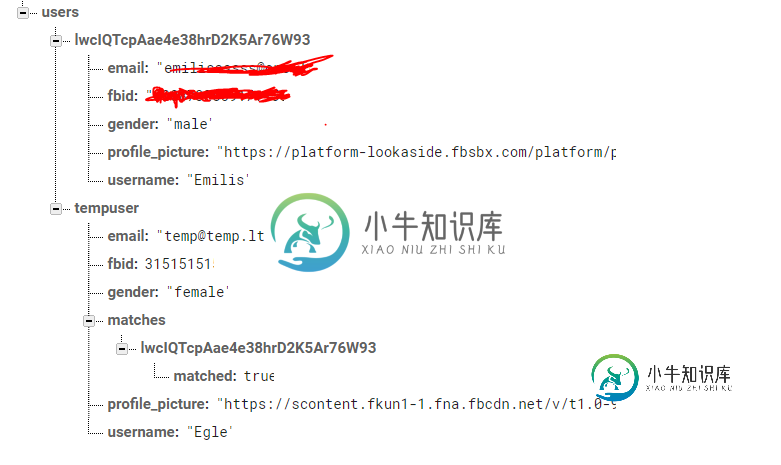 Firebase实时数据库过滤数据
Firebase实时数据库过滤数据所以我正在制作约会应用程序,现在我需要为用户创建一个匹配的人员列表。 因此,我需要一个firebase查询来查看性别,并检查是否已经匹配,如果匹配,则不应将其包括在列表中。 我试着按性别过滤数据。如何编辑此查询以检查它们是否已匹配?匹配项显示在用户/{userID}/Matches/{matchedUserID}中 这是我尝试的:
-
python获取一组数据里最大值max函数用法实例
本文向大家介绍python获取一组数据里最大值max函数用法实例,包括了python获取一组数据里最大值max函数用法实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python获取一组数据里最大值max函数用法。分享给大家供大家参考。具体如下: 希望本文所述对大家的Python程序设计有所帮助。
-
javascript实现动态统计图开发实例
本文向大家介绍javascript实现动态统计图开发实例,包括了javascript实现动态统计图开发实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了javascript实现动态统计图的代码。分享给大家供大家参考。具体如下: 运行效果截图如下: 具体代码如下 html代码: css代码: js代码: 希望本文所述对大家学习javascript程序设计有所帮助。
-
实战篇 - 实战:Web 应用开发入门
rust既然是系统级的编程语言,所以当然也能用来开发 web,不过想我这样凡夫俗子,肯定不能从头自己写一个 web 服务器,肯定要依赖已经存在的 rust web开发框架来完成 web 开发。 rust目前比较有名的框架是iron和nickel,我们两个都写一下简单的使用教程。 iron 接上一篇,使用cargo获取第三方库。cargo new mysite --bin 在cargo.toml中添
-
开发
源码目录结构 构建系统概览 构建步骤(Windows) 在调试中使用 Symbol Server
-
开发
错误分析
-
开发
Developing Electron Electron 和 NW.js (原名 node-webkit) 在技术上的差异 Updating an Appveyor Azure Image Build Instructions 构建步骤(Linux) 构建步骤(macOS) 构建步骤(Windows) 构建系统概览 Chromium 开发 在 C++ 代码中使用 clang-format 工具 代
-
开发
开始开发环境设置 在你使用 yarn 或 npm install 安装了依赖之后, 运行... yarn run dev # 或者 npm run dev ...然后 轰! 现在,你就在运行一个 electron-vue 应用程序. 此样板代码附带了几个易于移除的登录页面组件。
-
开发
Core Concepts 获取 Kubernets 所有对象 $ kubectl api-resources --sort-by=name -o name | wc -l 67 $ kubectl api-resources --sort-by=name -o name apiservices.apiregistration.k8s.io bgpconfigurations.crd.proje
-
开发
三节点复制集 mkdir -p ~/data/r{0,1,2} for i in 0 1 2 ; do mongod --dbpath ~/data/r$i --logpath ~/data/r$i/mongo.log --port 2700$i --bind_ip 0.0.0.0 --fork --replSet repl ; done mongo --port 27000 --eval 'r
-
开发
开发 git clone https://github.com/weui/weui.git cd weui npm install npm start 运行npm start命令,会监听src目录下所有文件的变更,并且默认会在8080端口启动服务器,然后在浏览器打开 http://localhost:8080/example。 参与贡献 欢迎参与 WeUI 的贡献,你可以给我们提出意见、建议,报
-
Deeplearning4J-如何为大数据迭代多个数据集?
我正在学习用于构建神经网络的Deeplearning4j(Ver.1.0.0-M1.1)。 我使用Deeplearning4j的IrisClassifier作为一个例子,它工作得很好: 对于我的项目,我输入了大约30000条记录(在iris示例-150中)。每个记录是一个矢量大小~7000(在iris示例-4中)。 显然,我不能在一个数据集中处理整个数据--这将为JVM产生OOM。 如何处理多个数
-
创建具有大量数据的android app数据库
问题内容: 我的应用程序的数据库需要填充大量数据,因此在期间,不仅有一些创建表sql指令,而且还有很多插入。我选择的解决方案是将所有这些指令存储在res / raw中的sql文件中,该文件已加载。 它运作良好,但我面对编码问题,sql文件中有一些突出的字符,在我的应用程序中看起来很糟。这是我的代码来做到这一点: 我发现避免这种情况的解决方案是从一个巨大的而不是文件中加载sql指令,并且所有突出的字
-
在Spark中处理大量数据框/数据集/RDD
好吧,我对使用Scala/Spark还比较陌生,我想知道是否有一种设计模式可以在流媒体应用程序中使用大量数据帧(几个100k)? 在我的示例中,我有一个SparkStreaming应用程序,其消息负载类似于: 因此,当用户id为123的消息传入时,我需要使用特定于相关用户的SparkSQL拉入一些外部数据,并将其本地缓存,然后执行一些额外的计算,然后将新数据持久保存到数据库中。然后对流外传入的每条
-
mysql 如何迁移数据流较大的数据库?
数据库日积月累几个G后,从服务器A导入到服务器B 导入数据库总是失败。内存不足或者直接崩了。 请问有什么方案可以稳定的分段导入吗?