《欢聚时代》专题
-
MongoDB-在聚合中选择组,但不指定字段
抱歉发了这么长的帖子! 我有一个Mongo收藏,包含以下文档: 我想查询这些文档,并返回每个名称的最大值条目,因此我想要的结果集(顺序无关紧要)是: 如果我想在C#中做完全相同的事情,我会使用: 使用聚合管道,我已经达到了: 这给了我以下结果集: 如您所见,我有一个文档数组,每个文档都包含一个“_id”字段(名称)和一个“highest”字段(实际文档)。 这将用C表示为: 我想知道的是,是否可以
-
Spring WebClient聚合多个401 UNAUTHORIZED错误以引发Exceptions.CompositeException
当WebClient使用错误的令牌异步调用外部api(使用不同的查询参数)时,前几个调用返回401 UNAUTHORIZED,控制流因< code >异常而停止。CompositeException。我们在< code>WebClient实例中添加了如下过滤器,用于检查4xx和5xx响应状态代码,以抛出自定义异常 现在的问题是,当第一次调用返回错误(401)时,不会被抛出,而是聚合了一堆调用并抛出
-
聚合一个点中具有相同坐标的点
我有一个关于R中空间聚合的问题。我的数据集有纬度/经度坐标,有些彼此接近,有些不接近。我想为彼此接近的纬度/经度坐标做一个点。 我不确定如何做到这一点。我是否将纬度/经度坐标作为组列出,并使求平均值以使一个点表示每个组?因为我对这类事情没什么经验。我希望你们中的任何人可能有一些有用的指导/可能的解决方案。 例如,如果我可以将下面的纬度/经度坐标设为一个点: 例如,如下所示,不影响时间和速度值:
-
通过selenium javascriptExecutor访问影子DOM元素(聚合物)
正在尝试访问中男式外饰部分下的“立即购买”按钮https://shop.polymer-project.org/在chrome浏览器(V51)的JS控制台上使用以下代码: 我试图在我的自动化测试中访问相同的元素,使用selenium,第1行:
-
使用MongoDB聚合按多个字段进行计数
本文向大家介绍使用MongoDB聚合按多个字段进行计数,包括了使用MongoDB聚合按多个字段进行计数的使用技巧和注意事项,需要的朋友参考一下 要按多个字段计数,请在MongoDB中使用$facet。在$facet处理在同一组输入文档的单级中的多个聚集的管道。让我们创建一个包含文档的集合- 在find()方法的帮助下显示集合中的所有文档- 这将产生以下输出- 以下是要按多个字段计数的查询- 这将产
-
在purescript中创建后自动聚焦输入元素
我正在使用purescript卤素构建一个类似电子表格的表格(类似于Handsontable)。如果双击某个单元格,则html输入元素将作为相应表格单元格的子元素呈现(并且不会为所有其他单元格呈现此类元素)。 这对卤素非常有效,除了我不知道如何自动将焦点设置为新创建的输入元素。 我尝试了属性,但这只适用于双击的第一个单元格。JavaScript的方法是在新元素上调用方法,但是我不知道在DOM以卤素
-
PostgreSQL-GROUP BY子句或在聚合函数中使用
问题内容: 我在SO上找到了一些主题,但是仍然找不到适合我的查询的设置。 这是查询,在本地主机上运行得很好: 但是在Heroku上,我 遇到了-GROUP BY子句 上面的错误, 或者在聚合函数中使用 。 然后,我在某处读到,我应该指定表中的所有列,因此我尝试了以下操作: 但这在本地主机上不起作用,在Heroku上也不行… 什么是查询的正确配置? 问题答案: 我认为您正在尝试在同一列上进行汇总和分
-
使用GROUP BY选择多个(非聚合函数)列
问题内容: 我试图从一个列中选择最大值,同时按具有多个重复值的另一个非唯一id列进行分组。原始数据库如下所示: 使用以下方法可以很好地工作: 它返回一个像这样的表: 我希望能够在不影响GROUP BY函数的情况下添加其他列,以将诸如name和type之类的列包括到输出表中,例如: 但是它总是输出一个错误,说我需要在select语句中使用聚合函数。我应该怎么做呢? 问题答案: 您遇到了每组最多的问题
-
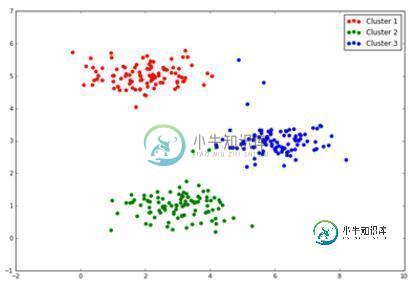 Python机器学习之K-Means聚类实现详解
Python机器学习之K-Means聚类实现详解本文向大家介绍Python机器学习之K-Means聚类实现详解,包括了Python机器学习之K-Means聚类实现详解的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大
-
Spring integration kafka入站适配器聚合传入消息
我有一个,我使用它向kafka发送消息,然后使用接收消息。通信似乎工作正常,我能够发送和接收消息,但格式有点奇怪。我单独向我的出站适配器发送单个消息,但当我收到消息时,我会收到一条消息,所有消息都聚合到该消息的有效负载中。 这就是我收到消息时消息负载的样子 [有效负载={mytopic={0=[字符串消息1,字符串消息2,字符串消息3,字符串消息4,字符串消息5,…]}},标头={id=3934d
-
Spring集成-拆分后发布订阅通道聚合
我有一个基于DSL的流,它使用拆分迭代对象列表并发送Kafka消息: 在所有消息发出后,我需要调用服务,还需要记录处理了多少消息。我知道一种方法是使用publishSubscribeChannel,其中第一个subscribe执行实际的Kafka发送,然后聚合执行服务调用: 我在弄清楚如何使用DSL在pubSubChannel中实际执行部分时遇到了问题。到目前为止,我已经尝试过: 有什么指示吗?
-
如何在$addFields上获得聚合-$组计数结果?
我有以下疑问。 ]) 这是查询的结果。 输出1 我将得到一个$组结果。我将使用$array1。 输出 “计数”结果将复制到所有结果上。 但是$组将创建一个糟糕的结构来读取所有数据。 如何将所有OUTPUT1与OUTPUT2的$组“count”合并? 使用$组“count”,但我不想要$组结构。
-
使用Pipeline进行MongoDB聚合查找不起作用
我有两个集合。如果集合2中的1号和2号在集合1中指定的一定范围内,我正在尝试将集合2的文档添加到集合1中。集合1中的FYI ObjectId和集合2中的ObjectId指的是两个不同的项目/产品,因此我无法在此id上加入两个集合。 集合1中的示例文档: 集合2中的示例文档: 我想要输出: 我认为使用管道的查找阶段可以工作。我的代码当前如下: 但是运行上面的没有给我输出。我做错了什么吗??
-
如何使用mongodb聚合和检索整个文档
我对mongoDB的聚合函数感到非常困惑。我只想在我的收藏中找到最新的文档。假设每个记录都有一个“创建”的字段 产生正确的结果,但我希望结果中包含整个文档?我将如何做到这一点? 这是文档的结构:
-
聚合查询返回mongodb所有对象的数组
我第一次使用mongo。我正在尝试使用下面的查询聚合集合中的一些文档。相反,查询返回一个具有键“result”的对象,该键包含一个包含符合$match的所有文档的数组。 下面是查询。 以下是集合中的示例文档: 我正在尝试将所有内容按uid进行分组,每个组的总和。。。实现这一目标的正确方法是什么?