《欢聚时代》专题
-
是Spring集成聚合器单线程执行
我在应用程序中使用拆分器聚合器模式。我有以下配置- 我的所有通道(CH1、CH2、CH3)都是。Splitter输入通道CH1的源代码是一个文件。 在我的测试中,我观察到即使在CH1通道中添加两个文件,在给定时间也只有一个文件被处理。所以我在我的CH1通道中添加了一个轮询器,现在正在同时处理CH1通道上的多个输入消息。 在聚合器方面,我也注意到执行总是单线程的,即直到第一个线程完成执行,第二个线程
-
从聚合中重新格式化MongoDB结果
我来自SQL世界,从MongoDB开始,我仍然有点困惑。。。我有一个这样的收藏 还有我的问题, 我正在使用角和NodejS Express从数据库中获取数据,我以这种格式获取数据 因此,我想知道是否有一种方法可以在没有id键的情况下获得此查询结果, 像这样:
-
Cassandra中的用户定义函数和聚合
我正在测试Cassandra中的UDF/UDA特性,看起来不错。但我在使用它时没有什么问题。 1) 在卡桑德拉。yaml,有人提到启用沙箱是为了避免邪恶代码,那么我们是否违反了规则,启用此支持(标志)会产生什么后果? 2)与在客户端读取数据和编写聚合逻辑相比,在Cassandra中使用UDF/UDA有什么优势? 3)此外,除了JAVA之外,是否有一种语言支持可用于编写UDF/UDA的nodejs、
-
JavaFX:以编程方式聚焦文本字段
我用JavaFX编写了一个应用程序,它只能用于键盘的箭头。所以我在现场的舞台上阻止了MouseeEvent,我“倾听”关键事件。我还关闭了所有节点的聚焦: 现在我有了一些文本字段、复选框和按钮。我想更改输入控件的状态(文本字段,复选框,…)编程:例如,我想输入文本字段以编程方式编辑内容。所以我的问题是:如何输入非焦点可遍历的文本字段?因为textfield。requestFocus();自从我将f
-
MongoDB 中聚合统计计算--$SUM表达式
本文向大家介绍MongoDB 中聚合统计计算--$SUM表达式,包括了MongoDB 中聚合统计计算--$SUM表达式的使用技巧和注意事项,需要的朋友参考一下 我们一般通过表达式$sum来计算总和。因为MongoDB的文档有数组字段,所以可以简单的将计算总和分成两种: 1,统计符合条件的所有文档的某个字段的总和; 2,统计每个文档的数组字段里面的各个数据值的和。这两种情况都可以通过$sum表达式来
-
JAVA mongodb 聚合几种查询方式详解
本文向大家介绍JAVA mongodb 聚合几种查询方式详解,包括了JAVA mongodb 聚合几种查询方式详解的使用技巧和注意事项,需要的朋友参考一下 一、BasicDBObject 整个聚合查询是统计用户的各种状态下的用户数量为场景: 1.筛选条件: date为查询日期: 如果有多个条件:直接加Query.put("status", 0); 如果有OR筛选: 其中 new BasicDBOb
-
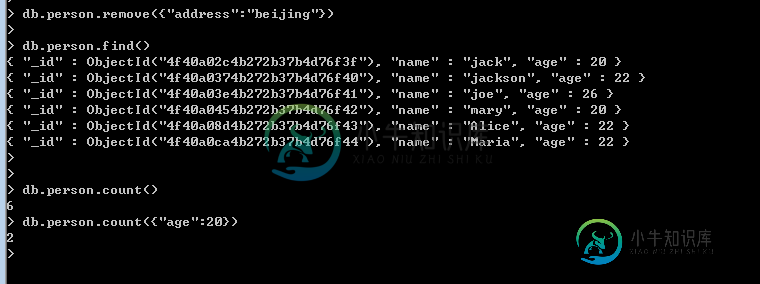 mongodb聚合_动力节点Java学院整理
mongodb聚合_动力节点Java学院整理本文向大家介绍mongodb聚合_动力节点Java学院整理,包括了mongodb聚合_动力节点Java学院整理的使用技巧和注意事项,需要的朋友参考一下 今天跟大家分享一下mongodb中比较好玩的知识,主要包括:聚合,游标。 一:聚合 常见的聚合操作跟sql server一样,有:count,distinct,group,mapReduce。 <1> count count是最简单,最容易,也是最
-
SQL Server中多个列上的聚合函数
问题内容: 我在#temp表中具有以下数据: 我想做以下操作,即 一行将在两列上加法,即 另一行将在三列上减法加法,即 我曾尝试在SQL Server中使用case语句。 以下是所需的输出 哪里& 我曾尝试使用SQL SERVER Case语句,但未获得正确的输出 问题答案: 我看到至少有两种方法可以得到这些结果。分组或枢纽 在下面的示例中,显示了2种方法。 请注意,使用的是SUM(VALUE)而
-
公用表表达式内的反向聚合
问题内容: 我本来希望以下查询返回所有带有各自子代的人。 但是实际上,它的确是相反的。我想不出无需额外的CTE就能进行正确嵌套的方法。有办法吗? 示例数据 结果 预期结果 问题答案: 该rCTE从另一侧遍历树: SQL提琴。 使用到每个节点聚集多个分支外。 与您期望的结果之间的微小差异: 这包括在列中。 没有将单个节点包装到数组中。 都可以进行调整,但是我希望结果对您来说是可以的。
-
选择聚合函数和所有其他列
问题内容: 如何以方便的方式选择表中的所有列和聚合函数? 也就是说,我有一个包含100列的表格,我想发送以下内容 谢谢! 问题答案: 要从表中选择所有列,请执行以下操作: 要从表中选择一个最大值是 两者结合: 如果要在结果行中省略column44并且仅具有maxcol44,则必须列出这些列:
-
具有聚合函数的Hibernate命名查询
我试图在Hibernate中执行命名查询。查询在此映射文件中定义: MxePosition类如下: 我试图做的是让命名查询返回由另一列分组的一列的总和。然而,Hibernate抛出了一个错误,我怀疑这是因为查询结果不包含ID列。 有办法吗?必须能够在Hibernate中执行包含GROUP BY子句的查询,而不在结果中包含ID。 如果有更好的方法,我愿意接受其他不使用命名查询的建议。
-
如何使用特性聚合akka-http路由?
我试图在运行时使用一个特性聚合路由,到目前为止 显然,上面的代码不起作用,因为项目列表不能传递给。 所以我的问题是,如何将解析为接受,或者如何从的子类动态加载路由?
-
配置单元引发聚合函数错误
当我尝试使用Hive执行非聚合命令时,查询似乎可以正常工作,如下所示: 从Airlines_Analysis.Airline中选择*;从Airlines_Analysis.Airline中选择Airlines.Month; org.apache.hive.service.cli.hivesqlexception:处理语句时出错:失败:执行错误,从org.apache.hive.service.cl
-
使用弹性搜索聚类的Bing地图
有没有办法将弹性搜索GeoHash转换为具有适当缩放级别的bing地图图钉? https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-geohashgrid-aggregation.html
-
ElasticSearch-聚合/分组依据:排序和分页
我正在尝试使用Elasticsearch(2.4)聚合对使用该查询的多个索引按“productId”分组 1) 我想按分数排序,所以我尝试使用 哪个返回 2) 此外,我正在尝试使用分页,“size”键实际起作用,但“from”键不起作用 **更新-聚合结果示例** 希望有人能帮忙