《欢聚时代》专题
-
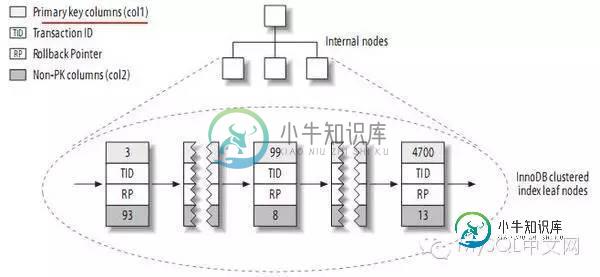 MySQL索引之聚集索引介绍
MySQL索引之聚集索引介绍本文向大家介绍MySQL索引之聚集索引介绍,包括了MySQL索引之聚集索引介绍的使用技巧和注意事项,需要的朋友参考一下 在MySQL里,聚集索引和非聚集索引分别是什么意思,有什么区别? 在MySQL中,InnoDB引擎表是(聚集)索引组织表(clustered index organize table),而MyISAM引擎表则是堆组织表(heap organize table)。 也有人把聚集索引
-
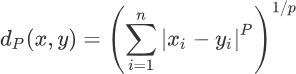 K-means聚类算法原理解析
K-means聚类算法原理解析主要内容:度量最小距离,总结通过《 什么是Kmeans聚类算法》一节的学习,我们了解了 K-means 聚类算法的聚类过程,其实就是不断寻找簇的质心的过程,该过程从随机设定 K 个质心开始,直到找到 K 个最合适的质心为止。本节我们透过算法流程直击算法的本质,帮助您彻底理解 K-means 算法。 度量最小距离 对于 K-means 聚类算法而言,找到质心是一项既核心又重要的任务,找到质心才可以划分出距离质心最近样本点。从数
-
数组的Java类图组合/聚合
请考虑以下情况: 我如何在类图上表示< code>A和< code>B之间的关系?如果< code>B只保存一个< code>A(而不是一个数组),我会使用组合/聚合,但是在这种情况下,我不确定应该做什么。非常感谢你的帮助!
-
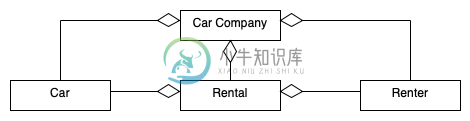 在类图中过度使用聚合?
在类图中过度使用聚合?我试图解决这个问题: 为汽车租赁公司绘制面向对象模型的UML类图,该模型跟踪汽车、租车人和租车人。创建一个UML类图来表示这些信息。显示正确的类和关系就足够了。不要向类添加属性或方法。 我在想租房者和汽车公司应该是协会,汽车公司和租房者应该是组合。然而,所提出的解决方案(此处简化)并不符合我的期望: 该解决方案将所有关系显示为聚合。有人能帮我理解为什么它们都是聚合的,而不是我认为的联想和组合吗?
-
Microsoft Dynamics CRM唯一非聚集索引
我在工作中继承了一个Dynamics CRM系统,运行:Version1612(8.2.2.112)(DB 8.2.2.112)。 我们所处的情况是,重复似乎通过失败的表单提交断断续续地发生,随后又重新提交。我们已经在内部发布了一个文档,解释了这种行为,并表示首先检查部分或全部事务是否真正成功是多么重要。但人类终归是人类,常常忘记... 是否有更好的解决方案,我没有,提供数据库级的一致性,并不妨碍
-
同一类的Java组合和聚合?
假设我们有两个名为Point和Line的类。Line类有两个构造函数。这是Point类的代码。 这是Line类的代码。 如您所见,Line类有两个构造函数。第一个构造函数是组合的例子,而第二个构造函数是集合的例子。现在,关于这个案子我们能说些什么?一个类可以同时有聚合和合成吗?谢谢你的回答。
-
Mongo-具有多个条件的聚合
我收集了用户在商店购买的物品,以及他从朋友那里得到的喜欢和不喜欢的东西。集合字段如下所示: 现在,我想得到以下总结: 获取用户X的(喜欢-不喜欢)差异 获取用户X的差异(喜欢-不喜欢)到存储Y 获取用户X的(喜欢-不喜欢)差异到商店Y和产品Z 对于#1,我做了: 我得到了正确的结果: [{"_id":"542ea90fbb1e37b09f660980","rankDiff": 2}] 但当我试图通
-
Saga,在哪里存储聚合状态
下面是一个简单的场景: 用户单击“Create order”:将创建一个订单(首先保持其状态=NEW) 用户完成订单填写后,单击SAVE-->state is now Submited 当另一个检查订单并验证它时,必须进行一个过程。只有在调用了其他一些服务并给予许可时,才会验证该订单。 整个工作流程是: null null 谢谢
-
 10_4海信聚好看二面(终面)
10_4海信聚好看二面(终面)10_17更新,挂了。。。 一共15min左右,基本没问什么技术,说7个工作日给结果 实习的主要内容 实习的收获 项目 对项目做了哪些改进 科研相关 科研是计算机视觉相关的,为什么投java 有当过班干部之类的没有 有什么爱好 手里有offer吗 #海信##海信面试#
-
 成都数聚智造c++实习面
成都数聚智造c++实习面#我的实习日记##校招资讯##C++面经#虽然是一家小公司,但是面试题目却给我一种耳目一新的感觉,从中收获许多,也许是自己太菜了。现复盘分享给大家,与君共勉。 1:两个int数相加实现,需要考虑什么?如何快速判断溢出?(说用位运算) 2:值为-1的数据在断点调试时,显示的值是多少?在内存中是如何显示的? 3:是否使用过c++模板? 4:vector最大的缺点是什么?使用vector时,从操作系统内
-
使用Turbine和Consul Hystrix指标聚合
Turbine(由Spring Cloud Netflix项目提供))聚合多个实例Hystrix指标流,因此仪表板可以显示聚合视图。Turbine使用DiscoveryClient接口查找相关实例。要将Turbine与Spring Cloud Consul结合使用,请按以下示例配置Turbine应用程序:的pom.xml <dependency> <groupId>org.springfram
-
左连接横向和数组聚合
问题内容: 我正在使用Postgres 9.3。 我有两个表 以及它们之间的关系。现在,我想创建一个视图,该视图除了T1的列外,还为T1中的每个记录提供一列,其中包含一个包含T2所有相关记录的主键ID的数组。如果T2中没有相关条目,则此列的相应字段应包含空值。 我的架构的抽象版本如下所示: 可以如下生成相应的样本数据: 到目前为止,我提出了以下查询: 这行得通。但是,可以简化吗? 可以在此处找到相
-
包中的自定义聚合函数
问题内容: 我正在尝试在Oracle中编写一个自定义聚合函数,并将该函数与其他一些函数一起分组在一个包中。作为一个示例(为了模拟我遇到的问题),假设我的自定义聚合对数字进行求和看起来像: 如果我编写以下函数定义: 和相应的类型声明进行测试: 这个说法: 给出正确的结果70。但是,使用函数定义创建一个包: 并通过以下方式调用: 与爆炸 是否可以在包声明中嵌套自定义聚合函数? 问题答案: Oracle
-
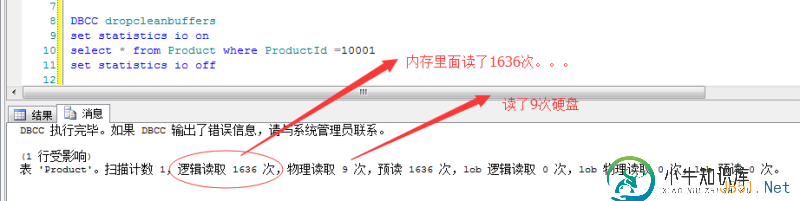 理解Sql Server中的聚集索引
理解Sql Server中的聚集索引本文向大家介绍理解Sql Server中的聚集索引,包括了理解Sql Server中的聚集索引的使用技巧和注意事项,需要的朋友参考一下 说到聚集索引,我想每个码农都明白,但是也有很多像我这样的猥程序员,只能用死记硬背来解决这个问题,什么表中只能建一个聚集索引,然后又扯到了目录查找来帮助读者记忆。。。。问题就在这里,我们不是学文科,,,不需要去死记硬背,,,我们需要的就是能看到在眼里面的真实东西
-
Django Aggregation聚合使用方法解析
本文向大家介绍Django Aggregation聚合使用方法解析,包括了Django Aggregation聚合使用方法解析的使用技巧和注意事项,需要的朋友参考一下 在当今根据需求而不断调整而成的应用程序中,通常不仅需要能依常规的字段,如字母顺序或创建日期,来对项目进行排序,还需要按其他某种动态数据对项目进行排序。Djngo聚合就能满足这些要求。 以下面的Model为例 快速了解 聚合生成Gen