《交友》专题
-
在交换机中捕获混合枚举
在一些遗留代码中,我有很多枚举,和一个巨大的开关案例。我想测试开关是否具有纯枚举类型。胡说八道的例子: 这是错误的做法,编译器可以警告错误的做法或不违反标准的潜在错误,比如总是真的,完全合法,但可能是错误。 如果枚举上的开关不包含该枚举a.S.O的所有值,我可以让编译器发出警告。 它是首选的,如果编译器可以工作,但如果一个工具,如林特或类似的可以做到这一点,我也很高兴。
-
Spring批处理块处理提交频率
如果我正在读写本地文件,那么对远程数据库服务器的更新相对昂贵。如果增加[chunk-size],内存使用量就会上升。 提交频率对编写本地文件并没有太大的影响,所以对我来说,元数据更新才是一个问题。该步骤是可重新启动的,因此从技术上讲,我不需要记录中间提交计数。 对于JobRepository,我可以只使用map或内存数据库,但我需要其他信息,例如持久化的开始/结束时间,而且这个问题只涉及一个步骤。
-
交互通信微服务-如何实现?
我正在进行一个Personal项目,将一个整体的web应用程序转换为微服务(每个服务都有自己的数据库)。 第二个想法是使用RabbitMQ这样的消息代理。“Register Service”仍然在自己的数据库中插入有趣的东西,并以用户信息作为数据在队列中发布消息。“用户服务”使用此消息并将数据持久化到其“用户”数据库中。通过使用这个概念,这两个服务是完全隔离的,这可能是一个很好的想法。 但是,发送
-
从flask中的PostgreSQL函数提交事务
我是Flask和SQLAlchemy的新手(在过去3年中一直与Django合作)。我需要调用一个现有的PostgreSQL函数,该函数可以写入数据库中的3个不同表。这是我无法控制的(我必须让它工作)。该函数返回一条记录(自定义Postgres类型),其中包含有关结果的信息。代码如下: 上面的代码运行时没有错误。从日志消息中,我可以看到正确的数据是从数据库返回的。但是,如果我转到psql,就看不到新
-
如何在JavaFX中交换控制器?InvocationTargetException
FXML1-menu开始: fxml2-rules的开始(第14行的错误是这里的第一行,在此之前,这里只是预先导入):
-
如何交织(合并)两个Java 8流?
我需要做什么才能使输出如下所示? 我查看了concat,但正如javadoc所解释的,它只是一个接一个地附加,而不是交错/穿插。 创建一个延迟连接的流,其元素是第一个流的所有元素,然后是第二个流的所有元素。 错误地给予 如果我收集它们并迭代,可以做到这一点,但希望有更多的Java8-y,Streamy:-) 笔记 我不想让溪流断流 “zip”操作将从每个集合中获取一个元素并将其组合。 zip操作的
-
jQuery提交功能不能正常工作
我对jQuery提交功能有一些疑问。 这里是工作环境 jQuery:1.7。2,铬(18.0.1025.168米)。 有两个问题。 第一: 我的密码是这样的 HTML jQuery 问题是它在firefox和opera中运行良好,但在chrome中运行良好。 2st: html:如上所述。 jQuery: 它在火狐、歌剧和铬合金中不起作用。它总是触发form.submit原因。 我很困惑。谁能弄清
-
段落向量模型的交叉验证
密钥错误:0 我通过将中的替换为或来进行实验。此外,我尝试了对原始输入数据()进行同样的处理,而不是预处理文本。我怀疑用于交叉验证的的格式一定有问题,而用于管道的函数工作得很好。我还注意到与一起工作。 有人发现错误了吗?
-
Spark-提交标准以设置参数值
我对设置以下spark submit参数时使用的正确标准感到非常困惑,例如: 一个人告诉我,我使用了很多遗嘱执行人和核心,但他没有解释他为什么这么说。 有人能向我解释一下根据我的数据集设置这些参数时使用的正确标准吗(--drive-内存4G--执行器-内存4G--num-执行器10--执行器-核心4)? 以下情况相同 我不太确定设置这个参数“spark.sql.shuffle.partitions
-
pyspark spark提交中的Java堆空间OutOfMemoryError?
我的数据集大小为10GB(例如Test.txt)。 我编写了pyspark脚本,如下所示(Test.py): 然后我使用下面的命令执行上面的脚本: 然后我得到如下错误: 请让我知道如何解决这个问题?
-
如果设置了多个提交按钮
不知是否有人能帮助我。 我试图运行下面的代码,我正在使用带有多个的表单。 我的问题是,当我运行这个,我收到以下错误:
-
kafkaProducer在psringboot应用程序中的交易
我想在成功发送关于Kafka主题的所有消息后执行一些代码。我读了很多文章。要知道我们可以使用事务发送消息。 我尝试了这么短的代码,但不确定如何在这个事务成功执行后执行一些代码。我也尝试过Kafka普勒,开始交易,但这对我的案子也不起作用。如果有什么想法的话会很有帮助。
-
Java JVM中的内存交换到磁盘
我使用的是64位Linux和Java JVM。我想确认JVM使用的内存是否小于机器的物理内存大小,操作系统是否不会交换磁盘内存?
-
嵌入式Kafka与真实课堂交流
我有一个Spring Boot应用程序,可以使用和。我有一位制片人。 我想写JUnit上面没有任何嘲弄类。我尝试了,但我不确定如何将其连接到我的应用程序定义的kafka代理,所以当我发送主题消息时,消费者(其中存在)应该选择消息并处理它。 有了我也得到了下面的错误。 有人能告诉我如何在不模仿任何类的情况下为我的Kafka制作人编写Junit,它应该用真实的类进行测试。
-
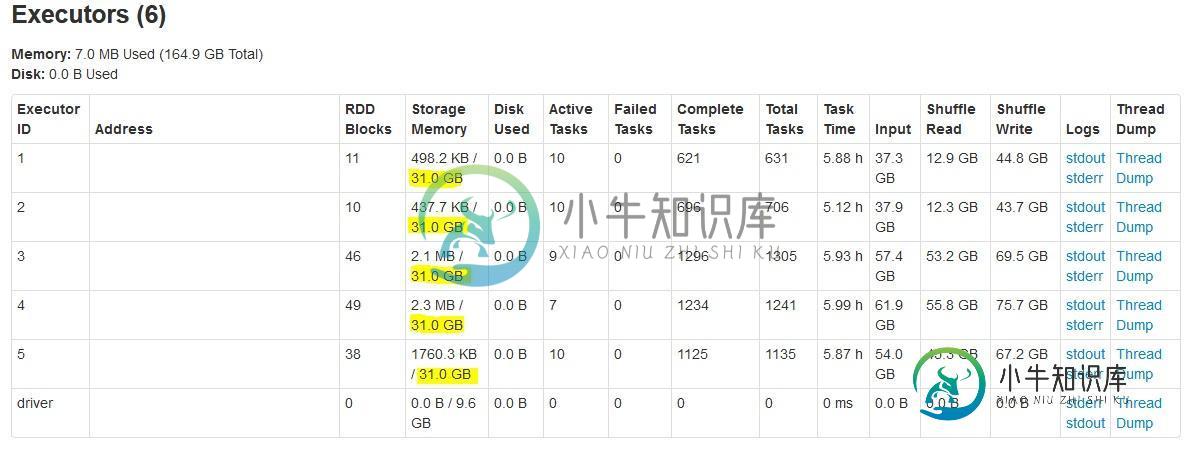 Spark-提交执行程序内存问题
Spark-提交执行程序内存问题1)谁能解释一下为什么显示的是31GB而不是60GB。2)还有助于为上述参数设置最佳值。