《jvm》专题
-
JMX SflowAgent停止从插入aspectj的WebSphere Application Server收集JVM指标
项目: 我使用斯流甘利亚来监控 Websphere 应用程序服务器 (WAS) 的 JVM 指标。WAS 是使用方面J 方面进行检测的。我添加了一个方面来测量所有应用程序方法运行时。 我使用Hsflow d作为JVM指标收集器。Hsflow d在内部使用JMX-Sflow Agent javaagent挂钩到JVM以使用MXBean(RuntimeMXBean、GarbageCollectorMX
-
在RAD Websphere v7.5中,我们可以向“通用JVM参数”添加什么参数来显示GC信息?
在RAD WebSphere中,我想给JVM添加一些参数,以便显示一些关于垃圾收集的信息。我注意到这个操作在< code >管理控制台中 通常在Oracle JDK中,我们可以添加这样的参数:< code >-xms 1000m-xmx 1000m-XX:PermSize = 256m-XX:MaxPermSize = 256m-XX:MaxNewSize = 500m-XX:NewSize =
-
如何在windows中查看正在执行的java程序的类路径和jvm参数
在 *nix 中,我只是 来查看正在执行的 java 程序的 jvm 参数和类路径。如何在Windows命令提示符下看到它?我想看看某些罐子是否真的在正在运行的weblogic服务器的类路径中。
-
如果启动了两个JVM,如何调试小程序?
我需要通过打开浏览器窗口调试一个由另一个java应用程序(webstart)启动的小程序。它在旧版本的java上运行良好,但是在Java1.7_45,调试只适用于第一个JVM(即webstart应用程序)。 我在jcontrol中使用这些参数: 我认为这没什么错,因为调试器连接正确。唯一的问题是,我只能调试webstart应用程序,而不能调试之后运行的小程序。 在webstart应用程序和小程序的
-
网络模拟单元测试在本地失败 - java.net.Bind异常:地址已在使用中:JVM_Bind
我有这个测试在我的项目中,它正在使用Wiremock,它在Jenkins正常工作(在构建期间,测试正在执行和通过),但它在我的本地机器中失败,出现以下错误(Eclipse控制台): (马文) 我调试了代码以检查测试中的错误,但我甚至无法做到这一点,因为WireMockClassRule的创建失败了(参见下面的代码)。 问题似乎出在端口的动态分配中,导致如果我硬编码端口值: 所有测试都顺利通过(但由
-
为什么JVM总分配内存大于-Xmx?
JVM选项: 正如预期的那样,JVM将为JVM堆分配将近20MB的内存。 但请参阅以下 GC 详细信息: PSYoungGen总计9216K,已用4612k[0x 00000000 ff 6000000,0x 0000000010000000100000000]< br > Eden空间8192K,56%已用[0x 000000000 ff 600000,0x 0000000 FFA 812d 8
-
找不到Java。Android Studio无法找到有效的JVM。(在Mac OS上)
我知道这个top已经有好几个帖子了,但是每个帖子都充斥着不同的方法,现在距离上一个帖子已经有一个月左右的时间了,现在有了Android Studio1.0.1,我想看看有没有人可以帮助我。 当我在安装应用程序并将其移动到我的应用程序文件夹后运行该应用程序时,我会得到以下消息--“Java Not found.Android Studio无法找到有效的JVM。” 我已经尝试了youtube和谷歌,甚
-
JavaVM致命:无法加载jvm库
我正在尝试使用C++启动jvm。这里是我的cmakelists.txt和ny C++代码。 OpenJDK运行时环境(AdoptOpenJDK)(build 1.8.0_232-B09) OpenJDK 64位服务器VM(AdoptOpenJDK)(版本25.232-B09,混合模式) 主函数运行的结果
-
HTTP JVM:CLFAD0134E执行getDocumentByKey方法时
在 x 页上,我运行以下代码: 这冻结了我的XPage,在日志中我看到了以下标记:2014-08-19 12:46:11 HTTP JVM:com.ibm.xsp.webapp。面Servlet$ExtendedServlet异常:com.ibm.xsp。FacesExceptionEx:java.io。NotSerializableException:lotus.domino.local。Dat
-
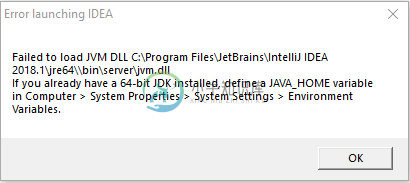 启动意见时出错:无法加载JVM
启动意见时出错:无法加载JVM我最近安装了智能IDEA 2018。但是,当我尝试运行 IntelliJ 时,我收到以下错误消息: 我查看了我的系统环境变量,我把它们贴在下面: 我在命令提示符下检查了我拥有的Java版本: 我检查了我的程序文件: 我还检查了我的程序文件(x86):
-
主内存很多 JVM 需要分配字符数组吗?
考虑以下单线程序: JVM需要多少内存来分配这个256M字符数组? 原来答案是-Xmx384m。现在让我们尝试512M字符数组... 答案似乎是-Xmx769m。 在运行一些大小为m的字符数组的示例。jvm 至少需要 1.5m 兆字节的内存来分配阵列。这似乎很多,谁能解释一下这里发生了什么?
-
JVM占用100%的CPU
Java(TM)SE运行时环境(构建1.7.0_40-B43) Java HotSpot(TM)64位服务器VM(构建24.0-b56,混合模式 我们有相同技术的其他应用程序,但没有问题。 -xms1g-xmx1g-xx:+heapdumponoutofmemoryerror-xx:+useparngc-xx:+useconcmarksweepgc-xx:+printgcdetails-xx:+p
-
带有Cucumber的java.lang.NoClassDefoundError-JVM项目
这是错误的完整轨迹: 这是我的cucumberRunner文件
-
在调用过程中JVM PC存储在哪里?
我目前正在阅读JVM的最后一个规范。很清楚,每个线程都有自己的调用堆栈和自己的程序计数器,它跟踪(下一个)要执行的指令。我的问题是可能是倾倒,但从描述中,我找不到答案。 调用或方法时,当前程序计数器存储在哪里?换句话说,在调用一个方法之后,线程现在在哪里继续呢?
-
Java(JVM)如何为每个线程分配堆栈
但是堆栈创建是如何工作的呢?Java是否在创建每个线程时为其创建堆栈?如果是,堆栈在内存上的具体位置?它当然不在“托管”堆中。 JVM是从本机内存创建堆栈还是为堆栈预先分配了一段托管内存区域?如果是,那么JVM如何知道如何创建线程呢?