《jvm》专题
-
说明新的JVM内存参数的含义InitialRAMPercentage和MinRAMPercentage
问题内容: 参考:https : //bugs.java.com/bugdatabase/view_bug.do?bug_id=8186315 我真的很难找出MinRAMPercentage的功能,尤其是与InitialRAMPercentage相比。 我假设InitialRAMPercentage设置了启动时的堆数量,MinRAMPercentage和MaxRAMPercentage设置了允许J
-
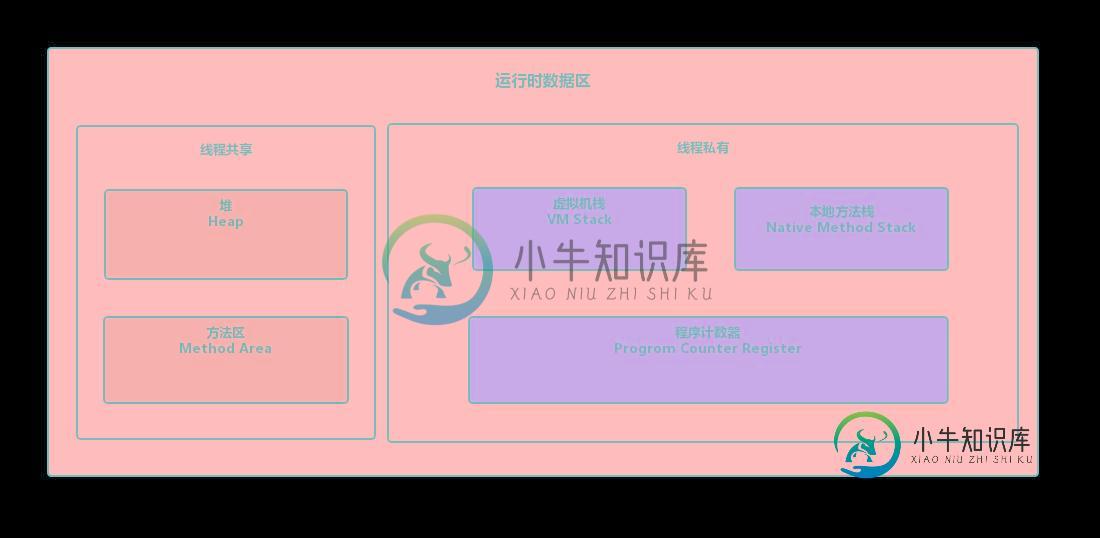 JVM内存结构相关知识解析
JVM内存结构相关知识解析本文向大家介绍JVM内存结构相关知识解析,包括了JVM内存结构相关知识解析的使用技巧和注意事项,需要的朋友参考一下 最近在看《 JAVA并发编程实践 》这本书,里面涉及到了 Java 内存模型,通过 Java 内存模型顺理成章的来到的 JVM 内存结构,关于 JVM 内存结构的认知还停留在上大学那会的课堂上,一直没有系统的学习这一块的知识,所以这一次我把《 深入理解Java虚拟机JVM高级特性与最
-
在Docker容器中运行时JVM无法映射保留的内存
问题内容: 我似乎根本无法在服务器上的Docker容器中运行Java。即使在发出时,我也会收到以下错误。 据此,java不能为保留内存映射2.5Mb的空间吗?这似乎不正确… 我在末尾包含了完整的日志,但是为了提供一些额外的信息,我的系统报告了以下内容: 谁能指出我正确的方向? 完整日志:https : //gist.github.com/KayoticSully/e206c44681ce26167
-
IntelliJ:使用docker jvm还是docker maven?
问题内容: 我有一个docker / jvm实例,可从命令行使用它来编译和运行Java代码。IntelliJ的项目配置要求我指向文件系统上的jvm。 所以,我想知道,我可以配置intellij以使用此docker容器吗?我想我可以配置一个docker容器,使其保持运行状态,并挂载/共享其文件系统,但是我不希望这样- 我想使用我的临时容器实例。 我对使用maven有相同的想法- 我可以在intell
-
Docker Compose JVM参数
问题内容: 我编写了一个Java应用程序,该应用程序使用一个环境变量,该变量带有一个参数来设置JWT令牌盐密钥的密钥。我有办法在Docker Compose中传递命令变量吗? 并运行docker image 问题答案: 如果您已经能够使用以下命令运行docker容器: 然后,您只需要在撰写文件中将您的属性覆盖为–key = blah即可。所以:
-
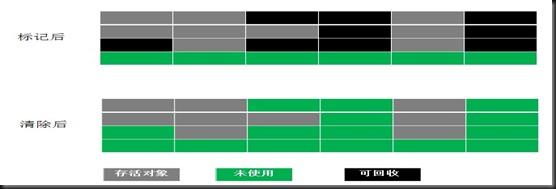
 JVM垃圾回收算法的概念与分析
JVM垃圾回收算法的概念与分析本文向大家介绍JVM垃圾回收算法的概念与分析,包括了JVM垃圾回收算法的概念与分析的使用技巧和注意事项,需要的朋友参考一下 前言 在JVM内存模型中会将堆内存划分新生代、老年代两个区域,两块区域的主要区别在于新生代存放存活时间较短的对象,老年代存放存活时间较久的对象,除了存活时间不同外,还有垃圾回收策略的不同,在JVM中中有以下回收算法: 标记清除 标记整理 复制算法 分代收集算法 有了垃圾回收算
-
 如何通过JVM角度谈谈Java的clone操作
如何通过JVM角度谈谈Java的clone操作本文向大家介绍如何通过JVM角度谈谈Java的clone操作,包括了如何通过JVM角度谈谈Java的clone操作的使用技巧和注意事项,需要的朋友参考一下 前言 最近在给熔断器组件增加一个降级策略(Hystrix好像没有这个配置),我们提供了如下几种策略: 1、默认策略 2、返回常量值 3、抛出指定异常 4、执行一段groovy脚本 当然了,这些配置都是可以在平台上配置,并立即生效的。 目前返回常
-
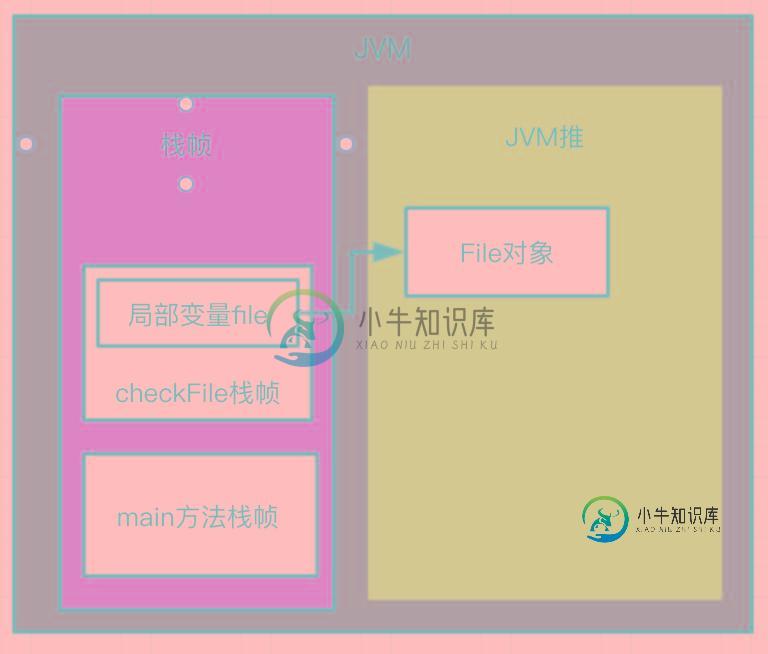
 java jvm的知识详细介绍
java jvm的知识详细介绍本文向大家介绍java jvm的知识详细介绍,包括了java jvm的知识详细介绍的使用技巧和注意事项,需要的朋友参考一下 java jvm 详解: 关于jvm的相关知识 一、堆内存和栈内存 1、jvm中的栈内存主要存储的是基本类型的变量和对象的引用 2、jvm中的堆内存主要存储的是用new来创建的对象和数组,可变长字符串(StringBuilder和StringBuffered)都是存储在堆内存
-
将JVM arg传递给SpringBoot bootRun Gradle任务[重复]
我想将一些JVM arg传递给我的Gradle bootRun任务,即。我补充说: 添加到我的文件中,但是当我运行时它不喜欢它:
-
跨JVM共享Beam DoFn静态变量
所以,我试图弄清楚Beam DoFn中静态变量的行为,它在线程之间共享(在同一个JVM中)吗? 基本上是试图从编程指南中了解以下内容: 4.3.2.线程兼容性 …请注意,函数对象中的静态成员不会传递给工作实例,并且可以从不同的线程访问函数的多个实例。 https://beam.apache.org/documentation/programming-guide/#requirements-用于编写
-
获取给定JVM实例中当前加载的所有类的列表
知道给定的JVM实例当前加载了哪些类会很方便。 例如,有没有办法通过JVisualVM获取它们? 编辑:我知道@Java给出的解决方案-获取JVM中加载的所有类的列表,但我想知道是否有办法通过JVisualVM或其他工具实现这一点。目前,我正在处理一个RCP应用程序,我宁愿不必通过java工具运行应用程序(是的,我很懒)。
-
了解jvm中的循环性能
我在玩jmh,在关于循环的部分,他们说 您可能会注意到重复次数越多,被测量操作的“感知”成本就越低。到目前为止,我们每次添加都使用1/20 ns,远远超出了硬件的实际能力。发生这种情况是因为循环被大量展开/流水线化,并且要测量的操作是从循环中提升的。士气:不要过度使用循环,依靠JMH来获得正确的测量。 我自己也试过了 并得到以下结果: 它确实显示了MyBenchmark。MeasureError\
-
在同一JVM中运行多个Spark任务有什么好处?
不同的来源(例如1和2)声称Spark可以从在同一JVM中运行多个任务中获益。但他们没有解释原因。 这些好处是什么?
-
Cucumber JVM 4.0.0和Junit test runner不发生并行执行
-
Maven/JUnit并行执行-Cucumber-JVM V4.0.0
我正在努力获得Cucumber-JVM V4.0.0与JUnit/Maven一起工作的新并行执行特性。 如前所述,如果在POM中相应地配置和,并使用依赖项注入来共享状态(我使用的是Pico Continer),那么Cucumber特性应该并行执行。 如果有用的话,下面是我的runner类(com.softwareAutomation.world是DI类) 请参阅下面从Maven运行时的失败堆栈跟踪