《农行省分》专题
-
如何通过换行符分割字符串?
问题内容: 我是android开发的菜鸟,我正尝试通过多个换行符将字符串拆分多次。我要拆分的字符串是从数据库查询中提取的,其结构如下: result.getCoin的内容如下: 我想在换行处拆分字符串,然后将每个子字符串放入字符串数组。这是我当前的代码: 这给了我一个输出: 而不是我想要的输出: 任何帮助是极大的赞赏 问题答案: 您可以使用以下语句按换行符分割字符串:
-
Yii2如何执行“与”或“或”条件分组?
问题内容: 我是Yii-2框架的新手。我如何使用activeQuery和模型在Yii-2框架中实现以下查询。 谢谢 问题答案: 您可以尝试以下方法:
-
Jenkins多分支管道扫描,无需执行
问题内容: 我开始创建我的管道多分支环境,但是我遇到了一个问题。 我是否可以仅通过Jenkinsfile运行构建扫描以检测分支,而无需执行管道? 我的项目有不同的分支,当我从父管道多分支启动构建扫描时,我不想要所有带有Jenkinsfile的分支的所有子管道。 感谢您的帮助! 问题答案: 在“ 分支源” 部分,您可以添加一个名为“抑制自动SCM触发”的属性。 这样可以防止Jenkins使用。
-
使用纯SQLite将字符串拆分为行
问题内容: 使用,我想按以下方式拆分字符串。 输入字符串: 并让查询返回以下 行 : 换句话说,我想将文件路径拆分为其组成路径。有没有办法在纯SQLite中做到这一点? 问题答案: 这可以通过递归公用表表达式来实现: (您没有要求 合理的 方法。)
-
Elasticsearch按日期范围进行分组计数
问题内容: 我有这样的文件: 是否可以按日期查询最近10天发布的文档数量?例如: 问题答案: 是的,您可以使用聚合轻松实现这一点,如下所示:
-
使用monotonically_increasing_id()为pyspark数据框分配行号
问题内容: 我正在使用monotonically_increasing_id()使用以下语法将行号分配给pyspark数据帧: 现在df1有26,572,528条记录。因此,我期望idx值为0-26,572,527。 但是当我选择max(idx)时,它的值非常大:335,008,054,165。 这个功能是怎么回事?使用此功能与具有相似记录数量的另一个数据集合并是否可靠? 我有大约300个数据框,
-
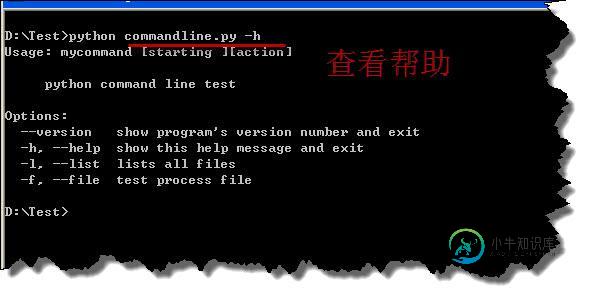 python命令行参数用法实例分析
python命令行参数用法实例分析本文向大家介绍python命令行参数用法实例分析,包括了python命令行参数用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python命令行参数用法。分享给大家供大家参考,具体如下: 在命令行下执行某些命令的时候,通常会在一个命令后面带上一些参数,这些参数会传递到程序里,进行处理,然后返回结果,在linux 下很多命令其实也是用python来实现的。那么如果做到在命令行输入
-
将分隔的字符串值拆分为行
问题内容: 一些外部数据供应商希望给我一个数据字段-管道分隔的字符串值,我觉得这很难处理。 没有应用程序编程语言的帮助,有没有办法将字符串值转换为行? 但是,存在一个困难,该字段具有未知数量的定界元素。 有问题的数据库引擎是MySQL。 例如: 问题答案: 它可能没有我最初想象的那么困难。 这是一种通用方法: 计算分隔符的出现次数 循环多次,每次获取一个新的定界值并将该值插入第二个表中。
-
仅在右侧不为零时执行分配
问题内容: 如果右侧不为零,是否有可能仅执行分配(例如,分配给非可选属性)?我正在寻找一种形式的表格: 问题答案: 与您的代码具有相同效果的单个表达式是 但是您的代码绝对具有更好的可读性。 在此使用的方法,并且仅当函数不返回时才执行闭包。
-
按枚举类型列表进行流分组
我有一个产品类: 如果group是一个单独的字段,就像name一样,我可以这样做: 如何使用? 预期的结果如下所示,对于productList中存在的每个组,映射到在其字段中具有该组的产品列表
-
Cassandra如何仅使用分区键检索行?
类似Bigtable的数据库存储按其键排序的行。 Cassandra使用分区和聚类键的结合来保持数据的分布和排序;但是,您只能通过使用分区键来选择行! 用于上述查询的Cassandra存储层的可视化。
-
 招商杭州分行信息技术一面
招商杭州分行信息技术一面一面是视频面试 就俩问题 1.英文介绍一下自己,半分钟思考一分钟作答 2.中文说一下,开心是不是人生最重要的事。思考一分钟,答两分钟 … 开心当然是人生最重要的事啦,但你们问这么抽象的问题实在让我很不开心耶
-
 11.8 杭州银行软研 十分钟速通
11.8 杭州银行软研 十分钟速通这次面试感觉面试官有点忙的样子。 自我介绍(1min) 讲一个项目 项目是自己做的吗,怎么做的,为什么做,是为了提供给同学使用吗 项目难点 你做这个上线了吗,会给同学用吗 项目有什么优化 同学用完后提出的bug你会怎么处理 后端有接触吗,用过java吗 为什么来杭州 最后没有反问环节,面试官说他们前端的业务会比较少,进来的话可能会需要负责后端方面的工作,后续的笔试题也是主要考察后端方面和java。
-
如何进行探索性数据分析(EDA)?
本文向大家介绍如何进行探索性数据分析(EDA)?相关面试题,主要包含被问及如何进行探索性数据分析(EDA)?时的应答技巧和注意事项,需要的朋友参考一下 EDA的目的是去挖掘数据的一些重要信息。一般情况下会从粗到细的方式进行EDA探索。一开始我们可以去探索一些全局性的信息。观察一些不平衡的数据,计算一下各个类的方差和均值。看一下前几行数据的信息,包含什么特征等信息。使用Pandas中的df.info
-
每隔X分钟运行一次函数-Python
问题内容: 我正在使用Python和PyGTK。我对运行某个功能感兴趣,该功能每隔几分钟从串行端口获取数据并保存一次。 当前,我正在时间库中使用sleep()函数。为了能够进行处理,我将系统设置如下: 这种设置使我从串口读取数据的间隔为5分钟。我的问题是我希望能够让我的readserial()函数每隔5分钟暂停一次,并且能够一直执行操作,而不是使用time.sleep()函数。 关于如何解决这个问