《农行省分》专题
-
使用Jquery,PHP,Mysql进行Ajax分页
问题内容: 已关闭 。这个问题需要更加集中。它当前不接受答案。 想改善这个问题吗? 更新问题,使其仅通过编辑此帖子来关注一个问题。 6年前关闭。 我正在寻找一个使用jQuery,PHP和MySQL的很好的Ajax分页教程。我遇到的那些不好。 因此,如果有人可以推荐一个好的网站/教程,那就太好了。谢谢。 编辑 这是一些不好的教程。 网站1 网站2 网站3 问题答案: 这是 CakePHP的 一个教程
-
Java奇怪的拆分行为 字符
问题内容: 我有一个小文件,其中包含一些我想用“ |”分割的内容 字符。 当我尝试使用其他任何字符(例如“>”)时,它都可以正常工作,但是使用“ |” 性格,有一些意想不到的结果。 行本身(此处带有 >字符) addere> to add>(1) 分割“ >”结果 [加法,加法(1)] 分割“ |” 结果 [,a,d,d,e,r,e,|,t,o,,a,d,d,|,(,1,)] 为什么要拆分所有内容
-
转到lang区分“ \ n”和换行符
问题内容: 我正在尝试通过以下代码读取linux命令生成的某些字符串输出: 以上是类型,如何区分行内容中的“ \ n”字符与实际换行符?我试过了 和 但是只要看到“ \ n”字符,它们都会拆分整个字符串缓冲区。 好了,要澄清一下,“虚幻”中断是字符串中包含的“ \ n”字符,如下所示, 整个输出是一个大的多行字符串,它可能还包含其他带引号的字符串,我正在处理go程序中的整个字符串输出,但是我无法控
-
Python-使用keras进行图像分类
本文向大家介绍Python-使用keras进行图像分类,包括了Python-使用keras进行图像分类的使用技巧和注意事项,需要的朋友参考一下 图像分类是一种使用某种方法将图像分类为各自类别的方法- 从头开始训练小型网络 使用VGG16微调模型的顶层 示例
-
python实现将内容分行输出
本文向大家介绍python实现将内容分行输出,包括了python实现将内容分行输出的使用技巧和注意事项,需要的朋友参考一下 #python版一行内容分行输出 再给大家一个读取文件内容并分行输出的方法 好了,小伙伴们自己好好研究下吧,很有意思。
-
在Titan中使用elasticsearch进行分页
问题内容: 我在Titan上使用Elastic Search。如何用泰坦在ES中进行分页? 我看到了这个,所以尝试了这个: 事情是它返回所有4-5个记录,而不是2的大小 问题答案: 参数尚不支持。该方法仅存在于将来的实现中。但是,您目前可以限制结果。下面的代码应该工作: …但是您不能指定偏移量。 干杯,丹尼尔
-
SQL分割逗号分隔行[重复]
问题内容: 这个问题已经在这里有了答案 : MySQL:将逗号分隔的列表分成多行 (4个答案) 6年前关闭。 我有一列带有可变数量的逗号分隔值: 我希望结果采用每个值,并创建一行: 如何在SQL(MySQL)中执行此操作? (我曾尝试使用谷歌搜索“内爆”和“侧面视图”,但是这些似乎并没有出现相关问题。所有相关的SO问题都在尝试做更复杂的事情) 问题答案: 您可以使用纯SQL来做到这一点 注意: 诀
-
如何在ElasticSearch中不进行分析?
问题内容: 我在ElasticSearch字段中有一个我不想分析的字段,即应逐字存储和比较它。这些值将包含字母,数字,空格,破折号,斜杠以及其他字符。 如果我在此字段的映射中未提供分析器,则默认值仍会使用标记程序,该标记程序会将我的逐字字符串分成大量单词。我不要 是否有一个超级简单的分析器,基本上不分析?还是有另一种方式表示不应分析此字段? 我只创建索引,我什么也没做。我可以在其他字段中使用“英语
-
Elasticsearch插件对文档进行分类
问题内容: 是否有Elasticsearch插件可以让我对输入索引的文档进行分类? 对我而言,最好的解决方案是对所有最经常出现的术语(/概念)进行分类,以一种用户可以浏览的标签云显示。 有没有办法做到这一点?有什么建议? 谢谢 问题答案: 基本思想是使用聚合,每项将产生一个存储桶。 您将获得的响应将通过减少术语出现次数来排序: 如果您正在使用Kibana,则可以基于这些术语直接创建标签云可视化。
-
Swift-将字符串拆分为多行
问题内容: 我如何将字符串分成多行,如下所示? 问题答案: Swift 4包括对多行字符串文字的支持。除换行符外,它们还可以包含未转义的引号。 较早版本的Swift不允许您在多行上使用单个文字,但可以在多行上将文字添加在一起:
-
java中同步块的部分执行
我只是好奇,有没有可能一个线程T1部分执行了一个同步块,然后释放了对象上的锁,而另一个线程T2执行了同一个同步块?大概是这样的: 线程T1是否可能获取当前对象的锁(<code>this</code>)并执行第1行和第2行。然后线程T1被线程T2抢占,T1释放锁,T2获取<code>this</code<的锁并执行相同的块(所有第1行到第5行)。然后线程T1再次获取锁并从第3行继续执行? 基本上,T
-
Java:多行输入,用空格分隔
刚开始编程,你们能告诉我在Java做多行输入的最好方法吗?像这样的小东西。 程序首先询问用户案例的数量。然后要求用户输入由空格分隔的2个整数。 第1列仅表示列数。id还希望能够得到第2列整数的和(25000+1000=?)
-
如何在行号处分割文件
问题内容: 我想从特定的行号中拆分一个400k行长的日志文件。 对于这个问题,让我们将其设为任意数字300k。 是否有Linux命令允许我执行此操作( 在脚本内 )? 我知道可以按大小或行号将文件分成相等的部分,但这不是我想要的。我想要一个文件中的前300k,第二个文件中的最后100k。 任何帮助,将不胜感激。谢谢! 再三考虑,这将更适合于超级用户或服务器故障站点。 问题答案: file_name
-
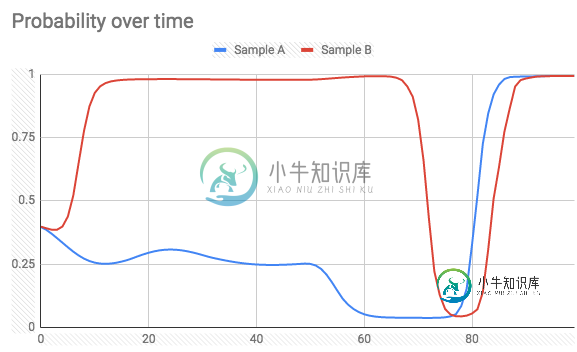 LSTM-对部分序列进行预测
LSTM-对部分序列进行预测问题内容: 这个问题是我先前提出的问题的继续。 我训练了一个LSTM模型,以预测100个具有3个特征的样本的批次的二进制类(1或0),即:数据的形状为(m,100,3),其中m是批次数。 数据: 目标: 型号代码: 在训练阶段,模型 不是 有状态的。当预测我正在使用 状态 模型时,遍历数据并为每个样本输出概率: 当查看批处理结束时的概率时,它恰好是我对整个批处理进行预测时得到的值(不是一个接一个)
-
仅将某些行与GROUP BY分组
问题内容: 施玛 我在MySQL数据库中进行了以下设置: 问题 我需要选择: *具有该值的 *所有 项目都具有价值, 并且 *每个组中的 *一项以 最低的 价格确定。 预期成绩 可能的解决方案1: 两个查询 但是,不希望有两个查询,因为子句中的条件会更复杂,而且我需要对最终结果进行排序。 可能的解决方案2: 关于表达式(参考) 解决方案2似乎更快速,更易于使用,但是我想知道在性能方面是否有更好的方