《B站校招》专题
-
javascript - 正则校验密码问题?
正则校验密码问题 实现包含3位及以上的数字字母密码,不允许为连续/重复的数字或字母,包括正序和倒序,例如:Abc.123、Aaaa@123、Zyx@321 使用正则校验密码正则好像不能校验,用程序写没啥思路
-
javascript - vue3中, 将A赋值给B,然后修改A, B也会跟着修改吗?
在vue3中, 如果我按上面的写法,将currentOptional赋值到了myOptionalList中后, 清空currentOptional,发现myOptionalList也会被清空 我知道这是引用传递的问题,解决方法是进行深拷贝, 但是我有点疑惑,我记得vue2中好像不存在这种问题啊, 是我记错了吗
-
 nginx配置PC站手机站分离实现重定向
nginx配置PC站手机站分离实现重定向本文向大家介绍nginx配置PC站手机站分离实现重定向,包括了nginx配置PC站手机站分离实现重定向的使用技巧和注意事项,需要的朋友参考一下 使用nginx配置PC站手机站分离,我的PC站和手机站都是nuxt框架写出来的,因为nuxt方便SEO,nuxt是基于vue的提高,不知道的自觉搜索nuxt 1,基于APT源安装nginx 2,在指定目录下新建配置文件test.com:文件名随意 3,编辑
-
HTML净化器过滤器入站或出站或两者?
我刚刚开始使用超文本标记语言净化器http://htmlpurifier.org来过滤来自所见即所得编辑器的内容。内容将被显示回给用户或同一组中的其他用户。系统上还有其他组,数据完整性非常重要。 我使用PHP,内容存储在MySQL数据库中。 HTML净化器使用了大量的处理器功能,所以我只想在入站内容上使用它,而不使用任何过滤器直接从数据库显示出站内容。听起来很简单,它被过滤了,所以应该是安全的,但
-
使用Java Jsoup的问题刮网站,网站不“滚动”
我的问题是关于从特定网站上收集数据的可能性。目前,我的算法正在将HTML转换为文本,然后检查文件中包含的标记词,并求和标记的数量。 我的问题在于在刮网站的同时无法向下“滚动”。正如你所看到的,它正在检查一个twitter帐户上的标志数,但它仅限于50sh最新的tweets。我希望我说清楚了。 附注:我给了twitter一个例子,我不是在为twitter寻找特定的东西,而是更健壮的东西。 我将非常感
-
使用Python ping网站?
问题内容: 如何使用Python ping网站或IP地址? 问题答案: 看到这个纯Python平由马修·考尔斯迪克森和延DIEMER。另外,请记住,Python需要root才能在Linux中生成ICMP(即ping)套接字。 源代码本身易于阅读,请参阅和的实现verbose_ping以Ping.do获取启发。
-
跨站点AJAX请求
问题内容: 我需要从一个网站向另一个域中托管的REST Web服务发出AJAX请求。 尽管这在Internet Explorer中很好用,但是其他浏览器(例如Mozilla和Google Chrome)强加了更加严格的安全性限制,这些限制禁止跨站点AJAX请求。 问题是我无法控制站点所在的域或Web服务器。这意味着我的REST Web服务必须在其他地方运行,并且我无法采用任何重定向机制。 这是进行
-
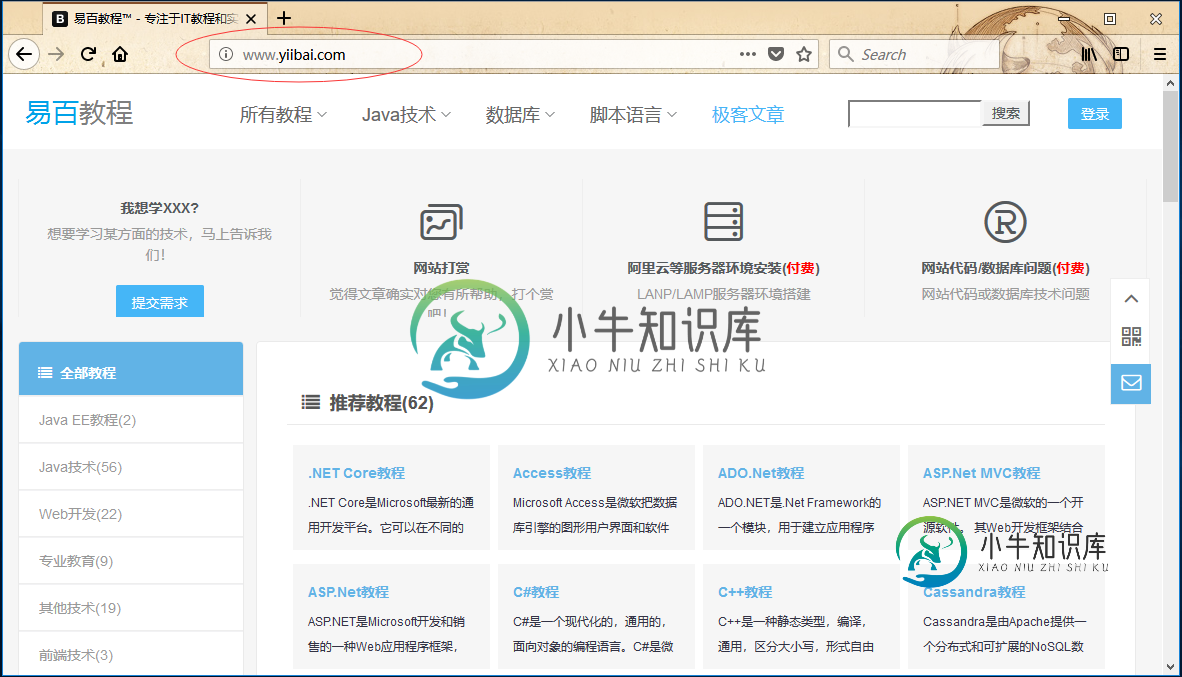 网站开发简介
网站开发简介主要内容:为什么需要创建网站?,如何安装设置网站?一个网站可以被定义为多个相互关联的网页的集合,并且可以通过使用诸如Internet Explorer,Mozilla,Google Chrome或Opera的浏览器访问主页来访问。 例如,小牛知识库的网站地址是 - www.yiibai.com ,打开后显示如下图 - 每个网站都有自己的URL,这是一个唯一的全球地址,称为域名。 一个URL包含(例如:) - 第1段 - 用于访问网站的协议,在这种
-
网站开发教程
主要内容:面向读者,前提条件一个网站可以被定义为几个网页的集合,这些网页都是相互关联的,可以通过访问主页,使用诸如Internet Explorer,Mozilla,Google Chrome或Opera等浏览器来访问。 在本教程中,我们将解释网站开发的概念,从最简单到最高级的。 这将有助于新手用户了解所有关于网站建设的知识技术,以及如何设计和维护。 同时,本教程还有足够的材料可以帮助系统管理员扩大对网站的了解。 面向读者
-
网站的部署 - Gunicorn
Gunicorn 全称 Green Unicorn,是 Ruby 服务器 Unicorn 的 Python 版本,虽然完全是由 Python 实现,但是拥有作为 WSGI 服务器性能优秀,是现在最流行的 WSGI 服务之一。 安装指南 虽然在很多 Linux 操作系统上都有 Gunicorn 的安装包,但通常还是建议使用 Python 包管理工具 pip 来安装最新版本的 Gunicorn: [s
-
网站的部署 - uWSGI
虽然 uWSGI 最常见的使用场景是当作 WSGI 服务器,但它其实还提供了更多的其它功能,这篇博客 中介绍了 uWSGI 如同瑞士军刀般强大的各项功能。 安装指南 官方提供了多种安装方式,比如使用 pip 安装 uWSGI 安装包: pip install uwsgi。 或者使用安装脚本: curl http://uwsgi.it/install | bash -s default /tmp/u
-
Python Scrapy动态网站
问题内容: 我试图在Scrapy及其xpath选择器的帮助下抓取一个非常简单的网页,但由于某些原因,我拥有的选择器在Scrapy中不起作用,但在其他xpath实用程序中却起作用 我正在尝试解析此html代码段: Scrapy parse_item代码: Scrapy不会从中提取任何文本,但是如果我得到相同的xpath和html代码片段并在此处运行它,则效果很好。 如果我使用这个xpath: 我得到
-
用Python编写网站
问题内容: 我非常精通PHP,但想尝试一些新的东西。 我也了解一些Python,足以完成基础知识的工作,但是还没有在Web设计类型的情况下使用过。 我刚刚写了这个,它的工作原理是: 事实是,这似乎很麻烦。如果不使用诸如django之类的大型工具,那么编写可处理获取和发布的脚本的最佳方法是什么? 问题答案: 您的问题是关于基本CGI脚本的,请看您的示例,但是似乎每个人都选择了“使用我最喜欢的框架”来
-
SFDC Twilio出站呼叫
我正在做一个POC,并试图从Salesforce通过Twilio拨打一个出站电话。我已经在Twilio有个账户了。 我已配置TWIML应用程序,并用SFDC URL指向请求的URL:https://xxxxxx.cs8.force.com/Dial. 我可以从我的SFDC软电话(笔记本电脑麦克风)连接到客户(到号码),但我想通过我的from(代理物理电话)连接到电话#。 尽管我已经在
-
多层网站地图?
出发地:http://www.sitemaps.org/protocol.html: 如果要列出超过50000个URL,必须创建多个站点地图文件 那么是否有可能创建一个3层或更多层的链?例如: //mysite/sitemap.xml是: //mysite/sitemaps/index。xml是: 和//mysite/sitemaps/sitemap lm。xml。gz是一个普通的gzip XML