《大疆测试面经》专题
-
 测开 面经
测开 面经一天面了四场,人都要麻了🙂 恒生电子 测开 一面(04.12) 两个面试官,全程15分钟 1. 自我介绍 2. 性能测试时TPS过低,分析原因 3. 接口测试的流程 4. 对恒生电子的了解 5. 反问 快手 测开 一面(04.12) 1. 自我介绍 2. 印象深刻的bug 3. 浏览器输入url的全过程 4. 代码考核 输出最长回文子串 5. 反问 科大讯飞 测试 二面(04.12) 两个面试官
-
 测开面经
测开面经百度 一面 对测开的看法 使用过的测试工具: Junit、jmeter 黑盒白盒测试 linux的命令: 说说你知道的命令:chomd 权限分配、进程相关的、 文件操作 找文本里面的某个字符串的行数 (不会 说说管道、进程间消息共享(管道、消息队列、信号量...) 对指针、取址符的看法 从内存管理方面来回答了,内存安全语言java,实现(垃圾回收器,回收算法,可达性分析、开始吟诵八股......)
-
 测开面经
测开面经百度 二面 自我介绍 怎么看待测开 介绍下覆盖率 异常怎么去考虑测试:构造异常的特殊情况,覆盖每一个条件case 异常情况很多的情况下怎么覆盖: 等价类、判定表等等 项目介绍 短信验证码登陆业务介绍:从cookie到sessioo到redis的优化 难点和挑战性内容:拦截器、双层过滤、锁的优化、事务失效的处理、超买超卖、一人一单、缓存三大问题、雪花算法唯一id 怎么考虑项目上线的优化和缺陷 :用户
-
 测开 面经
测开 面经暑期实习 3月初到现在已经面了好多家,合在一起写一下(Python) 腾讯IEG 2面挂 淘天1次1面挂 被捞,1面等后续 百度 面了两次,不知道后续官网流程没查到 高德 1面等后续 快手 简历挂 饿了么 1面挂 没后续 美团 已拿oc 1.自我介绍 2.为什么选测开 3.项目以及相关 4.职业规划 5.黑盒白盒测试 6.什么是装饰器 7.什么是闭包 8.什么是单例模式 9.Python如何实现多
-
 大概率GG的小厂初级Java面试
大概率GG的小厂初级Java面试1.高并发的处理方式?不会 2.线程安全的集合?答非所问,记得线程不安全的集合。 3.集合与数组的区别? 4.mybatis的缓存有几级?有什么区别?不知道 反问,结束。 总结菜狗,该背题了。 #面经#
-
销售人员完美面试十大攻略
在销售人员面试时,面试官往往会准备一些针对销售人员的面试问题。以下是出国留学网小编整理的销售人员完美面试十大攻略,欢迎参考,更多详细内容请点击出国留学网查看。 攻略一、收集相关信息,做好前期准备 放下面试通知电话后第一件事,就是记录好面试的企业名称、职位及约好的时间地点,尽可能多地搜集目标企业的有关资料。重点需要了解的信息包括:该公司的产品和在同行业领域中的业务数据、公司综合实力及在业内的排名、公
-
 【Android】腾讯、阿里大厂面试题分享
【Android】腾讯、阿里大厂面试题分享腾讯OMG synchronize用法 volatile用法 动态权限适配方案,权限组的概念 网络请求缓存处理,okhttp如何处理网络缓存的 图片加载库相关,bitmap如何处理大图,如一张30M的大图,如何预防OOM 进程保活 listview图片加载错乱的原理和解决方案 https相关,如何验证证书的合法性,https中哪里用了对称加密,哪里用了非对称加密,对加密算法(如RSA)等是否有了解
-
 进大厂必看的 Android 面试题集锦
进大厂必看的 Android 面试题集锦性能优化,怎么保证应用启动不卡顿 BroadcastReceiver,LocalBroadcastReceiver 区别 描述清点击 Android Studio 的 build 按钮后发生了什么 App 是如何沙箱化,为什么要这么做; 图片加载库相关,bitmap如何处理大图,如一张30M的大图,如何预防OOM https相关,如何验证证书的合法性,https中哪里用了对称加密,哪里用了非对称加
-
 西安隆基公司面试-大数据类
西安隆基公司面试-大数据类一面: 8.26--HR面 1.自我介绍 2.特别的经历 3.专业方向 4.做过的项目 5.薪资期待 6.公司的简单介绍,问有些情况是否能接受 二面:9.14--技术面 1.关于大数据技术的认识 2.对Hadoop和Spark的了解 3.对其区别的认识 4.对hadoop特定函数的认识 5.介绍自己了解的窗口函数 6.介绍一个算法,比如支持向量机 7.对自己做过的社会实践的感受 8.反问 三面:9
-
 深圳联通 大数据分析面试 8min
深圳联通 大数据分析面试 8min1自我介绍 2.项目中数据量 3.用户分析维度 4.客户流失分析模型指标 5.oracle和hadoop的了解 等了一个多小时,这就是国内甲方和卑微求职乙方吗?要不是面试官是个声音好听的女生,我大概会骂人吧。 岗位和个人经历不算匹配,我个人经历更偏向数据挖掘,感觉这个岗位更偏向业务分析和数据库。 最后还是再感叹一下,虽然今年秋招求职者的确处于弱势地位,但也不是说招聘单位可以不尊重人吧,起码自己定的
-
 松鼠ai大数据实习岗位面试
松鼠ai大数据实习岗位面试1.问了我项目的问题,spark整合kafka这阶段做了什么事? 答:jdbc工具类向mysql表中插入数据,产生binlog日志文件,maxwell捕获到,kafka进行消费,然后javaapi上面编写kafka工具类,获取主题,编写配置信息,get到消费的内容,是JSON格式,转换json格式为row,然后转换为dataframe表,使用sparksql处理。 2.kafka的acks值有了解
-
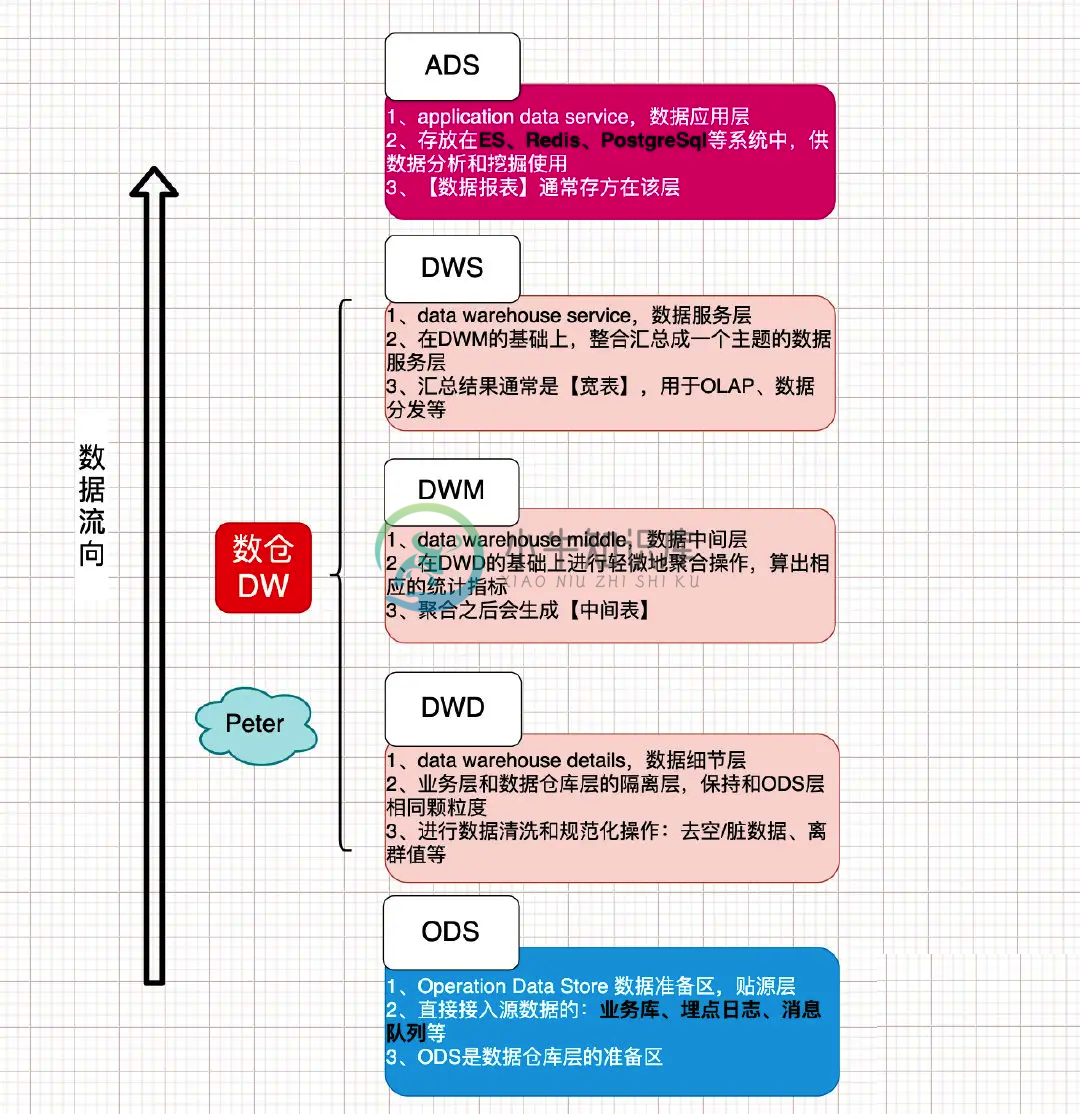 大数据数仓高级面试题【8道】
大数据数仓高级面试题【8道】主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
 设计师大厂面试必备作品集
设计师大厂面试必备作品集不要什么都往作品集里放,挑你做的最好的放进去,不要做成长图,或者就放一两张图, 毕竟找工作要靠作品说话,能不能进心仪的大厂靠的就是作品集好不好。 1、作品集大小控制在10M-20M之内 最好是pdf格式的,如有需求也可加一个Word文字版简历。 2、封面吸引人 封面很重要,决定着面试官要不要继续往下看,能直接影响他判断作品集的质量。 3、作品集结构要归类清晰 分类展示比如,logo、字体设计、包装
-
 科大讯飞nlp算法岗实习面试
科大讯飞nlp算法岗实习面试1 自我介绍 2 问了一些问题细节 Bert内部的架构是什么样的? 注意力机制是怎么回事,如何计算? 简单回答了下KQV啥的,具体的矩阵运算记不得了 为什么Bert内部采用batch layer(没听太清)? 不知道没答上来 Bert和GPT结构上有什么区别? 3 经历问题 问到了项目中做语义匹配的时候使用Bert什么标记的输出 4 闲聊 有没有接触过实体抽取和知识图谱? 为什么学管理的来搞算法?
-
 唯品会-大数据开发实习面试
唯品会-大数据开发实习面试7.15一面: 1.自我介绍 2.项目深挖(聊了很久) 3.对数仓的看法 4.主题域及其建设过程(要落地,谈业务过程) 5.讲一个熟悉的指标体系构建(没做过) 6.为什么不考研 7.为什么想跳槽 8.sql留存率(讲了下思路就行了) 反问: 1.为啥晚上6点还面试,唯品会不是955吗 2.唯品会的计算引擎选型是什么 ------------------------- 挂了