《大疆测试面经》专题
-
 米哈游 游戏测试 3面业务终面
米哈游 游戏测试 3面业务终面面试mhy前也在牛客看了不少面经,现在3面失败了,也来做个面经,攒攒人品。 1.讲一讲新版本的地图相比以前有什么不同 2.原神的练度怎么样 3.原神配队 4.写一个风神瞳的测试用例 5.谈一谈最喜欢的原神角色,为什么 6.谈一谈对游戏测试的理解 7.为什么选择游戏测试(我是机械专业的,专业并不对口) 8.你觉得你如果想要从事游戏开发,最需要提升的是哪个方面 9.谈一谈项目经历 10.项目中遇到过的
-
 猿辅导测试实习生一面(仅一面)
猿辅导测试实习生一面(仅一面)Q1:自我介绍; Q2:谈一下对软件测试的理解? Q3:针对登录框进行测试(包含用户名(手机号),验证码,登陆按钮等等) 面试官让我共享屏幕,写了10多分钟; 最后追问等价类在整个测试当中的体现过程; Q4:反问:公司培养,面试表现(说现在不好评价),面试官说都是功能测试
-
 兑吧 测试实习生 一面和二面 和hr面
兑吧 测试实习生 一面和二面 和hr面1.自我介绍 2.讲讲你对12306如何实现高并发的理解,比如架构或者技术栈 3.说说你在写这个项目的时候 花了多长时间,遇到的最大的难点是什么,是怎么解决的 4.说说常用的黑盒测试方法和白盒测试方法 5.说说java代码编译过程 6.一个h5页面,用来抽奖的转盘,请你设计测试用例 7.你的项目中用到了什么java的修饰符吗,展开说说(太紧张一下子不知道说什么了) 8.说说redis中的分布式锁
-
 2023秋招-大数据开发面试-百度-三面
2023秋招-大数据开发面试-百度-三面1、 项目一直挖 2、 Spark调优 3、 Shuffle之类的优化 4、 平常写SQL注重优化之类的问题 5、 第一道题让看下面Java代码写输出。 private static void test(int[] arr) { for (int i = 0; i < arr.length; i++) { try { if (arr[i] % 2
-
了解大符号-破解编码面试
问题内容: 我需要帮助,以帮助作者了解“大O”一章中问题11的答案。 问题是这样的: 下面的代码打印所有长度为k的字符串,其中字符按排序顺序排列。它通过生成所有长度为k的字符串,然后检查每个字符串是否已排序来做到这一点。它的运行时间是多少? 预订答案: O(kc k),其中k是字符串的长度,c是字母中的字符数。生成每个字符串需要O(c k)时间。然后,我们需要检查所有这些是否已排序,这需要O(k)
-
面试十大难题的回答模板
在面试前先了解、练习对几个很难的问题进行回答会帮助你对其他问题的回答做准备。有的问题问得比较多,有的较少但却是回答其它问题的基础。 1、为什么不谈谈你自己? 分析:这是个开放性问题。从哪里谈起都行,但是滔滔不绝地讲上一两个小时可不是雇主所希望的。这样的问题是测验你是否能选择重点并且把它清楚、流畅地表达出来。显然,提问者想让你把你的背景和想要得到的位置联系起来。 回答对策:有几个基本的方法。一个是直
-
 大学面试新颖的自我介绍
大学面试新颖的自我介绍主要内容:大学面试新颖的自我介绍【篇1】,大学面试新颖的自我介绍【篇2】,大学面试新颖的自我介绍【篇3】,大学面试新颖的自我介绍【篇4】,大学面试新颖的自我介绍【篇5】,大学面试新颖的自我介绍【篇6】,大学面试新颖的自我介绍【篇7】,大学面试新颖的自我介绍7篇 大学面试新颖的自我介绍?“面试”是当代大学生需要经历的事情,而自我介绍就是一项重要的技能。既然这样,那么下面小编给大家带来了大学面试新颖的自我介绍,供大家参考。 大学面试新颖的自我介绍【篇1】 我的名字叫刘z,来及江苏省宿迁市,是20__
-
 大学生面试高级自我介绍
大学生面试高级自我介绍主要内容:大学生面试高级自我介绍【篇1】,大学生面试高级自我介绍【篇2】,大学生面试高级自我介绍【篇3】,大学生面试高级自我介绍【篇4】,大学生面试高级自我介绍【篇5】,大学生面试高级自我介绍【篇6】,大学生面试高级自我介绍【篇7】,大学生面试高级自我介绍7篇 大学生面试高级自我介绍?对于每一位应聘者来说,自我介绍都是需要好好去准备的,最好是根据每一个单位的情况进行撰写,那样适配性会更大。下面小编给大家带来了大学生面试高级自我介绍,供大家参考。 大学生面试高级自我介绍【篇1】 我叫__,是来自_
-
 持续更新Android大厂的面试题
持续更新Android大厂的面试题前言 音视频相关: 1.OpenGL渲染流程 2.在MPEG标准中图像类型有哪些? 3.视频或者音频传输,你会选择TCP协议还是UDP协议?为什么? 4.视频直播如何做音视频同步 5.播放器暂停、快进快退、seek、逐帧、变速怎么实现? 6.如何降低延迟?如何保证流畅性?如何解决卡顿?解决网络抖动? 7.OpenGL的坐标和手机物理坐标有什么不同 8.如何秒开视频?什么是秒开视频? 9.预测编码的
-
 大数据开发面试题之Hive篇
大数据开发面试题之Hive篇hive的架构 hive外部表和内部表的区别 内部表的数据由hive管理,且存储在hive.metastore.warehouse.dir配置下的路径中;外部表的数据由HDFS存储,路径可以自己指定; 删除表时,内部表会把元数据及真实数据删除;外部表不删除真实数据。 你用过hive哪些窗口函数 可参考:面试官:你用过哪些窗口函数 一般用什么文件格式 可参考:面试官:“你们实际生产中hive用什么文
-
 虾皮Shopee UI/UX面试大纲分享
虾皮Shopee UI/UX面试大纲分享记录下最近虾皮 Shopee UI/UX 设计的面试经验,这个岗位是 hr 主动来找到我电话沟通咨询是否有意向投递的,投递后很快通过了简历筛选,技术面总共有三轮,第一轮结束后会需要完成一份笔试题目,然后进入第二轮,但由于在第二轮的时候聊得不太同频道,所以面经里只包含了第一二轮遇到的面试问题啦,全程中文。 部分高频出现的问题: 1、自我介绍 2、用户研究能力(后续了解到因为他们团队没有细分的 res
-
 字节面试-大数据开发实习
字节面试-大数据开发实习视频ms 前三分钟 自我介绍 数据仓库的了解 怎样设计数据分层 了解的大数据组件 spark用于解决什么问题 spark底层逻辑 sql的join实现方式 举例A(3) join B (5) 有几条数据 join底层逻辑 sql题 查询用户峰值 全程不到30分钟 **我就是一个小菜鸡。问就是面试凉凉 问的其实感觉没有特别难 但就是啥都不会。还是学的太过浅层次。总的来说 项目拷打 底层深挖。G
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
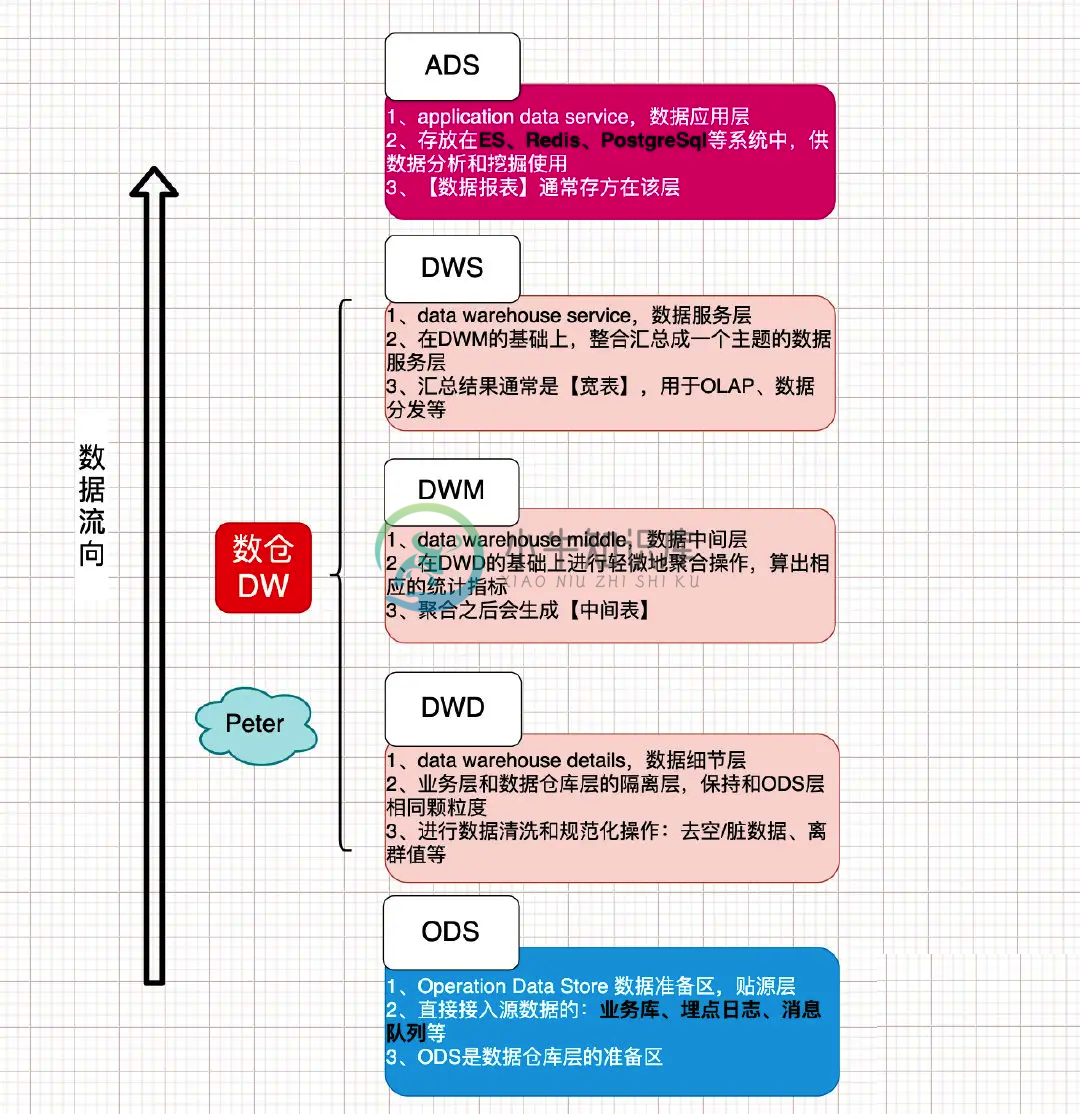 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括