《图森未来》专题
-
玩!框架-视图未编译?
问题内容: 我创建了一个新项目,并使用了eclipse(旧命令)。 基本上,我将目录从一个旧项目移动到了我创建的新项目。 问题在于eclipse无法识别视图。我收到如下错误: views.html.viewTopic无法解析为一种类型 我试图这样做,但是没有帮助。 所以我有40个错误。所有这些都与视图未编译的事实有关,因此,日食无法识别它们(我的猜测当然是)。 我能做什么? 顺便说一下,旧项目编译
-
CSS背景图片未加载
问题内容: 我已经按照所有的教程讲完话了。我在CSS样式表中的身体内部指定了背景,但是页面仅显示空白的白色背景。图片与.html和.css页面位于同一目录中。本教程说 已弃用,所以我在CSS中使用 没有成功。这是整个CSS样式表: 问题答案: 这是另一个图片网址结果..工作正常…我只是放了一个图片路径..请检查一下..
-
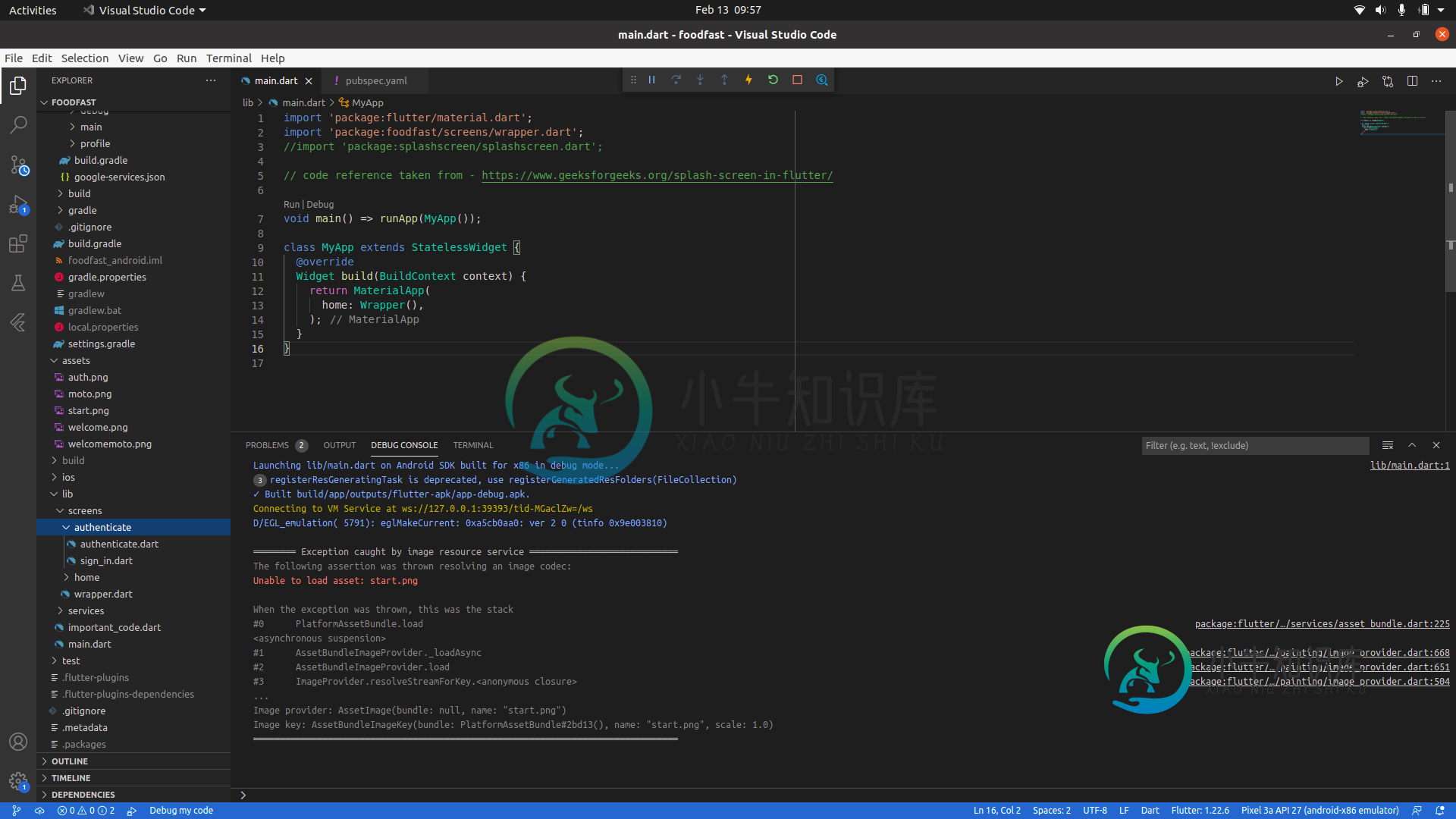 flutter android中未加载图像
flutter android中未加载图像我试了所有的办法,但似乎都不奏效。据我说,图像的路径是正确的。(虽然我附上了一张图片供参考)。这就是我得到的错误- 这是**pubspec.yaml*- 名称:foodfast描述:一个新的颤振项目。 Publish_To:'none' 版本:1.0.0+1 环境:SDK:“>=2.7.0<3.0.0” 依赖项:flutter:SDK:flutter 弹出屏幕:^1.3.5 cupertino_i
-
FOP图像未找到错误
我正在尝试使用带有xslt的外部图形来生成PDF。大多数图像都工作正常,但偶尔会有一张“找不到”,尽管可以在Web浏览器上查看。FOP吐出的错误如下: 这是我的外部图形部分: 知道我做错了什么吗? 编辑:看起来这个问题与服务器不允许访问自动请求有关。有没有办法在fop 2.1中设置用户代理的URIResolver?这一功能似乎存在于以前的版本中,但我似乎找不到一种在2.1中实现的方法。
-
Laravel视图未找到异常
问题内容: 我对laravel视图有问题,找不到路由函数,我做了作曲家dumpautoload但没有使用ArticleController.php InvalidArgumentException 问题答案: 当Laravel在您的应用程序中找不到视图文件时,就会发生这种情况。确保你有一个文件名为:或者你在目录中。 请注意,在调用时Laravel将执行以下操作: 对于Laravel,它将查找文件:
-
Jar中未显示的图像
我的程序在Eclipse中运行完美,但是当我导出它时,图像不显示出来。 我的设置看起来像 我参考标志。来自MenuMain的png。java,我尝试了很多方法; 前3个在Eclipse中工作,但都不在Jar中工作。我检查了Jar文件,res文件夹在那里,所有的图像也是如此。我还尝试编辑MANIFEST. MF并添加了类路径: 但它仍然不起作用。我在运行Jar时没有发现任何错误,其他所有内容都显示在
-
Laravel邮件视图未呈现
我使用Queue发送电子邮件,代码如下: 在控制器部分,我使用send- 我正在使用视图: 现在,当我尝试发送时,收到的电子邮件中没有任何内容。 我已经调试了整个供应商\laravel\framework\src\illighted\Mail\Mailer。php类并发现renderView函数中无法呈现视图。 我还将视图Doctype更改为HTML5,但得到了相同的结果,没有内容。 渲染视图正在
-
未显示大型Neo4j图形
我创建了一个大型neo4j图,将用户连接到他们像用户一样观看的视频- 如果我尝试: 图表显示“显示300000个节点,0个关系”没有显示图表、关系或节点。 如果我尝试: 图表显示“显示1000个节点,1000个关系(完成1000个附加关系)”所有图形、关系和节点都会显示出来。 如果我尝试: 没有显示图形、关系或节点。 第一个图形是否太大而无法显示?如何让它显示? 提前谢谢你。
-
图片未使用BitmapFactory.decodeByteArray创建
问题内容: 编辑:当我将这些字节保存在txt文件中并且将其保存为png文件时,它显示图像,但是在这里为什么不起作用? 我正在使用此代码从doInBackground()上的字节数组创建图像 和onPostExecute logcat中没有错误,即使其中也没有异常..但是图像未显示。我也这样 但是结果没有显示相同的图像,但是没有异常或错误,这是什么问题… 带注释的行是当我尝试将这些字节存储到文本文件
-
在React中未加载图像
无法将获取错误的图像显示为未找到,但我已为其提供了完整路径。我不知道我错在哪里。
-
裁剪后未裁剪图像
我试图在从图库中选择图像后使用intent来裁剪图像。以下是我的代码片段 在这里,我使用PICK_IMAGE_REQUEST意图句柄调用上面的代码段 由于我在裁剪后使用了相同的意图,即PICK_IMAGE_REQUEST,可能会出现什么问题
-
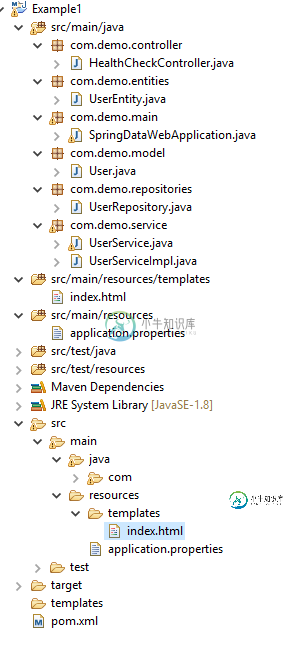 Spring boot:MVC未返回视图:thymeleaf
Spring boot:MVC未返回视图:thymeleaf好的, 我试图使一个简单的mvcSpring启动应用程序,我有它在我的代码返回index.html当控制器接收到"/"的请求。 我不确定,但这不起作用。 SpringDataWebApplication。JAVA HealthCHeckController。JAVA 用户存储库。JAVA 指数html 指数html位于/templates目录中,如thymeleaf所示 pom.xml 用户实体。
-
Spring Boot-JSP视图未找到
我正在寻找如何使用spring Boot运行jsp。我试了几次,但还是没找到。 然后我进行了以下配置: PageNotFound:未找到名为“DispatcherServlet”的DispatcherServlet中URI[/app/WEB-INF/jsp/login.jsp]的HTTP请求映射 jsp页面可以在以下站点找到:src/main/webapp/WEB-INF/jsp/login.js
-
Android-Fresco未加载JPG图像
我正在尝试加载图像使用壁画库,但我有一个奇怪的问题。 png图像正在加载,但我加载的是jpg图像我使用的壁画版本是2.0.0,我尝试了一切无效缓存,改变壁画版本,清除数据,重建项目。但对我来说没有任何意义。 不工作 //初始化壁画 您可以在下面看到所有的日志:
-
视图未被Dagger实例化
我正在做一个Dagger研究项目,我是基于我在git中发现的一些其他项目来做这个项目的,我在一个课上遇到了一个问题。 该项目是关于读取和提交git存储库的,它在不使用MVP和Dagger的情况下开始工作,但我正在重构它以使用这些特性。 RepositoriesPPreseInterimpl类扩展了BasePresenter,后者又有一个BaseView类型的视图(iRespositoriesPop