《图森未来》专题
-
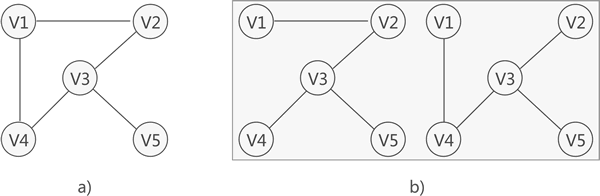 什么是生成树(生成森林)
什么是生成树(生成森林)主要内容:生成森林在学习 连通图的基础上,本节学习什么是 生成树,以及什么是 生成森林。 对连通图进行遍历,过程中所经过的边和顶点的组合可看做是一棵普通树,通常称为 生成树 。 图 1 连通图及其对应的生成树 如图 1 所示,图 1a) 是一张连通图,图 1b) 是其对应的 2 种生成树。 连通图中,由于任意两顶点之间可能含有多条通路,遍历连通图的方式有多种,往往一张连通图可能有多种不同的生成树与之对应。 连通图中
-
 北森提前批二面挂 前端
北森提前批二面挂 前端北森一共只有两轮技术面,7/21投递的 一面:7/22 1. React 和 Vue 有什么共同之处和区别 2. Virtual DOM 是什么东西?带来了什么好处 3. Diff 算法?有哪些优化 (我答的React的) 4. 你是用 class 写法多还是 hooks 写法多 5. 你觉得 hooks 写法的作用是什么 6. hooks 怎么模拟 componentDidMount 7. us
-
卢森。网络新手查询问题
第一次使用Lucene,所以如果某些术语不正确,我会提前道歉。 我正在修改一个查询,没有得到预期的结果。搜索词用于构建布尔查询,我需要添加一个额外的字段进行搜索。这个名为的字段已经是索引的一部分(通过Lucene的确认),但尚未包含在搜索中。 当前布尔查询如下所示: (是引用字段名称的) 我认为这将是一个扩展标记数组的例子,如下所示: 但是当搜索我知道存在的时,这买回了没有结果,但是我知道存在的的
-
可变和随机森林的等级
考虑一个数据集训练: 二元结果变量z和三个水平的分类预测因子a:1、2、3。 现在考虑一个数据集测试: 当我运行以下代码时: 我收到以下错误消息: 我假设这是因为测试数据集中的变量a没有三个级别。我该如何解决这个问题?
-
数字比较在IBM沃森助手
我试图在Watson内部构建一个BMI计算器,但当你使用“多重条件反应”时,Watson似乎不支持数字比较。 此代码将抛出一个错误: 编辑:解决了。这是我自己的错。如果你在“多重条件反应”中设置条件,不要包括。 在本例中,您只需输入
-
格森。toJson(对象)BigDecimal精度丢失
当我将Object转换为Json时,我遇到了大十进制精度丢失的问题。 假设我有Pojo类, 现在我将值设置为Pojo,然后转换为JSON 第一次测试-正确输出 第二次测试-输出错误(失去BigDecimal精度) 第三次测试-输出错误(失去BigDecimal精度) 令人惊讶的是,每当BigDecimal值的长度更大时,它也会截断小数点。json转换有什么问题。你能给我提供解决方案吗?
-
七、集成学习和随机森林
假设你去随机问很多人一个很复杂的问题,然后把它们的答案合并起来。通常情况下你会发现这个合并的答案比一个专家的答案要好。这就叫做群体智慧。同样的,如果你合并了一组分类器的预测(像分类或者回归),你也会得到一个比单一分类器更好的预测结果。这一组分类器就叫做集成;因此,这个技术就叫做集成学习,一个集成学习算法就叫做集成方法。 例如,你可以训练一组决策树分类器,每一个都在一个随机的训练集上。为了去做预测,
-
七、集成学习和随机森林
假设你去随机问很多人一个很复杂的问题,然后把它们的答案合并起来。通常情况下你会发现这个合并的答案比一个专家的答案要好。这就叫做群体智慧。同样的,如果你合并了一组分类器的预测(像分类或者回归),你也会得到一个比单一分类器更好的预测结果。这一组分类器就叫做集成;因此,这个技术就叫做集成学习,一个集成学习算法就叫做集成方法。 例如,你可以训练一组决策树分类器,每一个都在一个随机的训练集上。为了去做预测,
-
集成方法-随机森林和AdaBoost
集成方法: ensemble method(元算法:meta algorithm) 概述 概念:是对其他算法进行组合的一种形式。 通俗来说: 当做重要决定时,大家可能都会考虑吸取多个专家而不只是一个人的意见。 机器学习处理问题时又何尝不是如此? 这就是集成方法背后的思想。 集成方法: 投票选举(bagging: 自举汇聚法 bootstrap aggregating): 是基于数据随机重抽样分类器
-
协议森林14 逆袭 (CIDR与NAT)
IPv4由于最初的设计原因,长度只有32位,所以只提供了大约40亿个地址。这造成了IPv4地址的耗尽危机。随后,IPv6被设计出来,并可以提供足够多的IP地址。但是IPv4与IPv6并不兼容,IPv4向IPv6的迁移并不容易。一些技术,比如说这里要说的CIDR和NAT,相继推广。这些技术可以缓解IPv4的稀缺状态,成就了IPv4一时的逆袭。 CIDR CIDR(Classless Inter Do
-
协议森林07 傀儡 (UDP协议)
我们已经讲解了物理层、连接层和网络层。最开始的连接层协议种类繁多(Ethernet、Wifi、ARP等等)。到了网络层,我们只剩下一个IP协议(IPv4和IPv6是替代关系)。进入到传输层(transport layer),协议的种类又开始繁多起来(比如TCP、UDP、SCTP等)。这就好像下面的大树,根部(连接层)分叉很多,然后统一到一个树干(网络层),到了树冠(传输层)部分又开始开始分叉,而每
-
十八、深入:决策树与森林
在这里,我们将探索一类基于决策树的算法。 最基本决策树非常直观。 它们编码一系列if和else选项,类似于一个人如何做出决定。 但是,从数据中完全可以了解要问的问题以及如何处理每个答案。 例如,如果你想创建一个识别自然界中发现的动物的指南,你可能会问以下一系列问题: 动物是大于还是小于一米? 较大:动物有角吗? 是的:角长是否超过十厘米? 不是:动物有项圈吗? 较小:动物有两条腿还是四条腿? 二:
-
 北森前端|暑期实习|KPI面
北森前端|暑期实习|KPI面时长30min 说在前面 其实我首先鸽了它一次,因为那次刚好阳了,比较难受就延期了,然后它一口气给我往后延了10天,后面面试的时候就能感受到是kpi了。面试官问的有很多都是非常非常基础的,基础到甚至我稍不注意可能就忘了(不熟的问题下面还是额外解释了一些)。并且面试途中面试官那边网络很差,他竟然直接让我和他都关掉视频,换成语音聊天,我就知道又是来刷业绩的,面试时长也很短。果然面完没两小时官网流程就结
-
 阿里测试开发面经+北森
阿里测试开发面经+北森有些记不太清了,写个大概 最近一起面的,所以直接写在一起 一面 介绍部门 自我介绍 进程与线程的区别?开始吟唱 cpu调度算法?继续吟唱 并发怎么控制?项目中的体现? 有哪些印象深刻的排序算法? 这些算法复杂度是多少?哪些稳定 对于大数据上百万的数据排序怎么选择排序算法 堆排序相关 了解图论的相关知识吗 讲一讲最短路径、迪杰斯特拉之类的 hashset、hashmap?应用场景 平时怎么做的测试
-
NHibernate未来对象图有很多查询
问题内容: 给定一个使用Future调用的多层对象图: 当我调用var Dad = dads.ToList()时,我看到该批生产线穿过了,并在探查器中显示。 问题是在枚举集合时它仍向数据库发送一次查询 例如。 发送一个SQL查询并访问数据库以获取每个孩子。为什么未填充对象图?还是这种预期的行为? 问题答案: 这种行为是可以预期的。您只是在告诉NHibernate从数据库中批量获取两个集合,这就是按