《生化医药面经大本营》专题
-
 大疆创新 数字化产品经理笔试 新鲜回忆
大疆创新 数字化产品经理笔试 新鲜回忆进入考试页前先填写信息,并选择两个方向志愿。我选的是研发领域+数据领域,等一波共友。 题目分为单选44分(2分/题)+多选56(4分/题) 选择题主题限定在企业信息化产品(toB交付物)。内容主要都是项目管理+产品运营+软件工程方面的知识。涉及项目规划、产品规划、产品运营、软件测试等等。 产品的交付物是什么 产品需要输出的规划方案 产品的职责(什么文档要上评审会 啥啥的 我选了”需求变更审批不是产
-
Excel 大数据生成-BigExcelWriter
介绍 对于大量数据输出,采用ExcelWriter容易引起内存溢出,因此有了BigExcelWriter,使用方法与ExcelWriter完全一致。 使用 List<?> row1 = CollUtil.newArrayList("aa", "bb", "cc", "dd", DateUtil.date(), 3.22676575765); List<?> row2 = CollUtil.newA
-
 面经刺客 | 字节技术中台产品(游戏化产品) 暑期实习面经
面经刺客 | 字节技术中台产品(游戏化产品) 暑期实习面经满怀期待投递了技术中台的暑期实习,结果被问得云里雾里,jd跟实际岗位基本不符。在尴尬的流程中迅速结束了面试并被挂,甚至可能留下了不太好的面评。字节投递之旅略带多灾多难。 个人背景 深圳大学23届计算机本科+网络与新媒体双学位,准备留学申is/cs/ds研究生。 一段数据分析实习,主要做了几个内部工具,承担部分数据产品职能;若干零碎产品项目&用户研究经历;业余爱好是摄影、影视拍摄,恰过小钱。 职业规
-
 字节跳动-飞书-产品运营日常实习生面经
字节跳动-飞书-产品运营日常实习生面经楼主在BOSS直聘上投的日常实习,其实没抱什么希望,很意外收到了面试邀约,目前暑期实习不太顺利的小伙伴,建议可以去BOSS直聘看看,进度很快! 一面-20min-04/25 自我介绍 介绍下你的两段实习经历(产出、学到了什么)? 为什么不选择技术相关岗位,选择产品运营? 实习地点(北京、杭州、广州)有问题吗? 最快到岗时间?实习时长?(重点询问,面试官解释说需求很急,会作为重点考量对象) 大学(目
-
 顺丰科技2023届暑期实习生面经-产品运营
顺丰科技2023届暑期实习生面经-产品运营一面-技术面36min-04/22 自我介绍 你认为的产品运营?需要具备的能力? 有自学过运营方面的知识吗? 最有成就感的事情 大学报考初衷?为什么不从事技术相关岗位? 看重实习的点(薪资、待遇、企业文化)? 假如需要去到物流中转站线下实习,你能接受吗? 对顺丰科技的了解? 大学(目前)的规划? 反问:本场面试的不足?部门具体业务?结果通知? 面完感觉又要感谢信+1辽,积累面试经验吧,不过还是希望
-
 百度健康平台运营实习生-面经分享-有offer
百度健康平台运营实习生-面经分享-有offer2月底到3月中旬,半个月海投了60+简历,面了11次,百度、字节、快手、小红书、蒙牛等都面了,有时候一天面三个(累)。主要方向是MKT或者运营(用户/电商/产品),打算在牛客依次写一下我面过的这些的面经,算是为暑实攒人品了。 一面: 1.简历挖掘,主要问我的两段实习都干了啥 2.介绍了自己的产品,是一个针对医学专业学习及从业者的app,叫有医,核心功能是做笔记 3.对岗位的期待 4.要求想一个拉新
-
tkinter python最大化窗口
我想初始化一个窗口为最大化,但我不知道如何做。我在Windows7上使用Python3.3和Tkinter 8.6。我想答案就在这里:http://www.tcl.tk/man/Tcl/Tkcmd/wm.htmam.m8但是我不知道如何将它输入到我的python脚本中 此外,我需要得到窗口的宽度和高度(既是最大化的,如果用户重新缩放它之后),但我想我可以自己找到。
-
无法找到捆绑Java版本与flutter医生,更新Android Studio北极福克斯(2020.3.1)在M1苹果硅
我面临着一个奇怪的问题。在我更新我的Android Studio之前,flutter医生一切都很好。一旦我更新了Android Studio,当我运行医生时,它显示“无法找到捆绑Java版本”。我已经下载了Java安装程序并将其安装在我的M1 Mac上,但在我重新启动后,运行flutter医生仍然显示相同的错误。奇怪的是,当我卸载北极狐版本并重新安装旧的Android Studio版本时,运行医生
-
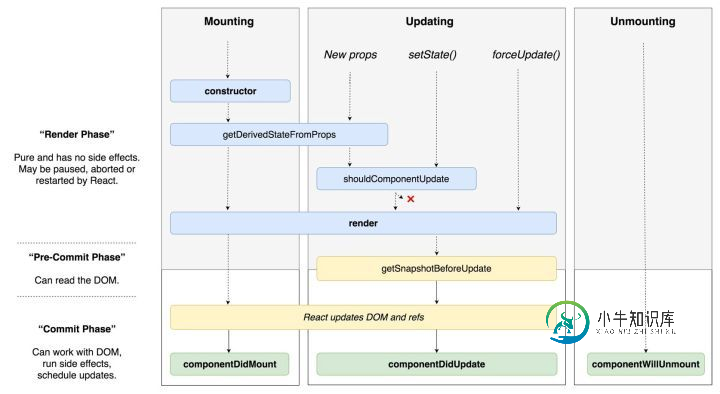 react16跟之前的版本生命周期有哪些变化?
react16跟之前的版本生命周期有哪些变化?本文向大家介绍react16跟之前的版本生命周期有哪些变化?相关面试题,主要包含被问及react16跟之前的版本生命周期有哪些变化?时的应答技巧和注意事项,需要的朋友参考一下
-
 选择时,RadioButton颜色和文本颜色会发生变化
选择时,RadioButton颜色和文本颜色会发生变化我该怎么做? 这是我用来更改文本颜色的: 我设置了<代码> 有什么想法吗?
-
 华泰证券数字化运营金融产品经理终面
华泰证券数字化运营金融产品经理终面Q: 1.自我介绍 2.你了解到的产品经理完整的工作流程,详细说一下 3.你做产品经理的交付物是什么? 4.数据运营具体是从事什么工作? 5.你有了解华泰证券吗? 6.你自己有使用过金融产品?从产品经理角度怎么看?有什么竞品? 7.看过哪些产品经理的书?现在还在看哪些书? 8.做产品经理的话,做数据分析你具体看哪些数据指标?看的周期是多久? 9.之前社群运营的工作具体有哪些,指标提升了多少? 10
-
 【日常实习面经】字节跳动商业化-产品运营
【日常实习面经】字节跳动商业化-产品运营一面(30min) 自我介绍 小米实习里面收获最大、做的最好的部分(说了推广策划部分) 数据指标主要是什么(点击率) 百词斩里的业务调研的工作流是怎样展开的(主要说了怎么承接业务需求) 问的是怎样开展业务调研,包括怎么邀约(其实跟面试官想的不太一样,但补说了用户调研的部分) 这些过程你有自己去参与对吧? 对抖音广告有什么了解吗?(回答的有点乱……应该提到竞价广告的) 讲了一下工作板块和可能的一些顾
-
 百度-自动驾驶部-大数据开发面经
百度-自动驾驶部-大数据开发面经2023春招找实习的同学跟我分享了他的面试经历,在这里我进行了一些总结梳理,然后发出来供大家学习 1.自我介绍 2.八股文 你写的这个实时数仓,维表是怎么更新的 flink了解吧,flink里面断流怎么处理 flink的exactly-once是怎么实现的 checkpoint的时候barrier什么时候发送 checkpoint产生了很多快照,怎么进行处理呢 sparkstreaming和str
-
 3.22 大数据开发美团实习一面(凉经)
3.22 大数据开发美团实习一面(凉经)#牛客解忧铺##牛客在线求职答疑中心##你觉得今年春招回暖了吗##面经##大数据开发# 附加信息:211本+985硕(非计算机),笔试4出头的分数,面了90分钟,面试官人超好,奈何本人过菜 1、部门介绍 2、自我介绍 3、项目介绍,在项目中承担什么角色,如何完成工作 大数据相关: 4、对大数据开发的理解 5、知道什么常用的大数据开发组件 6、谈谈MapReduce的原理 7、谈谈shuffle的实
-
 大厂实习 网易实习面试经验分享
大厂实习 网易实习面试经验分享面试流程: 1、电话面试:问一下你的基本情况,然后加了个联系方式,发给hr你的作品集,做设计的作品集很重要哦! 2、线上面试:面试的人是我的老大,也就是入职之后带我的,和领导,就介绍一下岗位职责,看你的抗压能力如何 3、笔试:基本上给你的题目是什么就代表你入职之后工作的内容是什么,会先问下你大概多久可以做完,规定时间内给他就好了 4、hr面试:了解一下你的基本情况,谈一下理想薪资之类的,当时我因为