《职业规划》专题
-
ANTLR lexer规则消耗太多
我需要以下令牌: 允许的字符包括大写、小写、数字、空格和连字符 长度不固定(长度必须至少为两个字符) 标记必须至少包含一个空格或连字符 令牌必须以大写、小写、数字、空格或连字符开头和结尾(不能以空格开头或结尾) 下面语法中的ANTLR lexer规则“alphanumericspacehyphen”除了一个情况外几乎都起作用。使用解析器规则“sic”进行测试,以下输入将解析(不带引号): 以下输入
-
在Drools中调试Optaplanner规则
在为我的项目实现了一些规则之后,我做了一个“ScoreConsistencyCheck”,以确保规则得到了正确的实现。 表示实现我自己的方法,该方法将在我提前终止求解或通过配置终止后调用,输出预期分数。该方法的参数是一个实例,基于解决方案的状态计算预期分数,然后将其与来自解决方案实例的“分数”变量的分数进行比较。 当我使用时,它不会抛出异常,但是当我这样尝试时,我有时会在构建启发式或本地搜索的特定
-
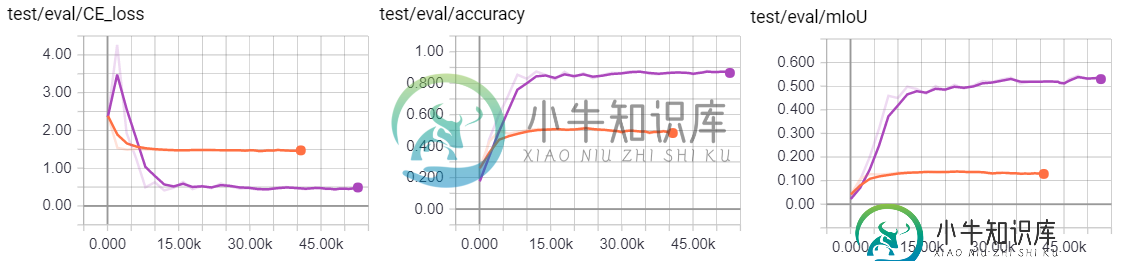 TensorFlow中的批量规范化
TensorFlow中的批量规范化在TensorFlow中执行批量规格化的正确方法是什么?(即,我不想计算连续均值和方差)。我当前的实现基于tf。nn。batch\u normalization(批次规格化),其中x是具有形状的卷积层的输出。[批次大小、宽度、高度、通道数]。我想在通道方面执行批处理规范。 但这种实施的结果非常糟糕。与tensorflow比较。承包商。苗条的batch\u norm显示其票价较低(同样糟糕的培训表现
-
Firebase存储通配符规则
我目前正在使用NodeJS、HTML和Firebase编写一个web站点,用于数据库服务、身份验证和存储。我目前遇到的问题是Firebase存储规则不能按照我对文档的解释工作。 我的Firebase存储实例的目录结构如下所示(明显有假的UID):
-
Laravel 5.2验证规则顺序
我做了一个自定义验证规则,它迭代一个包含键
-
编辑Intellij中的Checkstyle规则
在intellij中是否有一种方法可以编辑checkstyle规则?在Eclipse checkstyle插件中,您可以编辑IDE中的特定规则,它们是IntelliJ的类似插件吗?我尝试下载idea-checkstyle和QA-Plug插件,但这些似乎不能直接编辑checkstyle xml文件。
-
硒自动化规避检测
-
Spring Data JPA@Query具有规范
现在挣扎着与first存在,因为它已经加入了。有没有办法用规范来做到这一点。也因为有两个存在,这是否意味着我需要两个规范。我能在一个规范中实现它吗。
-
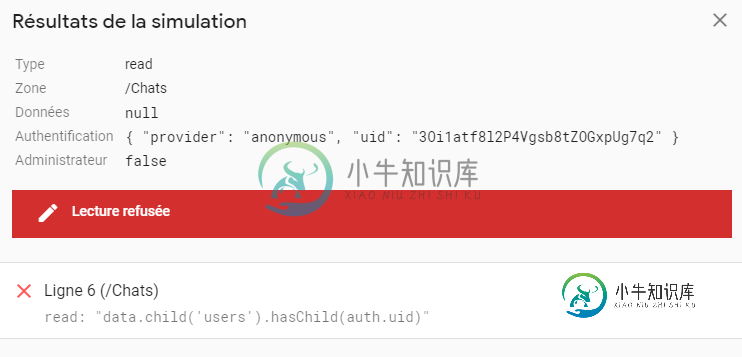 Firebase规则实时数据库
Firebase规则实时数据库我尝试用规则返回用户聊天列表。所以我不知道对话的id。我尝试了几种方法,但都不起作用,因为你必须知道聊天id。 数据库: 规则: 但当我从react本机应用程序访问时。通过身份验证的用户无法访问聊天记录(uid:3Oi1atf8l2P4Vgsb8tZOGxpUg7q2) *读取失败:错误:权限被拒绝/Chats:客户端没有访问所需数据的权限。 规则: 查询:
-
Swagger注释和Swagger规范2.0
我开发了一个带有Swagger注释的REST API。我已经能够展示一个炫耀的ui应用程序的api文档,非常好。 问题:根据我的注释,我试图使用swagger提供的url生成符合该规范的客户端。问题是,它似乎是不兼容的,或者至少,我不知道如何做swagger编辑器读取我的网址,并从那时起,产生客户。但是swagger编辑器向我报告了一些错误... 是否可以将我的带注释的 swagger api 与
-
Java中的Swagger规范验证
iam试图验证一些可能包含swagger规范的字符串。我正在尝试使用swagger解析器。 以下代码不起作用。我只收到消息:“[属性不是]类型” swagger规范是从xml文件中读出的。 这个方法是错误的吗?或者。错误消息的含义是什么?我只想知道字符串是否包含JSON格式的有效Swagger规范。 谢谢你的帮助。 更新:问题已解决 据我所知,如果字符串不是json有效的,就会抛出错误。首先我检查
-
在eslintrc.json中关闭eslint规则
我正在尝试禁用中的。根据文档,相关的规则块如下所示: 在我将升级到2.0版之前,这种方法一直有效,在2.0版中,我的eslint规则只是。 我阅读了eslint文档,其中说我们可以简单地将更改为,尽管我尝试过,但没有成功。 禁用规则的正确方法是什么?我应该引用的文档是什么?
-
PowerMockRunner不应用JUnit类规则
我需要模拟一个类的静态方法,并在测试中使用该模拟方法。现在看来我只能用PowerMock来实现。 我用@RunWith(PowerMockRunner.class)注释类,并用适当的类注释@PrepareForTest。 在我的测试中,我有一个@ClassRule,但在运行测试时,该规则没有正确应用。 我能做什么?
-
Sonarqube:Squid规则自定义/抑制
我花了一天的时间将所有PMD和Checkstyle规则迁移到新的Squid规则,因为PMD/Checkstyle规则被标记为不推荐使用。 规则:BadConstantName_S00115_Check/S00115 我们所有的枚举都是用camelCase而不是CONSTANT_NAME实现的,例如: 比: 规则:MethodCyclomatic复杂性 迁移后,该规则报告所有equals和hashc
-
Java类文件规范语句
Java类文件规范规定: 代码数组给出了实现该方法的Java虚拟机代码的实际字节。 当代码数组读入字节可寻址机器上的内存时,如果数组的第一个字节在4字节边界上对齐,那么表开关和查找开关32位偏移量将是4字节对齐的。(有关代码数组对齐结果的更多信息,请参阅这些说明的说明。)(https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html#