《新浪集团》专题
-
重新绘制不会更新屏幕
我想重新绘制我的屏幕。到目前为止,它所做的只是在第一个屏幕上的头部应该在的地方显示一个点。这很好,但是我在代码中写了我想每秒将头部向下移动10个像素。我正在打印头部应该在的位置,在命令提示符中它显示y值确实在增加。但是在我的屏幕上,头部没有移动。 我尝试过使用revalidate方法,尝试扩展canvas类而不是jframe,我尝试过只为paint方法使用不同的类,我尝试过用paintCompon
-
第11章 新特性 - JDK新特性
1. ENUM枚举 1.1 枚举概述 枚举是指将变量的值一一列出来,变量的值只限于列举出来的值的范围内。举例:一周只有7天,一年只有12个月等。 回想单例设计模式:单例类是一个类只有一个实例 那么多例类就是一个类有多个实例,但不是无限个数的实例,而是有限个数的实例。这才能是枚举类。 格式是:只有枚举项的枚举类 public enum 枚举类名 { 枚举项1,枚举项2,枚举项3…;
-
检查Java集合通用类型是否为空集合
问题内容: 我要实现以下功能: 如何检查向量元素类型? 请注意, 向量可能为空,因此我无法检查第一个元素是“ instanceof”整数还是String … 编辑: 好吧,我脑子里有个念头,我不知道它是否会起作用 我可以按以下方式实现checkType函数: 是否可以检查T是否为整数?! 提前致谢 问题答案: *由于 类型擦除, *泛型类型参数 在运行时不可恢复(某些特殊情况除外)。这意味着在运行
-
给定整数集的子集,其总和为常数N:Java
问题内容: 给定一组整数,如何找到一个总和为给定值的子集…子集问题? 示例:S = {1,2,4,3,2,5}并且n = 7求和为n的可能子集。我试图用Google搜索出很多链接,但不清楚。我们如何在Java中解决这个问题?要使用什么数据结构及其复杂性? 问题答案: 我不会给您任何代码,但会解释它是如何工作的。 从运行循环 对于1中的每个值,其二进制表示中的1表示已选择此值,否则为0。 测试以查看
-
Python分割训练集和测试集的方法示例
本文向大家介绍Python分割训练集和测试集的方法示例,包括了Python分割训练集和测试集的方法示例的使用技巧和注意事项,需要的朋友参考一下 数据集介绍 使用数据集Wine,来自UCI 。包括178条样本,13个特征。 分割训练集和测试集 随机分割 分为训练集和测试集 方法:使用scikit-learn中model_selection子模块的train_test_split函数 以上就是本文的
-
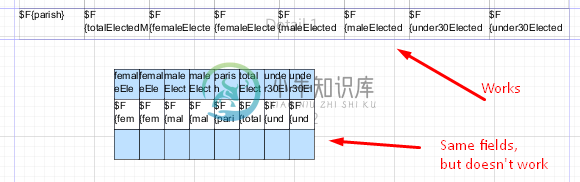 将数据从主数据集传递到表数据集
将数据从主数据集传递到表数据集我正在使用一个表在Jaspersoft Studio 5.6.1中创建简单的报告。 通过 JRBeanCollectionDataSource 从 Java 向此报告发送数据。 在报告中,我已经可以获取此数据 vie 字段:报告- 现在我可以显示输入的数据了。 但如果我想在表中执行,我需要创建数据集(为什么?)并选择“使用用于填充主报告的相同连接”。将相同的字段添加到新数据集没有帮助,也没有为数据
-
Spring集成Java DSL:不断创建和销毁集成流
我的流在数据库中配置,我的程序不断创建和销毁流。 因此,流配置(例如cron配置)可以随时更改。 这些流是用方法IntegrationFlowContext注册的。使用IntegrationFlowRegistration方法注册并销毁。销毁。 流的运行从第0秒开始,可以在任何一分钟开始。销毁和创建新流从每分钟1秒开始。 这是一个好方法吗?当我测试这个时,它起作用了。但我在想,这是一种很好的方法吗
-
Spring集成Java DSL:如何在JUnit中运行集成流?
如何在下面的JUnit类中运行integrationFlow?目前出现了例外情况 因为整合流没有启动。 JUnit类: }
-
结构模式匹配Python-匹配集合/冻结集合
我一直在玩Python 3.10中的结构模式匹配,但不知道如何让它匹配一组。例如,我尝试过: 我尝试过: 以及: 我想有一种方法可以做到这一点,因为我们可以匹配其他对象,我只是缺少正确的语法,但我想不出还有什么其他方法可以尝试。任何帮助都将不胜感激!谢谢
-
Scala将Scala集合转换为Java集合,反之亦然
本文向大家介绍Scala将Scala集合转换为Java集合,反之亦然,包括了Scala将Scala集合转换为Java集合,反之亦然的使用技巧和注意事项,需要的朋友参考一下 示例 当您需要将集合传递到Java方法中时: 如果Java代码返回Java集合,则可以通过类似的方式将其转换为Scala集合: 请注意,这些是装饰器,因此它们仅将基础集合包装在Scala或Java集合接口中。因此,通话.asJa
-
从Firebase异步收集数据:数据集何时完成?
在我目前正在开发的Firebase Android应用程序中,我想提供一个导出特性。这个特性应该允许用户导出一组存储在Firebase中的数据。 我的计划是将所有需要的数据收集到一个中间对象(datastructure)中,该对象可以(重新)用于多种导出类型。 谁有应对这一问题的最佳做法?
-
Java 8收集器可用于Guava不可变集合吗?
问题内容: 我真的很喜欢Java 8流和Guava的不可变集合,但是我不知道如何将两者一起使用。 例如,如何实现将流结果收集到ImmutableMultimap中的Java 8 Collector? 优点:我希望能够提供键/值映射器,类似于Collectors.toMap()的工作方式。 问题答案: 从21版开始,您可以
-
Python:具有生成器的给定集合的功率集[
问题内容: 我正在尝试使用 生成器 在Python中构建给定集合的子集列表。说我有 作为输入,我应该有 作为输出。我该如何实现? 问题答案: 最快的方法是使用itertools,尤其是链和组合: 如果需要生成器,只需使用yield并将元组变成集合: 然后简单地:
-
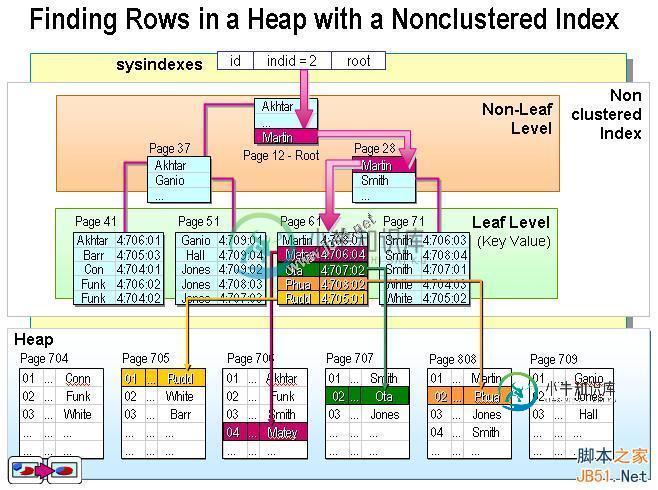 sql 聚集索引和非聚集索引(详细整理)
sql 聚集索引和非聚集索引(详细整理)本文向大家介绍sql 聚集索引和非聚集索引(详细整理),包括了sql 聚集索引和非聚集索引(详细整理)的使用技巧和注意事项,需要的朋友参考一下 聚集索引 一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。 聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索
-
Flink作业集群与会话集群-部署和配置
我正在研究Flink 1.9.1的docker/k8s部署可能性。 我看完了[1][2][3][4]。 目前,我们确实认为,我们将尝试采用工作集群方法,尽管我们想知道社区的这一趋势是什么?我们不希望每个Flink集群部署多个作业。 不管怎样,我想知道一些事情: > 在这两种情况下,Flink的UI都显示每个任务管理器有4个CPU。 如果使用作业群集,如何重新提交作业。我指的是这个用例。你可能会说我