《新浪集团》专题
-
Spring Boot 2集成Brave MySQL-集成到Zipkin中
我正在尝试将Brave MySql检测集成到Spring Boot2.x服务中,以自动地让它的拦截器通过涉及MySql查询的范围来丰富我的跟踪。 当前的Gradle-依赖关系如下 你有什么建议给我如何正确地连接东西吗?
-
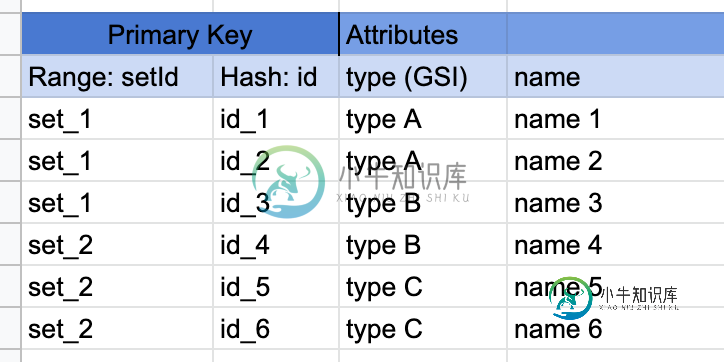 (DynamoDB集合)集合查询是否需要sortKey?
(DynamoDB集合)集合查询是否需要sortKey?我正在制作一些lambda来从dynamoDB表中获取数据。 DynamoDB表具有 复合主键 'setId'作为分区键(范围键)(我用这个词'set'作为名词,就像'group'一样) 'id'作为排序键(散列键) 如果我理解正确, 我可以使用setId来查询,因为DynamoDb通过分区键进行集合。 所以我尝试了这个参数。 但它返回错误 Q. 获取集合是否需要排序键? 提前谢谢! 仅供参考)我
-
如何从集合映射到集合属性?
假设我有以下映射目标。 如何从其他属性的Iterable映射到其他属性? 我可以这样做吗?
-
拉雷维尔为一个集合而收集
我有两个模型,一个用户模型和一个帖子模型。我正在尝试获取在某个日期范围内发布的用户集合。我只是不知道如何将这两个模型连接在一起。两者之间存在一对多的关系。 用户模型: 所以,我想要一个用户集合,其中帖子在日期1之间
-
如何在Spring集成路线中集成Jaxb2Marshaller?
null 如何在transform()步骤中添加Jaxb2Marshaller?
-
在java中求两个多重集的交集
这是我的密码。我们不允许使用方法或数组,我们只是初学者。我的代码在
-
HornetQ集群嵌入时使用JBoss集群吗?
我将使用嵌入在 JBoss EAP 6.2 中的 HornetQ 2.3.12,并且需要一些集群队列。 我是否需要设置 JBoss 集群才能让 JMS 集群由大黄蜂 Q 提供支持,或者大黄蜂 Q 是独立的?根据文档,我认为是后者,因为大黄蜂Q集群是大黄蜂Q的一部分,可以在没有JBoss的情况下存在。 节点通过核心网桥连接,因此部署在每个节点中的应用程序将对队列名称执行本地 JNDI 查找,而无需集
-
分级源集依赖于另一个源集
这个问题类似于使一个源集依赖于另一个源集 这不起作用,因为您不能直接将源集添加为依赖项。建议的方法是: 但是这在eclipse中不能正常工作,因为当我清理gradle build文件夹时,eclipse不能再编译了,因为它依赖于gradle build。此外,如果我更改了主代码,我必须在gradle中重新构建项目,以便更改在Eclipse中生效。 如何正确声明依赖项? 这个 适用于主源代码,但由于
-
使用资源集工作 - 资源集例子
22.7.3.一些 source set 的例子 加入含有类文件的 sorce set 的 JAR: 例22.8.为 source set 组装 JAR build.gradle task intTestJar(type: Jar) { from sourceSets.intTest.output } 为 source set 生成 javadoc: 例22.9.为 source set
-
使用资源集工作 - 资源集属性
22.7.1.Source Set 属性 下表列出了 Source Set 的一些重要属性, 更多细节请查看 SourceSet 的 API 文档. 表22.9.java 插件- Source Set 属性 配置名称 类型 默认值 描述 name String (read-only) Not null 用来识别source set的名称 output SourceSetOutput(read-on
-
为已有 TiDB 集群部署异构集群
本文档介绍如何为已有的 TiDB 集群部署一个异构集群。 前置条件 已经存在一个 TiDB 集群,可以参考 在标准 Kubernetes 上部署 TiDB 集群进行部署。 部署异构集群 什么是异构集群 异构集群是给已经存在的 TiDB 集群创建差异化的实例节点,比如创建不同配置不同 Label 的 TiKV 集群用于热点调度或者创建不同配置的 TiDB 集群分别用于 TP 和 AP 查询。 创建一
-
第6章 集合框架 - 集合工具类
1. Collections工具类 Collections类概述 针对集合操作 的工具类,里面的方法都是静态的,可以对集合进行排序、二分查找、反转、混排等。 Collection和Collections的区别 Collection:是单列集合的顶层接口,有子接口List和Set。Collections:是针对集合操作的工具类,有对集合进行排序和二分查找等方法 Collections常用方法 pub
-
第6章 集合框架 - 集合的遍历
集合的遍历 在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口Iterator。Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。 Iterator迭代器对
-
集群部署 - 可扩展高可用集群
本文档提供一个可扩展、高可用的 Seafile 集群架构。这种架构主要是面向较大规模的集群环境,可以通过增加更多的服务器来提升服务性能。如果您只需要高可用特性,请参考3节点高可用集群文档。 架构" class="reference-link"> 架构 Seafile集群方案采用了3层架构: 负载均衡层:将接入的流量分配到 seafile 服务器上。并且可以通过部署多个负载均衡器来实现高可用。 Se
-
集群部署 - 3节点高可用集群
本文档介绍用 3 台服务器构建 Seafile 高可用集群的架构。这里介绍的架构仅能实现“服务高可用”,而不能支持通过扩展更多的节点来提升服务性能。如果您需要“可扩展 + 高可用”的方案,请参考Seafile 可扩展集群文档。 在这种高可用架构中包含3个主要的系统部件: Seafile 服务器:提供 Seafile 服务的软件 MariaDB 数据库集群:保存小部分的 Seafile 元数据,比如