《2024找工作》专题
-
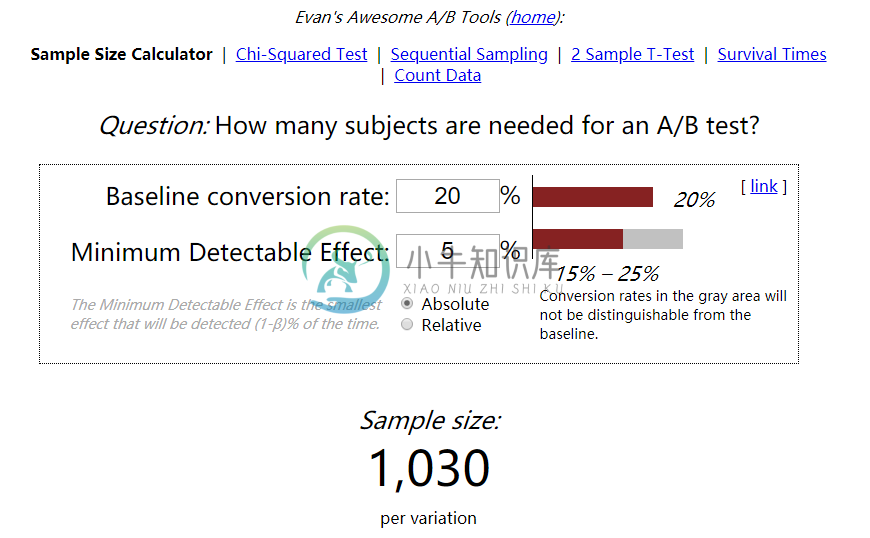 A/B测试如何工作?
A/B测试如何工作?主要内容:数据采样,置信区间可以使用统计信息和分析来监控访问者的操作,以确定产生更高转换率的版本。 A/B测试结果通常以精美的数学和统计术语给出,但数字背后的含义其实很简单。 有两种重要的方法可以通过它们检查A/B测试的转换率 - 数据采样 置信区间 下面详细讨论这两种方法。 数据采样 样本数量取决于执行的测试次数。 转化率的计数称为样本,收集这些样本的过程称为采样。 示例 假设您有两种产品A和产品B,想要根据市场需求收集样
-
@CacheLookup如何在WebDriver中工作?
问题内容: 我不确定我是否了解缓存原理: 如果使用这种注释方式,则将使用ElementLocator,并且第一次引用该字段时,将通过ElementLocator 找到并缓存该元素,以便下次我们引用它时,将从缓存中将其返回。 它看起来取决于ElementLocator和PageObject实例的生存期。 而且它与直接呼叫无关。 我假设,WebElement就像元素的指针/引用,对吗?这样,如果元素在
-
测试每周的Cron工作
问题内容: 我在cron.week目录中有一个文件。 有没有办法测试它是否有效?等不及1个星期 我以root身份在Debian 6上 问题答案: 只需执行cron的操作,即可运行以下命令: …或下一个,如果收到“不是目录:-v”错误: Option 在运行脚本之前先打印脚本名称。
-
GCC libm无法正常工作
问题内容: 我有一个调用sin,cos和acos的ac程序。编译时出现以下错误: 我知道当您不使用-lm gcc标志时这很常见。我正在使用此标志。我这样称呼GCC: 当我在其中一台计算机上进行编译时,这可以正常工作。我能想到的唯一区别是,它不能在x86_64上运行,而可以在其上运行的计算机是i686。两者都是Ubuntu。文件libm.a存在于无法使用的计算机上,并且我没有收到任何错误消息称无法找
-
默认的Eclipse工作目录
问题内容: 是否可以在Eclipse 3.4.1中设置默认的工作目录?默认情况下是: $ {workspace_loc :(项目名称)} 但我希望它像 $ {custom_var} 对于每个类,我可以将运行配置->参数->工作目录更改为“其他”,但最好更改默认值。我有很多需要从该特定目录运行的类。 问题答案: 您可以做的一件事是设置一个启动配置,然后右键单击它,然后选择“重复”。这将保留所有参数。
-
@param到底如何工作-Java
问题内容: 注释如何工作? 如果我有这样的事情: 将如何影响testNumber?它甚至会影响testNumber吗? 谢谢。让我知道我是否使用错了。 问题答案: 不会影响电话号码。它仅用于制作javadocs。 有关Javadoc的更多信息:http : //www.oracle.com/technetwork/java/javase/documentation/index-137868.htm
-
LD_PRELOAD无法按预期工作
问题内容: 考虑以下可以在任何程序执行之前预加载的库: 问题是,尽管总是调用全局变量的构造函数,但对于某些程序却不调用析构函数,例如: 对于其他一些程序,按预期方式调用析构函数: 您能解释一下为什么在第一种情况下不调用析构函数吗?编辑:上面的问题已得到解答,即程序可能会使用_exit(),abort()退出。 然而: 有没有办法在预加载的程序退出时强制调用给定函数? 问题答案: 具有作为其初始化代
-
CheckBoxTableCell changelistener无法正常工作
问题内容: 我正在尝试向我的CheckBoxTableCells添加一个更改侦听器,但它似乎无法正常工作。我以CheckBoxes为例,说明它们的工作方式相同。但是,当我更改其值时没有输出。如何将一个正确地添加到checkboxtablecell? 当前代码: 问题答案: 的是从继承,它只是指示是否在UI部件中选择。由于您可能没有启用单元格选择,因此该单元格永远不会被选中。无论如何,这都不是您要找
-
Jenkins Multibranch Pipeline工作区配置
问题内容: 我碰到JENKINS-38706。由于它已经开放了一段时间,所以我正在尝试解决它。 我的问题是我正在运行多节点管道,其中一个节点是Windows从站,具有255个字符的路径限制。 因此,我尝试更改Windows从属阶段的工作区,而不是使用多分支管道使用的C:\ jenkins \ workspace \ job-branch- randomcharacters,而是尝试将其移至c:\
-
mysqli_result工作不正常?[副本]
数据库中有一个表'hit_count'只包含一列'count',我正尝试在该表中统计用户的命中数。问题是,每当我运行这段代码时,它会显示一条错误消息“Fatal error:Call to undefined function mysqli_result()”。请救命!!
-
python爬虫的工作原理
本文向大家介绍python爬虫的工作原理,包括了python爬虫的工作原理的使用技巧和注意事项,需要的朋友参考一下 1.爬虫的工作原理 网络爬虫,即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址
-
SQL LIKE实际如何工作
问题内容: 例如,当我有这样的字符串时: 当我像这样使用SQL时: 服务器到达JDK时会发生什么?它会停止并执行SQL,还是遍历字符串的其余部分然后执行SQL? 当我在与OR连接的SQL语句中有多个LIKE子句时,还会发生什么情况?它可能时会在第一个LIKE子句处停止吗? 编辑:我有这样的SQL。这可能是矫kill过正,但值得一提…每个变量都包含一个表列的LIKE子句循环。它们之间有“或”。我是否
-
python`print`不能循环工作
问题内容: 我在一起有多个循环,而在最内部的循环中有一个睡眠。例如: 如果您运行该代码,则可能需要等待1秒钟然后再次休眠直到结束,才能获得价值。 但是结果是不同的,它等待10秒钟并打印整行,然后再次等待打印下一行。 我发现打印末尾的逗号导致了此问题。我该如何解决? 问题答案: 由于存在逗号,因此输出缓冲到a为止。 您应在每次打印或使用后冲洗并冲洗缓冲区。 定义您的打印方法: 在行的末尾打印一个
-
Python re.findall()无法正常工作
问题内容: 我有代码: 这返回 如果我们有 我们得到 为什么有区别?为什么(第一次)没有区别? 谢谢! 问题答案: 让我解释一下您在做什么: 您正在创建一个正则表达式,它将查找或,然后尝试查找是否还有更多或之后的内容,并且它将一直寻找或直到找不到为止。因为您希望捕获组仅返回,否则您只会得到最后一个捕获/找到的组。 但是,如果你有一个这样的字符串:你会得到,因为你在字符串先来看看,找到,然后你看多了
-
NumPy Sum(带轴)如何工作?
问题内容: 我已经学会了如何根据自己的好奇心来工作。 似乎最简单的功能最难翻译为代码(我理解代码)。对每种情况的每个轴进行硬编码很容易,但是我想找到一种动态算法,可以在任何轴上以n维求和。官方网站上的文档没有帮助(仅显示结果而不显示过程),并且很难浏览Python/ C代码。 注意: 我确实弄清楚了当对一个数组求和时,指定的轴是“已删除”,即,形状为(4,3,2)且轴为1的数组的总和会得出形状为的