《大数据开发工程师》专题
-
 平安科技 大数据开发
平安科技 大数据开发2023/10/10 平安科技 大数据开发(37min) (1)自我介绍 (2)对于平安科技的数据开发岗的理解和认为它是做什么的?和自己的契合度是怎么样的? (3)数据库学习到哪些东西,学了多久,什么时候学的,有实践过吗? (4)sql分哪几类,违反主键约束会出现什么问题,索引什么情况下回失效,有自己去安装过吗?(之前没准备数据库的内容,答得很差,后边的面试才好好看了数据库的东西) (5)使用sq
-
 某厂外包-大数据开发
某厂外包-大数据开发1.自我介绍 2.描述一张表的设计流程 3.针对简历提问,问的不算难 4.kafka的用法及途径 5.redis的几种类型(我有写,但是忘了), 6.有没有bi可视化经验。 ----------------- 是的,没有看错,简历上写的就会可能提问,并不会针对你。
-
 字节大数据开发一面
字节大数据开发一面1.自我介绍 2.实习介绍 3.实习工作内容下游使用方主要有那些? 4.AI团队数据支持 他们使用这个数据做的什么 5.除了对表的支持之外,是否在计算层面做过一些优化 6.boradcast join和sortmergeJoin的区别和 使用场景的不同 然后面试官开始说,我觉得概念你应该都会,我就不问你了,所以我后面会从场景的角度去考验你的技术理解,本人听到这里心凉了半截,因为两段实习全是离线,这
-
 京东-大数据开发凉经
京东-大数据开发凉经110分钟,全程无项目和算法,全是八股深挖,被拷打惨了 1、谈一谈你对java面向对象的理解,什么时候用接口,什么时候用抽象类,从本质上讲一下区别? 2、都有了解过哪些设计模式?创建对象的设计模式有哪些?工厂模式和建造者模式分别在什么场景下使用,举一个具体的例子 3、java的hashmap在1.8之前链表中采用的头插法的方式,为什么1.8之后改成尾插法?头插法的方式可能会极限情况连成一个环,举一
-
 PCG大数据后台开发(45min)
PCG大数据后台开发(45min)腾讯二进宫,秒挂,简单题没写出来,太菜了。。。 自我介绍 项目相关 介绍一下java的反射 介绍一下mysql引擎 MyISAM引擎什么时候用 讲一下垃圾回收 讲一下集合 讲一下hashmap 算法题:大数翻转 (乐死了,这么简单的题没做出来,我转了字符串双指针超时) 反问: ∽具体有什么业务 提供大数据内容服务balabala ∽技术栈有什么 大数据开发岗spark之类,后台开发岗golang
-
 shein大数据开发实习生
shein大数据开发实习生1.自我介绍 2.实习最大收获 3.odps平台的性能调优与spark的性能调优的共同点和差异点 5.spark的countdistinct算子优化 6.bitmap作用在expload的作用是什么? 7.小文件过多的影响 8.sql countdistinct优化代码手写 9.反问 #大数据开发##数据人的面试交流地#
-
 美团大数据开发实习
美团大数据开发实习一面——60mins 自我介绍 拉链表的制作,数据量有多少,为什么不用快照表呢 项目有哪些表 数仓分层有哪些,具体做了什么,数仓分层作用 怎么设计表,怎么建模,DIM DWD层的主题分了哪些 如何做的可视化 什么是数据倾斜,数据倾斜的解决方案 Hadoop和spark的区别 Spark的shuffle流程是怎么样的 对哪些数据库了解 Shuffle有哪几种类型 在shuffle的过程中会进行排序吗
-
 脉脉,大数据开发实习
脉脉,大数据开发实习一面:(1h) 1.自我介绍 2.选一个熟悉的项目介绍一下吧 3.看你简历上写了进行过数仓的搭建,那你说一下数仓分几层合适? 4.每一层干了那些事儿? 5.你说一下数仓为何要进行分层? 6.数仓的建模方法知道吗? 7.指标分类有哪些?(回答的是原子指标,派生指标,衍生指标) 8.你的ods层为何选择gzip压缩呢? 9.除了gzip压缩还有哪些压缩方法?介绍他们的区别?10.项目中你的hive表使
-
大数据工程师技能图谱
大数据通用处理平台 Spark Flink Hadoop Drill 分布式协调 ZooKeeper 分布式存储 HDFS Alluxio(tachyon) Ignite 存储格式 Parquet ORC CarbonData Kudu 数据库 HBase 资源调度 Yarn Mesos Kubernetes 工作流调度 Oozie Azkaban 机器学习工具 Mahout Spark Mlib
-
 百度-大数据工程师一面
百度-大数据工程师一面#百度#面试官很好,总体感觉问的比较简单,但是好久不看八股感觉很多都忘记...理解还是比较浅层,一些实战方面的内容还比较欠缺...要努力了!!!
-
 凉经 24届 tx 软件开发-数据工程
凉经 24届 tx 软件开发-数据工程摘要 数据工程的全流程(数仓建设-数据接入-数据运维-数据分析-数据挖掘)的各个阶段都有涉及... 自我介绍,问了我在百度和蔚来做的工作(数仓),对简历项目中对数据倾斜的发现、解决方法和效果 回答是通过sparkUi中task的输入量和运行时间发现,解决方法是用count估算不同维度下各value的数据条目,然后数量最多的top key进行再赋值后与其他表join 感觉这个地方可以从spark运行
-
 腾讯 软件开发-数据工程 是KPI吗?
腾讯 软件开发-数据工程 是KPI吗?不知道是不是KPI,感觉这个过程也有点奇妙。 刚从腾讯云智回来,9月底的时候,突然就邀请我面试了?!没有打电话问时间。而且最重要的是,我不符合他的岗位要求呀,我不会大数据的东西呀,简历上也没写,结果他突然捞我了。那时候我就已经开始担心是不是KPI。 不过我那时候才刚回校太累了,就延期,好家伙结果面试官直接给延期到国庆后。 然后面试那天,面试官提前15分钟进入会议。我那时候本来在等时间到,结果会议突
-
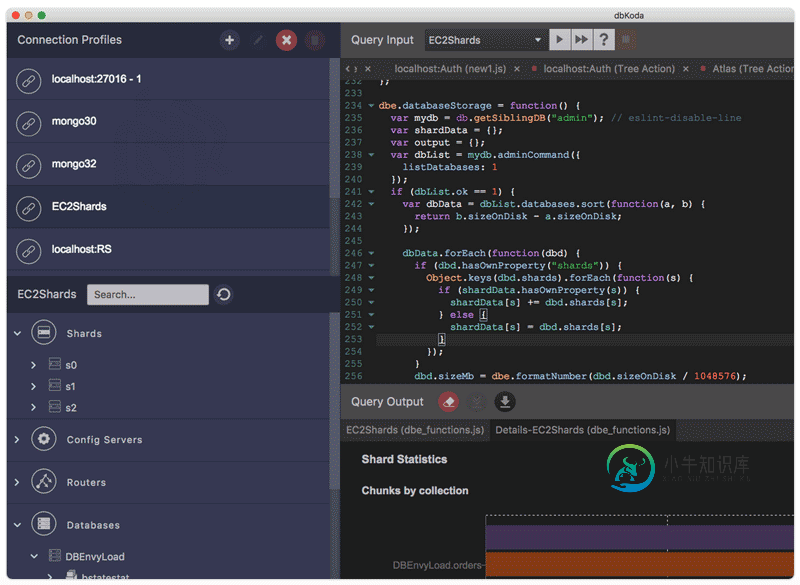 MongoDB开源数据库开发工具dbKoda
MongoDB开源数据库开发工具dbKoda本文向大家介绍MongoDB开源数据库开发工具dbKoda,包括了MongoDB开源数据库开发工具dbKoda的使用技巧和注意事项,需要的朋友参考一下 Southbank Software公司最近发布了 dbKoda 0.6.0 ,这是该软件的 首个发布版 。dbKoda是一款开源的 MongoDB 开发工具,采用JavaScript、 React 和 Electron 开发。下图显示了dbKod
-
 神策数据-后端开发工程师 3面面经
神策数据-后端开发工程师 3面面经一面 8.30 50min 1.java常用的容器,数组和链表区别?hashmap,put的过程 2.解决hash冲突的方式?(开放定址法(线性探测法、平方探测法前后寻找)、链地址法、建立公共溢出区) 3.上面解决hash冲突引出了threadlocal,threadlocal为什么需要要用弱引用?(把源码从头到尾讲了一遍,面试官说理解的不错) 4.AQS用过吗?提供哪些接口? 5.TCP、Ip
-
 oppo 数据开发工程师 1 2 3面 已意向
oppo 数据开发工程师 1 2 3面 已意向一面 8.9 30min 自我介绍 职业规划 维度建模方法有哪些 数仓理解 hive有哪些复合数据类型 hive与关型数据库有什么区别 hive数据倾斜 kafka高吞吐 flume有哪些类型的channel,如何选择 大规模用户下,实际业务进行中会有哪些难点,需要怎么解决 反问 面试官人挺nice,问的问题都耐心解释了 综合面 8.11 20min 没问技术,主要太菜了,跟hr面有点像 hr面