《大疆》专题
-
mysql 大表批量删除大量数据的实现方法
本文向大家介绍mysql 大表批量删除大量数据的实现方法,包括了mysql 大表批量删除大量数据的实现方法的使用技巧和注意事项,需要的朋友参考一下 问题参考自:https://www.zhihu.com/question/440066129/answer/1685329456 ,mysql中,一张表里有3亿数据,未分表,其中一个字段是企业类型,企业类型是一般企业和个体户,个体户的数据量差不多占50
-
infinispan文件存储大小与数据大小不成比例
我编写了一个小型infinispan缓存PoC(下面的代码),以尝试评估infinispan的性能。运行它时,我发现对于我的配置,infinispan显然无法从磁盘中清除缓存项的旧副本,导致磁盘空间消耗比预期的要多几个数量级。 如何将磁盘使用率降低到实际数据的大致大小? 以下是我的测试代码: 这是infinispan配置: Infinispan(应该是?)配置为写入缓存,其中包含RAM中的20个最
-
使用比率而不是大小添加图片大小-WordPress
我正在开发一个WordPress主题,我需要通过内置媒体上传器上传相同比例的图像。我知道,通过定义高度和宽度并使用裁剪,这很容易做到。 问题是,我想将这些图像用于全屏滑块,所以将所有图像降到300x200作为示例是行不通的。我想保留尽可能多的默认大小的图像,而裁剪它的比例。 WordPress带有add_image_size()功能,但我更像是在寻找add_image_ratio()功能。这有可能
-
什么决定了IE11中canvas html元素的最大大小?
我正在尝试使用画布元素,但高度不能超过像素。如果我尝试使用像素,我会在IE11中得到。这在Chrome中工作正常。画布用于PDF生成,我真的没有时间将生成移动到服务器。 我在谷歌上搜索了一下,看起来大小可能会因平台和浏览器的不同而有所不同。 是浏览器分配的内存和内存设置决定了这一点吗? 编辑:我在这里找到了一些信息: 看起来我可以有两倍的尺寸。也许这只是为了IE9。
-
如何将大口观察和大口注射结合起来?
我正在尝试使用gulp-watch和gulp-inject来构建我的节点Web应用程序。然而,一旦gulp-watch参与进来,涉及gulp-inject的构建步骤似乎就不起作用了。原因似乎是流永远不会结束,gulp-inject不知道何时开始。 我的gulpfile如下所示:
-
在使用windows的netbeans中忽略的最大内存大小
我不确定这是不是一个有效的问题! 我已经在windows xp机器上安装了netbean。然而这台机器的内存非常有限。因为Netbean使用了大部分内存,所以我想限制Netbean使用的内存大小。 从这一页上我可以看到,我可以在配置文件中使用开关或开关/etc/netbeans。形态。 所以我就这样改了: 我尝试了两个选项,但是Netbean要么不启动,要么在启动时不支持新策略。当它启动时,我在任
-
连接池打开的连接数超过最大池大小
嘿,我正在使用Glassfish开源v4,我遇到了一个奇怪的问题。 我在管理控制台中定义了到Oracle 11g的JDBC连接池,并设置了: 初始和最小池大小:500 最大游泳池大小:1000 池大小调整数量::750 我已经为这个连接池创建了一个特定的用户。然而,有时当我检查数据库中打开的连接时,我发现有1000多个连接(我看到的最大连接数是1440个) 当发生这种情况时,任何查询尝试都会失败,
-
Android:创建更大图标的更大浮动操作按钮
我想创建一个更大的浮动操作按钮(FAB),比通常的56 dp更多,里面有一个更大的图标。(出于我的目的,图标永远不会是不言自明的,所以我将创建一个包含短文本的png文件,并将此png用作图标。 增加晶圆厂的大小效果很好:<br>因为我不使用迷你浮动操作按钮,所以我重新定义了迷你按钮的大小 在我的布局xml中,我指定: 并且在尺寸上。xml i重新定义了小型晶圆厂的大小: 然而,我没有设法在FAB上
-
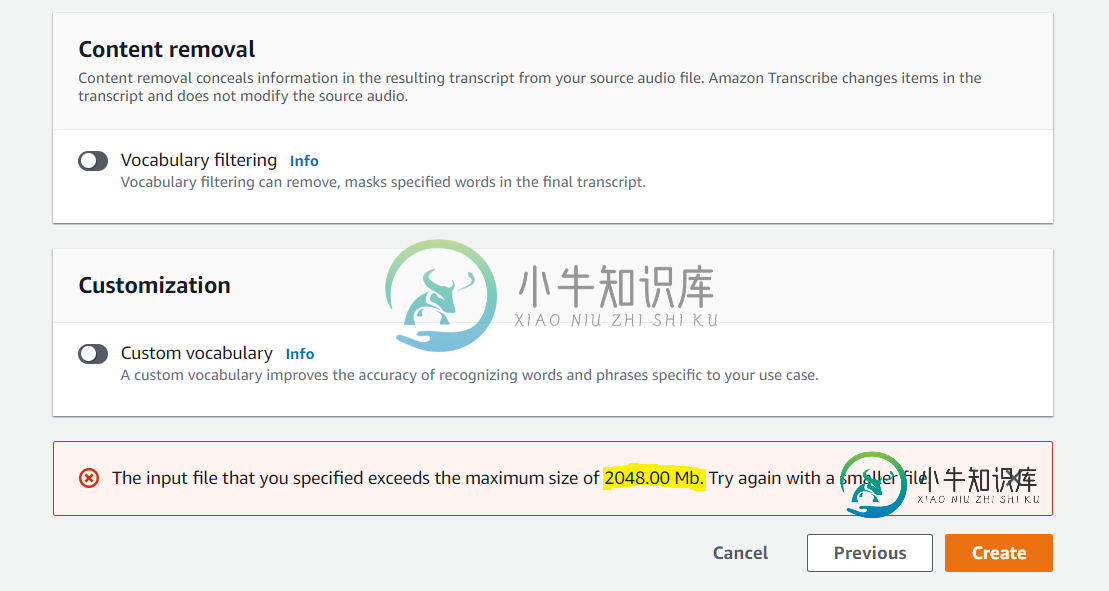 Amazon转录作业文件超过了2048.00Mb的最大大小
Amazon转录作业文件超过了2048.00Mb的最大大小我试图用位于S3上的输入文件创建一个Amazon Transbe作业,该文件的大小是4.3GB,当我试图创建作业时,会显示这个错误。 我可以用我的视频做什么?我应该转换视频,提取音频,还是有什么方法可以用一些AWS服务来做
-
直接分配给老一代的巨大对象的大小
最近我一直在阅读Java不同世代的对象分配。大多数时候,新对象在伊甸园(年轻一代的一部分)中分配,然后如果满足以下任何标准,它们就会晋升为老一代。 (1) 当从伊甸园(或)另一个幸存者空间(从)复制对象时,对象的年龄已达到寿命阈值 (2)幸存者空间(到)已满 但是也有一种特殊情况,即对象直接在旧一代中分配,而不是从年轻一代中提升。当我们试图创建的对象很大(可能是几个MB的数量级)时,就会发生这种情
-
与Springboot大摇大摆3:无法推断出你的基地
我使用Springboot大摇大摆3: 我对所有endpoint使用默认的前缀。 这就是我如何配置我的SwaggerConfig: 当我尝试访问我的swagger-ui 我得到一个弹出窗口,其中包含此消息要求我定义位置。 当我手动输入前缀:< code>http://myhost/api时,一切正常。 任何想法如何定义我的REST API前缀吗?
-
Java进程占用的内存超过其最大堆大小
PS:有时我会从java代码执行shell脚本。会不会导致这类问题?
-
求给定整数集的最大完美子集的大小
给出不同整数的列表 我的想法:< br >一种简单的方法是一个接一个地选择一个元素,看看它形成的完美子集的大小,然后我们可以简单地返回最大值。这将是计算密集型的。< br >有什么好的解决方案吗
-
Java8-根据大小改进大量文件的排序时间
我使用java数组列表按大小对目录中的文件进行排序&&如何在java中按元素大小对ArrayList进行排序? 我的问题是实现比较器的最佳方式是什么,这样排序会更快?我被告知100K文件的排序应该在几秒钟内完成,而不是在几分钟内,因为文件的大小是长的。是否有更好的方法来实现比较器? null 可以观察到,在20K之后,排序需要几分钟。我有什么建议可以降低排序时间吗? 我还查阅了https://do
-
雪花存储过程中的最大JavaScript字符串大小
Snowflake文档指出,VARCHAR列仅限于16 MB未压缩的https://docs.Snowflake.net/manuals/sql-reference/data-types-text.html#data-types-for-text-strings Snowflake文档指出,VARCHAR数据会自动转换为JavaScript字符串数据类型。 https://docs.Snowfla