《四方伟业》专题
-
java.lang.System.CurrentTimeMillis()替换方法
除了重新编译之外,是否有任何方法可以将调用替换为我自己的调用? 1#正确的方法是使用对象和抽象时间。 即使这只适用于Hotspot禁用的,并且我们成功地使用了代码,但它并不“持久”于外部库。这意味着您必须在任何地方对其进行嘲弄,因为代码不在我们的控制范围内,这是不可行的。下的所有代码都返回0毫厘(如示例所示),但将返回实际的系统毫厘。 3#在启动时使用(已编辑)重新声明 虽然可能,并且可以创建/更
-
方法有问题
好的,我有一个课堂作业,为老师写的一个石头,纸,剪刀程序创建3个预先确定的方法。但是,当我运行程序时,它会连续多次运行这些方法。我把代码看了好几遍,还是弄不明白问题所在。 下面是老师提供的部分课程: 以下是该程序的示例会话: 欢迎来到石头,纸,剪刀! 你想打几局?1输入你的选择:岩石电脑选择纸张输入你的选择:岩石输入你的选择:岩石电脑赢!
-
 矩阵方括号
矩阵方括号我使用的是JavaSwing,我需要显示一个带有方括号的矩阵(普通方括号,就像我们在数学中使用的跨越多行的方括号),矩阵大小不是固定的,它取决于输入。 下面是我用来显示矩阵的代码: 所以我正在搜索如何做到这一点,我找到了这个链接https://docs.oracle.com/javase/tutorial/uiswing/components/border.html但它不包含我需要的括号,也找到了
-
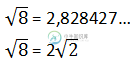 简化平方根
简化平方根假设我要计算8的平方根。如下所示,有两种方法可以显示结果: 我认为获得第二个解决方案的最好方法是: 我想在我的Java应用程序中尝试do display 2√2而不是2828 427...所以我想按照这些步骤开发一个类。让我们考虑8的平方根。 null 我想我可以在一个数组中存储每个基数的指数,然后尝试以某种方式导出它。你有什么建议吗?
-
未知CRC方法
对于上面的modbus轮询查询,我没有得到哪个是crc值,以及使用了什么类型的crc。它是怎么来的,77是设备的id。请指引我。 我从轮询设备得到以下响应
-
 阅读方程式
阅读方程式我想读取word/docx文件的数据并保存到我的数据库中,需要时我可以从数据库中获取数据并在我的html页面上显示我使用ApachePOI读取docx文件中的数据,但它无法获取公式,请帮助我!
-
Java Scanner next() 方法
这是来自Java的Scanner next()方法的解释: 此方法可能会在等待输入扫描时阻塞,即使先前调用hasNext()返回true。 如果调用了hasNext(),这个方法如何等待用户输入?如果我们调用hasNext()并返回true,我们知道有下一个标记,那么next()方法是如何以及为什么这样做的?
-
Kotlin方法重载
以下声明在科特林是合法的。 作为字节码,我们得到: 也可以从Kotlin调用这两个方法。 当我试图从Java调用它们中的任何一个时,问题就出现了: 模棱两可的调用。两种方法都匹配… 如何避免这样的问题?如何处理这些方法?若第三方kt库也有同样的问题怎么办? 上面的例子是一个合成的例子。
-
JAVAawt。Graphics2D repaint()方法
我遇到了两个不同的问题一个是一般的Graphics2D,另一个是具体的repaint()方法。 首先是repaint()问题。我有一个基于用户选择的时间间隔更新的图表,时间间隔可以从1秒到几分钟不等。问题是一旦调用了repaint()方法,它就会在代码的每一次迭代中不断地回忆自己,而不仅仅是在我想要的时候。有人知道为什么会这样吗?如何阻止它?我试着把我的代码放在一个带有标志的if语句中,但是一旦标
-
libgdx:呈现方法
我想我不明白render方法是如何工作的。 从我在网上读到的/在youtube教程上看到的,我发现render方法是一个循环函数,您可以使用它来保持游戏的更新和读取用户的输入。当您想要在屏幕中绘制一些东西时,您可以使用此方法,并且在绘制任何东西之前清除屏幕。 但是如果我想要静止地绘制一些东西,那么在render方法之外绘制它不是更好吗(这样计算机就不必多次清除屏幕并重新绘制所有东西)?我错过了什么
-
 方正璞华4.10
方正璞华4.101、自我介绍 2、项目 - 讲一下第一个项目的内容 - 为什么使用WebSocket协议,断了怎么办? 3、平时会使用Docker干什么?想做测试吗? 我回答不想,然后就结束了,踏马的 明显感觉到面试官想下班了,随便问两句就结束了,抽象
-
监控方案 - cerebro
cerebro 这个名字大家可能觉得很陌生,其实它就是过去的 kopf 插件!因为 Elasticsearch 5.0 不再支持 site plugin,所以 kopf 作者放弃了原项目,另起炉灶搞了 cerebro,以独立的单页应用形式,继续支持新版本下 Elasticsearch 的管理工作。 项目地址:https://github.com/lmenezes/cerebro 安装部署 单页应用
-
ElasticSearch - 监控方案
Elasticsearch 作为一个分布式系统,监控自然是重中之重。Elasticsearch 本身提供了非常完善的,由浅及深的各种性能数据接口。和数据读写检索接口一样,采用 RESTful 风格。我们可以直接使用 curl 来获取数据,编写监控程序,也可以使用一些现成的监控方案。通常这些方案也是通过接口读取数据,解析 JSON,渲染界面。 本章会先介绍一些常用的监控接口,以及其响应数据的含义。然
-
扩展方案 - fluent
Fluentd 是另一个 Ruby 语言编写的日志收集系统。和 Logstash 不同的是,Fluentd 是基于 MRI 实现的,并不是利用多线程,而是利用事件驱动。 Fluentd 的开发和使用者,大多集中在日本。 配置示例 Fluentd 受 Scribe 影响颇深,包括节点间传输采用磁盘 buffer 来保证数据不丢失等的设计,也包括配置语法。下面是一段配置示例: <source> t
-
扩展方案 - heka
heka 是 Mozilla 公司仿造 logstash 设计,用 Golang 重写的一个开源项目。同样采用了input -> decoder -> filter -> encoder -> output 的流程概念。其特点在于,在中间的 decoder/filter/encoder 部分,设计了 sandbox 概念,可以采用内嵌 lua 脚本做这一部分的工作,降低了全程使用静态 Golang