《龙湖集团数字科技》专题
-
 美团timeline
美团timeline8.22 一面 8.27 二面 9.3 oc 意向 一面: 大部分都是基础八股很简单。记不到太多了,只记得下面零零碎碎的。 1. 谈谈对分库分表理解。 2. redis的持久化讲讲 手撕:分割ip地址,dfs的做法 二面: 二面基本上是对实习经历的全面问答,自己做的项目也基本上没有问。持续问了40多分钟,然后做了一道题。 1. kafka为什么吞吐量那么高,速度快,从原理解释一下。这个不会,没用过
-
 美团ai
美团ai发面经,攒人品 get和post区别 Linux分区 Redis acid 如何设计一个积分系统,鼓励机制 学习方法和工具。 就记得这么多了。我虽然是golang,但是对Java语言特性了解更深一些,所以选的Java。😱
-
 美团 timeline
美团 timeline美团 搜索推荐 oc时间线 4.19 下午一面, 晚上约二面 4.23 晚上二面 4.26 下午HR电话+offer
-
 美团 大数据开发 一面(凉经)
美团 大数据开发 一面(凉经)视频面,1h 吐槽:我8.11投递的岗位...八月底做完的笔试....10.21给我发邮箱约面,也不知道前面是哪个大佬拒了offer然后把我给捞上来了 但是,面试官人很好啊~面试体验很好~ 虽然我很多没答上来只能说分治思想贯穿了全程... 无自我介绍 实习 由于我有数据开发相关的实习,所以前30min各种问实习 做了哪些工作,怎么做的,任务挂了怎么办,怎么做的清洗,用的啥语言,用的是啥架构/工具?
-
 美团23春招面经~数据开发
美团23春招面经~数据开发陆续分享点面经 虽然大部分都被挂了hh 希望能帮到大家 3.15 一面 1.自我介绍 2.题外话 怎么看待数仓和算法的联系 3.项目 4.介绍一下对大数据技术生态的了解 5. 怎么理解spark和hive 6.hive的逻辑架构 7.MR的流程 8.整个MR有几次排序 9.spark的shuffle 10.怎么确定spark分解成多少个task,即spark任务的并行度怎么指定 11.stage的
-
 美团大数据岗实习一面 4.14
美团大数据岗实习一面 4.141.自我介绍问项目细节。说亮点,没啥问的。 2.考察map、shuffle、reduce执行过程 3.考察sql 语句逻辑上执行过程,出个题引导。 4.问string常量池三个场景,串相加判断是否相等 5.最后只留10分钟给我做算法题,蛇形矩阵。。 就问了数据库Java几个概念。啥八股文也没问,项目随便问了下。KPI面吧。最后问了下只有4个hc。。。。。
-
 美团机器学习数据挖掘oc
美团机器学习数据挖掘oc感谢团子解救,笔试面试实在太累了,暑期就到此为止吧
-
 美团数据开发暑期实习Timeline
美团数据开发暑期实习Timeline岗位:软件开发工程师-数据开发方向 部门:核心本地商业-基础研发平台 技术岗位处女面,运气挺好,没有被问到完全不会的题,感谢团子缓解我的焦虑 4.30 一面(60min) 1.自我介绍 2.介绍项目架构,数据源等 3.项目中遇到的难点 4.数仓为什么要分层,各层的职能 5.讲一下项目中提到的零点漂移问题 6.hive结构, 7.hive优化 8.数据倾斜 9.tcp三次握手 10.进程和线程的区别
-
 美团 数据研发工程师 面经
美团 数据研发工程师 面经到店业务 有点久远一直忘了写,就记得这么多 一面: 1、自我介绍 2、比赛中遇到的难点 3、实习中做的项目,聊项目细节 (大部分时间都在问这个) 我好像很多面经都这么简略的写,这次写细点儿哈,里面涉及到的一些知识点,具体项目就不聊了 数仓模型设计方法 数据质量如何判断 如何保障下游查出时间 对于重要程度不同的任务如何合理分配资源 dwd层建模方法,考虑哪些东西 spark任务调参逻辑和常用参数 c
-
在pandas中将长整数转换为字符串(以避免使用科学符号)
我希望以下记录(当前显示为3.200000e 18,但实际上(希望)每个不同的长整数),使用pd.read_excel()创建,以不同的方式解释: 目前,它们似乎以科学符号字符串的形式出现: 然而,更糟糕的是,我不清楚这个数字是否已从我的. xlsx文件中正确读取: Excel(数据源)中的数字为320000000515952。 这与显示无关,我知道我可以在这里更改。这是关于保持底层数据在读取时的
-
如何将数据库中的所有表更改为UTF8字符集?
问题内容: 我的数据库不在UTF8中,我想将所有表都转换为UTF8,我该怎么做? 问题答案:
-
机器学习资料集 Datasets - Ex 1: The digits 手写数字辨识
机器学习资料集/ 范例一: The digits dataset http://scikit-learn.org/stable/auto_examples/datasets/plot_digits_last_image.html 这个范例目的是介绍机器学习范例资料集的操作,对于初学者以及授课特别适合使用。 (一)引入函式库及内建手写数字资料库 #这行是在ipython notebook的介面裏专用
-
如何以字符串形式从我的集合中获取数据?
我编写了一个日期选择器,用户可以在其中使用bootstrap在输入字段中输入日期: 在此之后,我将它与表单的一些其他信息一起插入到我的集合中,并将用户路由到一个新页面。 在那里,我想为我的倒计时计时器获取closeDateDB的信息,并在endtime时重定向用户 有人能帮我如何得到插入的CloseDateDB作为我倒计时的字符串吗??我是新来的流星,我真的很感激你的帮助。
-
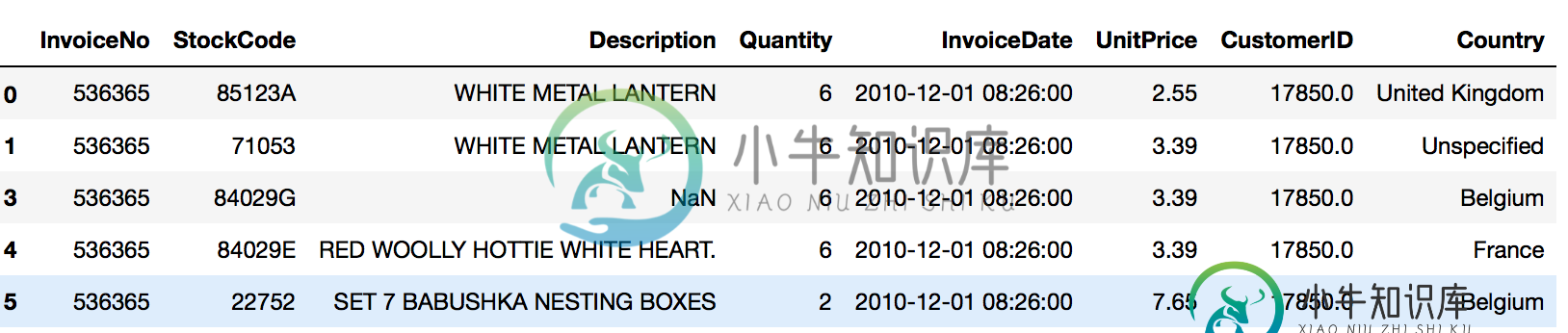 如何筛选数据集以仅包含特定关键字?[副本]
如何筛选数据集以仅包含特定关键字?[副本]我有一个包含多个国家的数据集。如何对其进行筛选,使其仅包含特定国家/地区? 例如,现在它包含英国、比利时、法国等 我想过滤它,使它只显示法国和比利时。 到目前为止,我已经尝试过: 它是有效的,因为它只过滤法国的数据,但如果我加上比利时 它不再工作了。我得到以下错误: 我们将非常感谢您的帮助。
-
如何使用JDBC数据源设置写入MySQL表的字符集?
我使用Spark JDBC将数据摄取到Mysql表中。如果表不存在,它也会创建一个表。许多文本都有特殊字符。如果遇到任何特殊的食物,摄入就会失败。我通过在MySQL表中手动设置字符集utf8解决了这个问题。 是否可以在Spark JDBC中创建表时设置? 我使用DataFrames保存数据到MySQL。