《创维数字》专题
-
写一个方法,传入数字x,从一个一维数组里找到两个数字符合“n1 + n2 = x”
本文向大家介绍写一个方法,传入数字x,从一个一维数组里找到两个数字符合“n1 + n2 = x”相关面试题,主要包含被问及写一个方法,传入数字x,从一个一维数组里找到两个数字符合“n1 + n2 = x”时的应答技巧和注意事项,需要的朋友参考一下
-
Android:二维ArrayList帮助
问题内容: 目前,我已经将我的代码将用户输入放入一维ArrayList中,但是我想将它们输入到二维ArrayList中,并且遇到了一些麻烦。 这是我的代码: 问题答案: 那么,您需要首先创建一个二维ArrayList。为此,您需要创建一个ArrayLists的ArrayList。 因此,您的循环将沿着这些思路发展(假设我了解您要执行的操作):
-
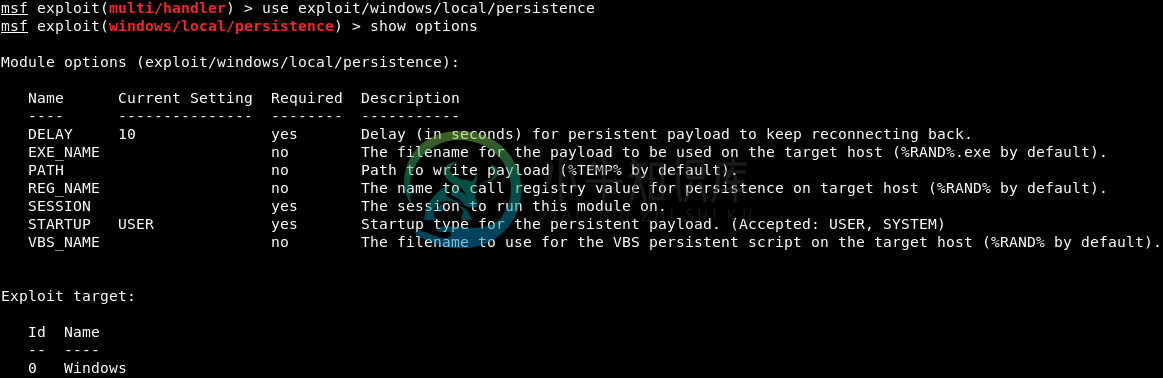 维护访问方法
维护访问方法在上一节中,我们已经看到当目标用户重新启动计算机时,我们就会失去连接。我们使用了一个普通的后门程序,这就是为什么当计算机重新启动时,后门程序将被终止,进程将被终止,我们将失去连接。但在本节中,我们将讨论如何维持对目标计算机的访问的方法。我们将使用之前创建的普通HTTP反向Mterepreter不可检测的后门。将它作为一项服务注入,以便每次目标用户运行他们的计算机时它都会运行,它会尝试以一定的间隔连
-
C memcpy二维阵列
为什么上面的代码不起作用,我应该如何纠正?
-
截获拉维路由
我正忙于在Laravel5.1中构建一个Restful API,API版本通过头部传递。通过这种方式,我可以对功能进行版本设置,而不是复制和粘贴整个管线组并增加版本号。 我的问题是,我想有版本的方法,IE: 我已经在我的路由中添加了一个中间件,在那里我从标题中捕获版本,但是现在需要修改请求以从控制器中选择正确的方法。 app/Http/routes.php app/Http/Middleware/
-
谷歌分析,维度
我终于明白了我是如何连接到谷歌分析的,正确的——现在我可以在某个时候访问数据了。我正在使用google-api-php-Client。 我可以工作与指标只是罚款fx,通过做 它将返回会话数、页面浏览量和会话持续时间。但是现在让我们假设我也对使用一些维度感兴趣-也许我希望查询返回搜索引擎所有流量的站点使用情况数据,按页面浏览量降序排序。 数据- 我尝试在数组中提供维度和过滤器,但它返回以下错误 警告
-
mpld3三维散点图
我正在探索mpld3库,不知道如何创建三维散点图。使用Matplotlib,我将执行以下操作: 类似地,我尝试使用mpld3(在Jupyter笔记本中):导入matplotlib。mpl_工具包中的pyplot作为plt。mplot3d导入轴3D导入mpld3 我得到了错误 有什么想法吗? 这是完整的错误日志:
-
三维线性回归
我想写一个程序,给定三维空间中的点列表,用浮点表示为x,y,z坐标的数组,在这个空间中输出一条最佳拟合线。直线可以/应该是单位向量和直线上的点的形式。 问题是我不知道这是怎么做的。我发现的最接近的东西是这种联系,尽管老实说,我不明白他是如何从一个方程到另一个方程的,当我们到达矩阵时,我已经迷失了。 有没有一个简单的二维线性回归的泛化,我可以使用/有人可以(数学上)解释上面的链接到方法是否/如何工作
-
SFML二维tilemap冲突
我目前正在用SFML制作一个2D rpg游戏,我正在尝试让玩家与某些瓷砖碰撞。我已经达到了玩家可以与我想要的瓷砖碰撞的程度,也可以通过下面的代码沿墙滑动: 它所做的基本上是迭代每一个实体,并测试玩家是否与其中任何一个实体相交。如果有交叉,玩家会回到他们之前没有碰撞时的位置。 我有的主要问题是,当我同时按两个方向(例如,在向右和向上移动时与右边的墙相撞)时,玩家会陷入僵局,因为它正在重置x和y坐标。
-
 百度运维三面
百度运维三面1.自我介绍 2.在做运维期间遇到的比较大的挑战 3.蓝绿发布 4.蓝绿变更的好处和坏处 5.操作k8s使用的kubectl还是dashboard 6.如果有两个pod,其中一个资源被打满,k8s靠什么来保护机器上另外一个pod不受影响,或者说能做到什么样的隔离 7.如果pod的cpu超过了设置的资源上限,会杀掉进程还是怎么样 8.nginx能自动感知到后端服务挂了吗 9.ingress是怎么做后
-
 招商局运维sre
招商局运维sre1.简述mvc三层架构 2.mvc每个字母代表什么 3mysql和redis区别(我简历上提到过这两个 4.redis主要作用 5.对系统运维岗位的了解 6.shell命令说几个 7.linux查询cpu的命令 8.awq是什么
-
 百度运维一面
百度运维一面面试官人超级好 1. mysql 的B+树索引,为什么要使用B+ 2. 线程,进程,协程 3. redis6.0之后的网络模型 4. 预防死锁 5. hash算法? 6. tcp介绍一下 7. redis的持久化方式,rdb的时候fork一个子线程,为什么是fork一个子线程。
-
维护 service-worker.js 文件
开始之前,您可以查看 Service Worker 相关内容,快速掌握相关基础。查看 Service Worker 浏览器支持情况 service-worker.js 文件作为缓存管理的重要文件,在导出 Lavas 工程的时候我们默认给了一个能覆盖缓存需求的 /dist/service-worker.js 文件。 但是我们默认提供的文件可能在后续您的开发过程中并不能完全覆盖您的需求,所以你需要对其
-
日常维护 - Seafile GC
Seafile 利用存储去重技术来减少存储资源的利用。 简单来说,这包含如下两层含义: 不同版本的文件或许会共享一些数据块。 不同的资料库也或许会共享一些数据块。 运用这项技术之后,在你删除一个资料库时,会导致底层数据块不会被立即删除,因此 Seafile 服务器端没用的数据块将会增多。 通过运行垃圾回收程序,可以清理无用的数据块,释放无用数据块所占用的存储空间。 垃圾回收程序将会清理如下两种无用
-
日常维护 - Seafile FSCK
在服务器端,Seafile 通过一种内部格式将文件存储在资料库中。Seafile 对于文件和目录有其独有的保存方式(类似于Git)。 默认安装下,这些内部对象,会被直接存储在服务器的文件系统中(例如 Ext4,NTFS)。由于大多数文件系统,不能在服务器非正常关闭或系统崩溃后,保证文件内容的完整性。所以,如果当系统崩溃时,正在有新的内部对象被写入,那么当系统重启时,这些文件就会被损坏,相应的资料库