《开立医疗》专题
-
addEventListener(“ click”,…)立即触发
问题内容: 我正在尝试创建一些放置适当的说明性工具提示,用户可以单击这些提示以了解站点界面的工作方式。每个工具提示都有一个“下一个”链接,可通过修改类(因此更改为CSS)来切换上一个和下一个工具提示的可见性。 这是应该执行此操作的一些简化代码: 当我将此代码粘贴到控制台中时(或在页面加载时)立即调用(并正确切换类)。如果我将替换为,则按预期触发。我究竟做错了什么? 问题答案: 当您绑定事件时,您就
-
无法建立ClassFile-ArchiveException
问题内容: 我们使用spring,jpa,tomcat,maven等开发应用程序。 在我的开发人员机器本地,一切正常,但是当我们在Linux服务器上部署应用程序时,出现以下异常: 当我调用此方法时,初始化数据库后,异常出现在我的代码中: 找不到问题。感谢帮助!谢谢 问题答案: 多亏了master-slave,我发现了问题,因为他描述了与javassist的不兼容Java 8库存在冲突。 就我而言,
-
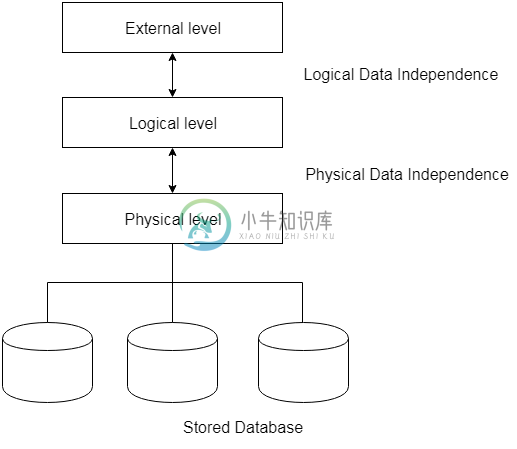 DBMS数据独立性
DBMS数据独立性主要内容:1. 逻辑数据独立性,2. 物理数据独立性可以使用三模式体系结构来解释数据独立性。 数据独立性是指能够在数据库系统的一个级别修改模式而不改变下一个更高级别的模式的特征。 有两种类型的数据独立性: 1. 逻辑数据独立性 逻辑数据独立性是指能够在不必更改外部模式的情况下更改概念模式的特征。 逻辑数据独立性用于将外部级别与概念视图分开。 如果对数据的概念视图进行任何更改,那么数据的用户视图将不会受到影响。 逻辑数据独立性发生在用户界面级别。 2
-
Oracle:DBMS_UTILITY.EXEC_DDL_STATEMENT与立即执行
问题内容: 和之间有什么区别 ? 问题答案: 从根本上说,它们执行相同的操作,这是提供一种在PL / SQL中执行DDL语句的机制,这是本机不支持的。如果内存对我有用,那么在Oracle 7版本的DBMS_UTILITY软件包中可以使用EXEC_DDL_STATEMENT,而在8中仅引入本机动态SQL(EXECUTE IMMEDIATE)。 有一些区别。EXECUTEIMMEDIATE主要是关于执
-
如何建立RESTful API?
问题内容: 问题是这样的:我有一个在PHP服务器上运行的Web应用程序。我想为此构建一个REST API。 我进行了一些研究,发现REST api使用带有身份验证密钥(不一定)的某些URI的HTTP方法(GET,POST …),并且信息以HTTP响应的形式返回,信息为XML或JSON。 (我宁愿使用JSON)。 我的问题是: 作为应用程序的开发人员,我如何构建这些URI?我需要在该URI上编写PH
-
独立Kafka制作人
我正在考虑创建一个独立的Kafka生产者,它作为守护进程运行,通过套接字接收消息,并将其可靠地发送给Kafka。 但是,我决不能是第一个想到这个想法的人。这样做的目的是避免使用PHP或Node编写Kafka生成器,而只是通过套接字将消息从这些语言传递到独立的守护进程,这些语言负责传递,而主应用程序则一直在做自己的事情。 此守护进程应负责在发生中断时进行重试传递,并充当服务器上运行的所有程序的传递点
-
Rxjava retryWhen立即调用
重试时间:io.reactivex.subjects.serializedsubject@35fb3008 subscribeNext 进程已完成,退出代码为0
-
USState不立即更新
下面是我的代码的一个片段。调用filteredData()时,状态未更新。在状态更新之前,我必须单击按钮两次。这是一个旧项目,我正在使用钩子更新它。我以前在设置状态后使用了回调函数,但我不能用钩子实现。 }
-
立即停止线程
-
 建立Java数据库
建立Java数据库我试图为一个编程类设置一个Java DB数据库。我正在遵循Deitel和Deitel教科书中的步骤: 我已经安装了JDK11.8.0_112。我运行的是Windows10。 我的安装在C:\program files\java\jdk1.8.0_112。我将JAVA_HOME var设置为C:\program files\java\jdk1.8.0_112 然后,连接'jdbc:derby:new
-
Kafka独立消费者
我是Kafka的新手,我想验证我的设计。下面是我所拥有的。 我有一个生产者发布到一个主题,有一堆容器(部署我的web应用程序的地方),每个容器上都运行着一个消费者。这些消费者不在消费者组中,也不独立地消费消息。每个消费者都应该阅读主题中的所有消息。例如,假设主题m0,m1,m2上有3条消息,那么consumer1到consumerN应该独立地读取m0,m1,m2。每个使用者在处理读取的消息后立即提
-
立即停止服务
我的应用程序设置为(非故意)服务将使用gps/网络侦听器轮询位置。它工作得很好,因为我负责服务何时结束(即在找到新位置或达到超时时调用stopSelf())。然而,我最近读到,intentService可能更适合长时间运行的任务,因为它不是在ui线程上运行的,而是在自己的工作线程上运行的。问题是,现在它不允许服务在任何时间运行(我假设这是因为服务中没有任何活动发生,而侦听器等待接收位置,因此服务本
-
独立运行Apache Atlas
我正在尝试在Ubuntu上以独立的方式运行Apache地图集 - 这意味着不必设置Solr和/或HBase。我所做的(根据文档:http://atlas.apache.org/0.8.1/InstallationSteps.html)是克隆Git存储库,使用mbadded的HBase和dSolr构建maven项目: 解压缩了 resuting tar.gz 文件并执行了 bin/atlas_sta
-
建立关联关系
好了,这里是第一次用到NutDao的关联关系了, 打开User类,加入2行 @One(target=UserProfile.class, field="id", key="userId") protected UserProfile profile; 自然的,为其添加Getter/Setter
-
Single projects(独立项目)
一个项目将会自动生成测试运行。默认位置为:build/reports/androidTests 这非常类似于JUnit的报告所在位置build/reports/tests,其它的报告通常位于build/reports/< plugin >/。 这个路径也可以通过以下方式自定义: android { ... testOptions { reportDir = "$p