《群面》专题
-
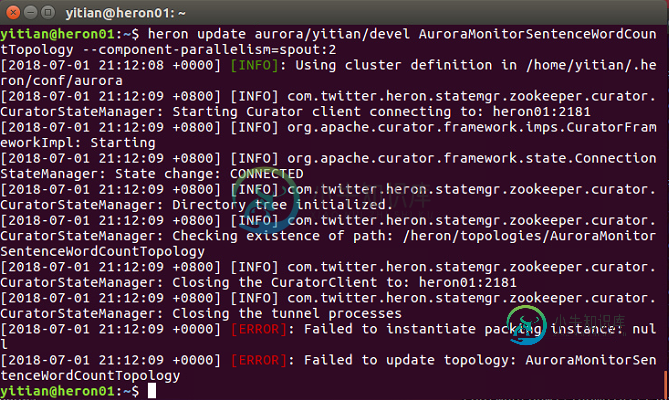 在Heron集群中更新拓扑失败
在Heron集群中更新拓扑失败这个拓扑运行正常,不知道是什么原因导致这个问题。
-
RabbitMQ多个集群上的镜像队列
可以通过多个RabbitMQ集群使用RabbitMQ HA吗? 这是我的要求: 我们有2个RabbitMQ集群(每个集群有4个节点)。两个集群中的所有节点都将使用相同的Erlang cookie。因此,尽管这两个群集在物理上位于不同的位置,但将作为一个包含8个节点的群集。 我们计划使用HAProxy来负载平衡两个集群(8个节点)。发布者和消费者都将使用此代理连接到代理。 我们希望为HA使用镜像队列
-
Kafka在代理集群前支持ELB吗?
我有一个关于AWS上Kafka经纪人集群的问题。现在集群前面有一个AWS ELB,但当我将生产者或消费者的“bootstrap.servers”属性设置为ELB的“A”记录(以及正确的端口号)时,生产者和消费者都无法分别生成和使用消息。我已经关闭了我的代理上的所有SSL,并通过明文9092端口进行连接,我的ELB将端口1234转发到9092。例如,在我的Producer配置属性中,我将。。。 bo
-
从spark插入群集配置单元表
我试图做一些性能优化的数据存储。这个想法是使用蜂巢的巴克特/集群来桶可用的设备(基于列id)。我目前的方法是从外部表插入数据到表中的拼花文件。结果它应用了巴克特。 我想通过直接从PySpark 2.1将数据摄取到该表中来摆脱中间的这一步。使用SparkSQL执行相同的语句会导致不同的结果。添加cluster by子句 仍然会导致不同的输出文件。 这就引出了两个问题:1)从spark向集群蜂箱表中插
-
群集quartz实例调度重复作业?
我的we应用程序A将扫描业务相关的数据库表,并在启动期间和之后每10分钟安排石英作业。如果我在两个不同的tomcat实例上部署两个A应用程序,那么将有两组通过Quartz调度的重复作业。 我该如何解决这个问题?我是否需要将调度作业的部分代码提取到单独的应用程序中,并确保只部署了1个实例,从而只调度了1组作业?但是问题变成了--如果这个实例失败了怎么办?在这种情况下,如何实现故障转移?
-
从Kubernetes吊舱访问另一个集群
我在GKE负责詹金斯。构建的一个步骤是使用< code>kubectl部署另一个集群。我在jenkins容器中安装了gcloud-sdk。正在讨论的构建步骤是这样做的: 然而,我得到了这个错误(虽然它在本地正常工作): 注意:我注意到,在没有配置的情况下(~/.kube为空),我可以使用kubectl并访问pod当前运行的集群。我不知道它是如何做到的,它是否使用/var/run/secrets/k
-
Storm群集安装在本地-未执行
我试图在同一台机器上运行zookeeper、nimbus和supervisor来模拟storm集群(我知道storm是作为分布式系统设计的,但为了学习,我想模拟单机中的工作方式)。
-
维护 TiDB 集群所在的 Kubernetes 节点
TiDB 是高可用数据库,可以在部分数据库节点下线的情况下正常运行,因此,我们可以安全地对底层 Kubernetes 节点进行停机维护。在具体操作时,针对 PD、TiKV 和 TiDB 实例的不同特性,我们需要采取不同的操作策略。 本文档将详细介绍如何对 Kubernetes 节点进行临时或长期的维护操作。 环境准备: kubectl tkctl jq 注意: 长期维护节点前,需要保证 Kuber
-
如何在群聊中添加机器人?
群主/管理员在企业群中,点击机器人图标打开机器人面板,进入添加机器人列表。1个群最多只能添加10个机器人。 详细请参阅:在客户端使用机器人 机器人添加入口:
-
如何查看外部群的二维码?
查看方法:群聊右上角图标-群二维码
-
管理员怎么审核入群通知?
为加强管理员对群聊的掌控力,新增加进群审核设置。群管理员在“群管理”中开启“群邀请审核”后,群内除管理员以外的成员邀请新人加入时,需管理员审核。 1.手机版 使用方法:群详情-群管理-群邀请审核 2.电脑版 使用方法:群详情-群邀请审核
-
群友学习笔记 - request和response学习
request组件 : request 有三个部分 mesasge 文件夹里面的 request 和serverrequest(serverrequest继承自request)http里面的 request 1.message里面的request: 函数 : __construct():构造函数 getRequestTarget():获得请求的路径
-
群友学习笔记 - autoload和ioc学习
autolad.php 负责处理框架类的自动加载,在core.php的registerAutoLoader()被调用 让我们分析来autolad的源码吧 变量: protected $instance:此框架采用单例模式,这个变量负责储存自己类的实例,所以在框架运行会,此类每个进程有且只有一个对象 protected $prefixes:这个变量存储 命名空间的与其对应的路径,我们
-
群友学习笔记 - core和server学习
core.php 和 server.php 源码分析 首先我扪要一些swoole的基础 swoole 的整个进程种类是 manager进程,master进程,work进程,task进程 maskter进程:Swoole的主进程,是一个多线程的程序。其中有一组很重要的线程,称之为Reactor线程。它就是真正处理TCP连接,收发数据的线程。把接受到的数据分配给worker进程 manan
-
 Python selenium 加载并保存QQ群成员,去除其群主、管理员信息的示例代码
Python selenium 加载并保存QQ群成员,去除其群主、管理员信息的示例代码本文向大家介绍Python selenium 加载并保存QQ群成员,去除其群主、管理员信息的示例代码,包括了Python selenium 加载并保存QQ群成员,去除其群主、管理员信息的示例代码的使用技巧和注意事项,需要的朋友参考一下 一位伙计自己开了个游戏室,想在群里拉点人,就用所学知识帮帮忙,于是就有了这篇文章,今天小编特此通过实例代码给大家介绍下Python selenium 加载并保存QQ