
Python selenium 加载并保存QQ群成员,去除其群主、管理员信息的示例代码

一位伙计自己开了个游戏室,想在群里拉点人,就用所学知识帮帮忙,于是就有了这篇文章,今天小编特此通过实例代码给大家介绍下Python selenium 加载并保存QQ群成员去除其群主、管理员信息的示例代码
模拟登陆页面
页面分析
思路:
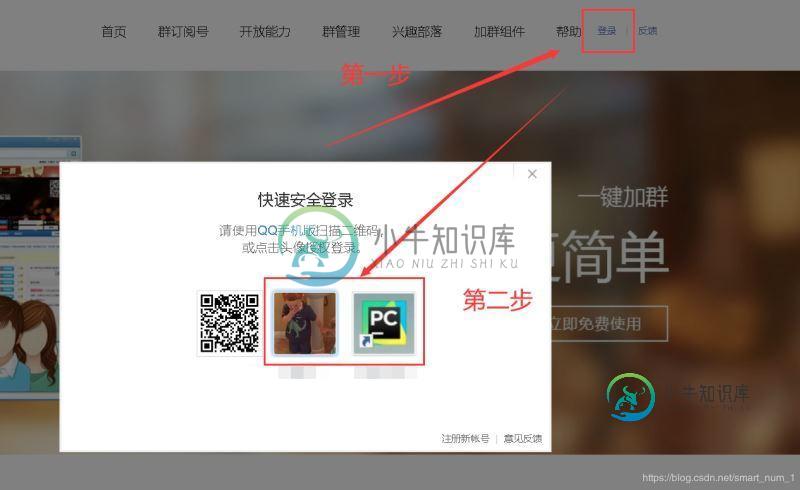
点击登陆按钮
选择要登陆的账号
代码实现
# Author:smart_num_1
# Blog:https://blog.csdn.net/smart_num_1
# WeChat:Be_a_lucky_dog
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
def login(driver = None):
already_dic = {}
# 创建一个字典,保存电脑登陆的QQ
login_button = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//p[@class="user-info"]/a')))
login_button.click()
# 点击登录,获取电脑登陆的QQ
already_login_number = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//div[@id="loginWin"]/iframe')))
driver.get(url = already_login_number.get_attribute('src'))
# 此步骤目的,是因为登录框是一个子页面,在上一级页面中获得到的这个子页面
already_login_numbers = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_all_elements_located((By.XPATH,'//span[contains(@class,"nick")]')))
# 获取电脑登陆的QQ
print('在以下账号中选择所需账号')
for already_login_number in already_login_numbers:
already_dic[already_login_number.get_attribute('innerText')] = already_login_number
print(already_login_number.get_attribute('innerText'))
QQ_NeedToLogin = input('需要登陆: ')
# 通过获取键名,在 already_dic 获得相应的键值
already_dic[QQ_NeedToLogin].click()
# 模拟点击要登陆的QQ,达到登陆的效果
time.sleep(1)
if __name__ == '__main__':
start_url = 'https://qun.qq.com/index.html#click'
# 群首页,用来登陆账号
driver = webdriver.Chrome(executable_path = './chromedriver.exe')
# 因为selenium 需要用到浏览器、浏览器驱动,但是还要配置环境变量,很麻烦,如果这样指定 webdriver 路径的话,就可以省去那一步
driver.get(url=start_url)
login(driver=driver)
选择所需加载群
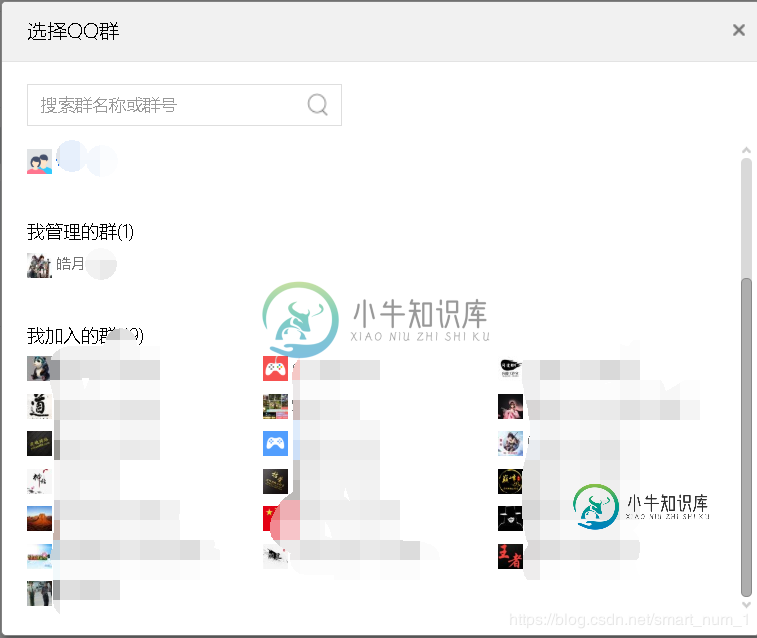
页面分析
打开群管理界面,会看到这样的信息,我们的目的是爬取已加入群的成员信息
代码实现
# Author:smart_num_1
# Blog:https://blog.csdn.net/smart_num_1
# WeChat:Be_a_lucky_dog
def get_group_number(driver = None):
group_number_dic = {}
# 同样的,利用字典储存信息
my_group_list = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_all_elements_located((By.XPATH,'//ul[@class="my-group-list"]/li')))
# 获取每个已加入群的节点信息
print('在以下群中选择:')
i = 1
for my_group in my_group_list:
try:
group_number_dic[str(i)] = my_group
print('第 %s 个--- '%str(i) + my_group.get_attribute('title') + ' ' + my_group.get_attribute('data-id'))
i += 1
except:
continue
# 打印出获得的群信息,获取所有的目标群
group = input('获取群编号 : ')
# 通过键名获取键值,得到要点击的目标
group_number_dic[group].click()
return driver
if __name__ == '__main__':
member_url_test = 'https://qun.qq.com/member.html'
driver.get(url = member_url_test)
driver = get_group_number(driver=driver)
保存所需信息
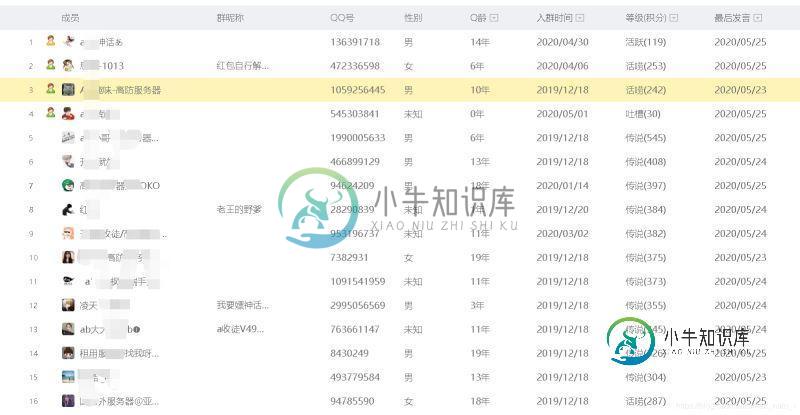
页面分析
可以看到,是个动态加载的页面,因为用的是selenium,所以就没必要分析到底是通过请求那个url得到的信息,直接模拟滚动获取就可以了
代码实现
# Author:smart_num_1
# Blog:https://blog.csdn.net/smart_num_1
# WeChat:Be_a_lucky_dog
def get_group_member(driver = None):
driver.refresh()
# 刷新一下界面,防止上一步点击过后,页面不更新的情况
elem_end = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//td[@class="td-user-nick"]/img')))
# 添加了等待,这个定位可以随便的选择,确保页面加载完毕的
for i in range(10):
time.sleep(0.5)
driver.execute_script("var action=document.documentElement.scrollTop=10000")
print('加载中······')
# 这个滚动范围可以任选,因为每次会加载21个信息,我看过我加的群,在10次过后的成员基本属于潜水的人了,要不要的就无所谓了
group_members = driver.find_elements_by_xpath('//tr[contains(@class,"mb")]')
for group_member in group_members:
try:
data = group_member.text.split('\n')[2].split(' ')[0]
# 这一步,得到一个列表,从第一位开始分别是成员、群昵称、QQ号、性别、Q龄、入群时间、等级(积分)、最后发言,在这里我是只需要QQ号码
#对于其他信息,根据自己需要,添加代码即可
if data.isdigit() == True:
with open('./record.txt','a',encoding = 'utf-8') as record:
record.write(data + '@qq.com')
record.write('\n')
except:
continue
print('Loaded')
完整代码
# Author:smart_num_1
# Blog:https://blog.csdn.net/smart_num_1
# WeChat:Be_a_lucky_dog
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.chrome.options import Options
import time
import random
import os
def get_group_member(driver = None):
driver.refresh()
elem_end = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//td[@class="td-user-nick"]/img')))
for i in range(10):
time.sleep(0.5)
driver.execute_script("var action=document.documentElement.scrollTop=10000")
print('加载中······')
group_members = driver.find_elements_by_xpath('//tr[contains(@class,"mb")]')
for group_member in group_members:
try:
data = group_member.text.split('\n')[2].split(' ')[0]
if data.isdigit() == True:
with open('./record.txt','a',encoding = 'utf-8') as record:
record.write(data + '@qq.com')
record.write('\n')
except:
continue
print('Loaded')
def get_group_number(driver = None):
group_number_dic = {}
my_group_list = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_all_elements_located((By.XPATH,'//ul[@class="my-group-list"]/li')))
print('在以下群中选择:')
i = 1
for my_group in my_group_list:
try:
group_number_dic[str(i)] = my_group
print('第 %s 个--- '%str(i) + my_group.get_attribute('title') + ' ' + my_group.get_attribute('data-id'))
i += 1
except:
continue
group = input('获取群编号 : ')
group_number_dic[group].click()
return driver
def login(driver = None):
already_dic = {}
login_button = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//p[@class="user-info"]/a')))
login_button.click()
already_login_number = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_element_located((By.XPATH,'//div[@id="loginWin"]/iframe')))
driver.get(url = already_login_number.get_attribute('src'))
already_login_numbers = WebDriverWait(driver = driver,timeout = 100).until(EC.presence_of_all_elements_located((By.XPATH,'//span[contains(@class,"nick")]')))
print('在以下账号中选择所需账号')
for already_login_number in already_login_numbers:
already_dic[already_login_number.get_attribute('innerText')] = already_login_number
print(already_login_number.get_attribute('innerText'))
QQ_NeedToLogin = input('需要登陆: ')
already_dic[QQ_NeedToLogin].click()
time.sleep(1)
def start(driver = None,url = None):
print('Please wait for loading\n')
driver.get(url = url)
driver = get_group_number(driver=driver)
print('Please wait for loading\n')
get_group_member(driver=driver)
if __name__ == '__main__':
print('Please wait for loading')
chrome_options=Options()
chrome_options.add_argument('--headless')
try:
random.seed(time.time())
QQ_number = '738334209'
start_url = 'https://qun.qq.com/index.html#click'
member_url = 'https://qun.qq.com/member.html#gid=%s'%QQ_number
member_url_test = 'https://qun.qq.com/member.html'
driver = webdriver.Chrome(executable_path = './chromedriver.exe',chrome_options=chrome_options)
try:
driver.get(url=start_url)
login(driver=driver)
while True:
start(driver = driver,url = member_url_test)
flag = input('是否继续爬取? yes or no : ')
if flag == 'no':
break
os.system('cls')
driver.quit()
except:
print('Something wrong')
driver.quit()
except:
print('Something wrong!!!!!!')
os.system('pause')
转载请标明出处:https://blog.csdn.net/smart_num_1/article/details/106326488
总结
到此这篇关于Python selenium 加载并保存QQ群成员 去除其群主、管理员信息的示例代码的文章就介绍到这了,更多相关Python selenium 加载并保存QQ群成员内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
本文向大家介绍Python获取统计自己的qq群成员信息的方法,包括了Python获取统计自己的qq群成员信息的方法的使用技巧和注意事项,需要的朋友参考一下 首先说明一下需要使用的工具以及技术:python3 + selenium selenium安装方法:pip install selenium 前提:获取自己的qq群成员信息,自己必须是群主或者管理员,然后通过管理页面进入到成员高级管理网页端,就
-
创建群聊的成员或者群成员里头像第一个默认为群聊管理员。群聊管理员可以移交管理权限。 1.手机版 设置方法:群聊右上角图标-移交管理权 2.电脑版 设置方法:群聊右上角图标-移交管理权
-
假设我有 3 台 Kafka 服务器。服务器 1 zoopkeeper1 服务器 2 zoopkeeper2 服务器 3 zoopkeeper3 在集群配置中,zoopkeepers 会发生什么?它们是为每个服务器单独维护的,还是会在群集配置中同步其数据?
-
我将Kafka2.9.2-0.8.1.1与zookeeper 3.4.6一起使用。 是否有一个实用程序可以自动从Zookeeper中删除一个消费者组?或者我可以删除zookeeper中/consumers/[group_id]下的所有内容吗?如果是后者,我还缺少什么吗&这可以用一个动态系统来完成吗? 更新:从kafka 2.3.0版本开始,有一个新的实用程序: 相关文档:http://kafka.
-
在您创建的每个项目中,您都可以邀请伙伴加入,成为项目中的一员。项目成员将可以和您一起查看项目的详细测评报告。同时,您也可以在自己拥有的项目中对成员进行管理。目前,管理权限主要为“邀请成员”、“移除成员”和“修改成员”身份。 成员权限 目前,一个项目的成员角色主要为三种:拥有者、管理员和成员,其具体的权限解释如下所示: 拥有者 项目的创建者,拥有“成员管理权”和“项目管理权”。 管理员 由“拥有者”
-
我有一个问题,来自一个消费群体的许多Kafka客户端没有正确关闭,因此Kafka集群认为它们仍然是连接的。因此,我无法使用新版本的客户端连接到消费者组。会卡在再平衡这一步。 根据文档,应在< code>session.timeout.ms或maximum < code > group . max . session . time out . ms 之后删除它们。起初我试图将< code>sessi