《信息科技》专题
-
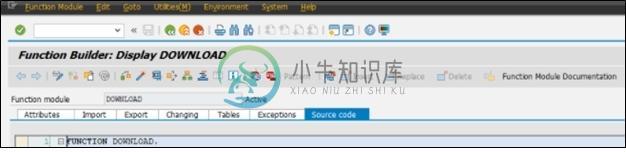 SAP ABAP中过时功能的信息
SAP ABAP中过时功能的信息本文向大家介绍SAP ABAP中过时功能的信息,包括了SAP ABAP中过时功能的信息的使用技巧和注意事项,需要的朋友参考一下 通常,该信息包含在过时的功能模块文档中。这是“下载”功能的信息快照。
-
Spring RESTful API获取客户端信息
Iv'e一直在使用本指南:https://spring.io/guides/gs/rest-service要创建RESTFul web服务,我面临的问题是,我不知道如何获取客户机IP地址等信息,使用此API是否可能? 谢谢
-
使用PHP选择特定的信息
我想用Wordpress博客创建一个投资组合。在“博客文章”的摘要页面上,我希望有图片的缩略图,然后当你点击这些图片时,它们会进入该项目的完整列表。 我想我可以限制摘要页面上的帖子,只显示描述中的一张图片。 我的想法如下: 在摘要页面上,我希望循环只针对并显示每个帖子中带有“缩略图图像”类的图像,然后在单个帖子页面中,我将使用CSS隐藏缩略图图像。 我想知道的是,在php中是否有一种很好的方法可以
-
Android-不从facebook检索用户信息
您好,这是代码,它确实检索用户信息,但当我将其转换为apk时,它不会检索任何用户信息。请帮忙: //ImageURL=new URL("https://graph.facebook.com/"userID"/图片?宽度="宽度"
-
Flink·Kafka:为什么我会丢失信息?
我编写了一个非常简单的Flink流媒体作业,它使用从Kafka获取数据。 这工作得很好,每当我在Kafka上将某些内容放入主题时,它都会被我的Flink作业接收并处理。现在我试图看看如果我的Flink作业由于某种原因不在线会发生什么。所以我关闭了flink作业并继续向Kafka发送消息。然后我再次开始我的Flink作业,并期望它会处理同时发送的消息。 然而,我得到了以下信息: 因此,它基本上忽略了
-
阻止Kafka消费者消费信息
有什么方法可以阻止Kafka的消费者在一段时间内消费信息吗?我希望消费者停止一段时间,然后开始消费最后一条未消费的消息。
-
Kafka消费者信息提交问题
Kafka新手。 Kafka版本:2.3.1 我正在尝试使用Spring cloud使用来自两个主题的Kafka消息。除了kafka活页夹和下面的一些简单配置之外,我没有做太多配置。每当(组协调器lbbb111a.uat.pncint.net:9092(id:2147483641机架:null)不可用或无效时,将尝试重新发现)发生时,已经处理的一堆消息会再次被处理。不确定发生了什么。
-
Gatling Feeder-从列表中获取信息
我想从内存中创建一个列表[Strings]上的新Gatling feeder。 在该场景中,我执行以下操作: 我的喂食器是这样的: val getGroupIdFeed:Iterator[Map[String,List[String]]]={Iterator.Continuously(映射(“组”)- 我的清单是这样的:我的清单[“a”、“b”、“c”] 我得到的结果是: 我的列表[“a”、“b”
-
发送大量信息Kafka制作人
我在用Kafka。 我有10k个jsons列表, 我该怎么做呢? 谢谢
-
不能修改CI中的头信息
我正在使用XAMPP开发CodeIgniter。当我在我的子域上上传我的文件时,它给我一个错误,但它在我的本地机器上工作。 这是我的控制器 这是我的错误: 遇到一个PHP错误 严重性:警告 消息:无法修改标题信息-标题已由发送(输出从/home/shakzeec/public_html/demo/application/controllers/admin.php:2开始) 文件名:库/Sessio
-
如何显示地点详细信息?
所以我有一个名为interestingpoint的类,其中包含变量'name'、'coordines'。我创建了一个包含有趣地点的列表,然后在地图上添加标记,如下所示: 所以主要的问题是,当我点击任何标记时,我可以获得它的细节吗?当我点击标记时,我想显示那个地方的描述和图片。
-
Apache Flink生产集群详细信息
我是Flink的新手。如何了解flink的生产集群要求。以及如何确定纱线集群模式下每个作业执行的作业内存、任务内存和任务槽。例如,我每天必须使用datastream处理大约6-7亿条记录,因为这是一个实时数据。
-
Kafka消费者重新阅读信息
我看到一个问题,我的主题中的所有消息都被我的消费者重新阅读。我只有1个消费者,我在开发/测试时打开/关闭它。我注意到,有时在几天没有运行消费者之后,当我再次打开它时,它会突然重新阅读我的所有消息。 客户端 ID 和组 ID 始终保持不变。我显式调用提交同步,因为我的启用.我确实设置了 auto.offset.reset=最早,但据我所知,只有在服务器上删除了偏移量时,才应该启动。我正在使用 IBM
-
 编写 pyspark.sql.dataframe.DataFrame 而不会丢失信息
编写 pyspark.sql.dataframe.DataFrame 而不会丢失信息我试图以CSV格式保存py spark . SQL . data frame . data frame(也可以是其他格式,只要它易于阅读)。 到目前为止,我找到了几个示例来保存DataFrame。然而,每次我编写它时,它都会丢失信息。 数据集示例: 为了将这个文件保存为CSV,我首先尝试了这个解决方案: 不幸是,这导致了以下错误: 这就是我尝试另一种可能性的原因,将spark数据帧转换成panda
-
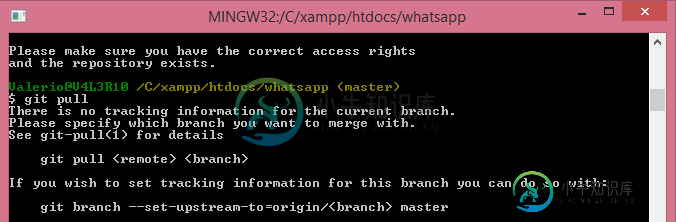 当前分支没有跟踪信息
当前分支没有跟踪信息我使用github的时间相对较短,并且一直使用客户端执行提交和拉取。我决定从昨天的git bash开始尝试它,并且我成功地创建了一个新的repo和提交的文件。 今天,我从另一台计算机上对存储库进行了更改,我提交了更改,现在我回到家里,执行了来更新我的本地版本,我得到了以下信息: 这次回购的唯一贡献者是我,没有分支(只有一个主人)。我在windows上执行了git Bash中的pull: 我做错了什