《平安保险》专题
-
声纳问题:确保该记录器的配置是安全的
我在声纳上的代码有以下问题: 确保此记录器的配置是安全的。 我写的代码是: 它在调用。 我如何解决这些问题?
-
从车轮格式安装numpy:“…不是此平台上支持的车轮”
我意识到一个与此相关的问题已经被问到不能安装numpy从车轮格式,但那里提出的解决方案对我不起作用。我也在那条线上问过(通过回答!)但我没有收到任何回复,所以下面是: 我一直在尝试安装matplotlib,但我首先需要安装numpy。我下载了Numpy-1.8.2+mkl-cp26-none-win_amd64.whl文件,然后尝试使用PIP安装它。我不断得到的错误信息是: “numpy-1.8.
-
 平安科技产品offer|0实习2周,拿到B端方向offer!
平安科技产品offer|0实习2周,拿到B端方向offer!业务一面30min 自我介绍 做XX项目的初衷 XX项目资源如何整合?谁来开发? XX项目什么时候上线 调研过程中,用户那些需求是真实的?哪些是虚假的? 优化项目核心 优化产品通过什么渠道触达? 公众号是不是我一个人运营的? 日访问量、月活跃度、月访问量的数据有关注吗? 实习主要做了什么事?产出是什么?效果是什么? 针对实习问了两个概念性的问题(因为不是产品相关实习就不详说了 两段实习和两段项目经
-
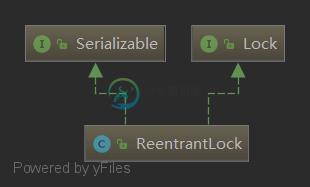 ReentrantLock源码详解--公平锁、非公平锁
ReentrantLock源码详解--公平锁、非公平锁本文向大家介绍ReentrantLock源码详解--公平锁、非公平锁,包括了ReentrantLock源码详解--公平锁、非公平锁的使用技巧和注意事项,需要的朋友参考一下 问题 (1)重入锁是什么? (2)ReentrantLock如何实现重入锁? (3)ReentrantLock为什么默认是非公平模式? (4)ReentrantLock除了可重入还有哪些特性? 简介 Reentrant = Re
-
JavaFX scrollpane-使用滚轮进行水平平移
我可以在JavaFX中创建一个仅水平滚动的滚动窗格,如下所示: 但是,鼠标滚轮在这种情况下仍然尝试垂直滚动而不是水平滚动(除非我专门在水平滚动条上滚动。)
-
在SQL Server 2005中使用SSIS从平面文件导入时如何保留NULL值
问题内容: 我已将记录导出到以“ |”分隔的平面文件中 似乎当我将这些记录导入到新数据库中时,SQL Server将NULL值视为空字段。我的查询在记录/字段为NULL时正常工作,因此我想找到一种在数据中保留NULL值或将空白字段转换为NULL值的方法。我以为前者会容易一些,但我不知道该怎么做。任何帮助,将不胜感激。 问题答案: 在数据流中的目标连接中,有一个属性可供您查看,该属性显示Keep n
-
Redis`SCAN`:如何在可能匹配的新密钥之间保持平衡并确保在合理的时间内最终结果?
问题内容: 我不太熟悉。目前,我正在设计一些实时服务,我想依靠它。我希望每分钟〜10000-50000个键具有合理的价格,并且使用很少的匹配它们就不会干扰性能瓶颈。 我怀疑的是“输入/输出速率”,并且可能会因与某些查询匹配的键而泛滥,因此它永远不会终止(即始终以最新的光标位置进行回复并迫使您继续;如果有人消耗掉了并且有与)。 显然,我可以将所需的大小设置足够长的时间。但是我想知道是否存在更好的解决
-
Phonegap构建错误:无法运行“javac-version”,请确保已安装JDK
正在运行: 安装了android SDK和Java SDK后,出现以下错误: 错误:无法运行"javac-version",请确保您安装了JDK。您可以从:http://www.oracle.com/technetwork/java/javase/downloads. 我曾尝试将“java\jdk-9\bin”添加到环境变量和路径等中。运气不好! 我怀疑phonegap试图使用Java的运行时版本
-
 华为 网络安全与隐私保护工程师实习凉经
华为 网络安全与隐私保护工程师实习凉经主管面挂 1.介绍一下自己 2.有没有参加过什么项目或者竞赛,回答没有 3.家里支持来华为工作吗 4.怎么看待华为的加班 5.我看你的简历比较空,怎么证明你有工作的能力 感觉面试很快就结束了,整体流程不到半小时,第二天就发现被挂了 感觉被挂的主要原因还是简历太空了,没有做过很大型的项目就没往上写,之前做的一些没啥技术含量的小项目也没往上写 #简历中的项目经历要怎么写##华为求职进展汇总#
-
重新平衡期间的Kafka消费群体-切换时间和安全性
我们有一个要求,即给定Kafka分区的消息跨越组成消费者组的集群中的所有节点,应该总是一次执行一条消息,没有重叠。它们被处理(稍微)无序是可以容忍的,但是不允许时间重叠。 在重新平衡期间,我们如何才能安全——例如,假设我们自动缩放我们的消费者,并为同一个消费者组启动一个新消费者——那么新消费者将不得不接管同一个消费者组中现有消费者的分区。 对于一个特定的分区P,让我们假设使用者c1以前处理过分区P
-
平均每小时平均转置SQLite行和列
问题内容: 我在SQLite中有一个名为param_vals_breaches的表,如下所示: 我想编写一个查询,以小时为基础,向我显示一个特定的队列(例如“ a ”),每个队列的平均 参数 为 param_val 和 违规 数。因此,转置数据以获得如下所示的内容: 这可能吗?我不确定该怎么做。谢谢! 问题答案: SQLite没有PIVOT函数,但是您可以将聚合函数与表达式结合使用,以将行变成列:
-
蟒蛇熊猫平均值和加权平均值
我是新来的。任何帮助都将不胜感激 这是我的原始数据: 我想得到的是: 1创建一个新的列调用平均值,以计算每个提要的平均市值。 2求加权平均数。 这是我当前的代码,我得到NaN: 对于加权平均代码: 我得到了一个错误: AttributeError:“Series”对象没有属性“value”
-
Kafka再平衡算法是否平衡了主题?
Kafka再平衡算法是否适用于不同主题? 假设我有5个主题,每个主题都有10个分区,同一消费者组中有20个消费者应用程序实例,每个实例都订阅了这5个主题。 Kafka会尝试在20个实例中平衡50个分区吗? 还是它只在一个主题内保持平衡,因此10个第一个实例可能(或可能)接收所有50个分区,而其他10个实例可能保持空闲? 我知道,在过去,Kafka并没有在不同的主题之间取得平衡,但现在的版本呢?
-
从子树的平衡证明树是平衡的
我正在解决“破解编码面试”中的以下问题:实现一个函数来检查二叉树是否平衡。平衡树是这样一种树:任何节点的两个子树的高度相差不会超过一个。 这本书的示例解决方案(复制如下)假设从节点发出的树是平衡的,如果(a)节点的左子树和右子树是平衡的;和(b)节点本身是平衡的。我在试图理解为什么会这样?以上两个条件的满足如何证明从节点发出的整个树是平衡的? 谢啦
-
WSO2 ESB动态负载平衡endpoint平衡算法
我使用的是WSO2 470 ESB。我需要使用一个提供自定义负载平衡策略的动态负载平衡endpoint。我知道WSO2是基于apache Synapse的,在此基础上我可以找到以下内容: http://synapse.apache.org/userguide/config.html#dlbendpointconfig 真的吗?是否可以通过我自己的类自定义平衡策略?