《超聚变》专题
-
Https CXF超时
我正在尝试使用一个支付网关的WebService,它使用HTTPS作为协议,并且我正在使用一个apache cxf客户端。 stacktrace在下面。 fault:无法发送消息。在org.apache.cxf.interceptor.MessageSenderInterceptor.HandleMessage(MessageSenderInterceptor.java:64)在org.apach
-
超时设置
当微服务处理业务逻辑时间过长,网关会报超时错误,默认等待时间是5秒。 可在网关指定spring.cloud.gateway.httpclient.response-timeout参数设置超时时间,单位毫秒 # 设置响应超时10秒 spring.cloud.gateway.httpclient.response-timeout=10000 更多配置参见:org.springframework.cl
-
11.3.5 超链接
超链接是万维网的基础,是它让整个Web成为一个整体,并获得生命。可以毫不夸张地说,整个Internet就是由超链接连接而成的。word也不例外,它也需要通过超链接实现各章节之间的互联,甚至链接到本文档之外的资源。 在前面,已经介绍了链接的动态样式和根据文件类型显示相应文件类型的图标,来提高网站的可访问性。本节主要介绍如何区分一个链接是指向本站点的另一个页面,还是指向另一个站点上的页面,并为指向站外
-
超链接( Hyperlink)
本章介绍如何向单元格中的内容添加超链接。 通常,超链接用于访问任何Web URL,电子邮件或外部文件。 以下代码显示如何在单元格上创建超链接。 import java.io.File; import java.io.FileOutputStream; import org.apache.poi.common.usermodel.Hyperlink; import org.apache.poi.hs
-
Link 超链接
该组件为超链接组件,在不同平台有不同表现形式: 在APP平台会通过plus环境打开内置浏览器 在小程序中把链接复制到粘贴板,同时提示信息 在H5中通过window.open打开链接 平台差异说明 App H5 微信小程序 支付宝小程序 百度小程序 头条小程序 QQ小程序 √ √ √ √ √ √ √ 基本使用 通过href设置打开的链接,slot传入显示的内容 <u-link href="http:
-
超时设置
<?php $http = HttpRequest::newSession(); $response = $http->timeout(3000, 1000) // 总时间不得超过3秒,连接时间不得超过1秒 ->get('https://www.baidu.com/'); $content = $response->body(); // 网页源码
-
会话超时
在 HTTP 协议中,当客户端不再处于活动状态时没有显示的终止信号。这意味着当客户端不再处于活跃状态时可以使用的唯一机制是超时时间。 Servlet 容器定义了默认的会话超时时间,且可以通过 HttpSession 接口的 getMaxInactiveInterval 方法获取。开发人员可以使用HttpSession 接口的 setMaxInactiveInterval 方法改变超时时间。这些方法
-
增量超越
Incremental Transcendence 增量超越是一款网页点击/放置类游戏,你需要在其中收集资源、发展自己的家园。 点击可玩 https://static.oschina.net/trytry/Incremental-Transcendence
-
使用脚本转换Elasticsearch聚合以转换要聚合的字段值
问题内容: 我目前有类似的东西: 但是,myfield的值为“ alpha 1.0”,“ alpha 2.0”,“ beta 1.0”。现在,我只想聚合值“ alpha”,“ beta”。我怎么做?我试过了: 但我想这里没有拆分功能。欢迎任何建议! 问题答案: 我设法通过粘贴在问题中的链接来完成此任务:
-
SQL Server中的聚集索引和非聚集索引之间的区别
本文向大家介绍SQL Server中的聚集索引和非聚集索引之间的区别,包括了SQL Server中的聚集索引和非聚集索引之间的区别的使用技巧和注意事项,需要的朋友参考一下 索引是与实际表或视图相关联的查找表,数据库使用该查找表来改善数据检索性能的计时。在index中, 键存储在结构(B树)中,该结构使SQL Server可以快速有效地查找与键值关联的一行或多行。如果在表上定义了主键和唯一约束,则会
-
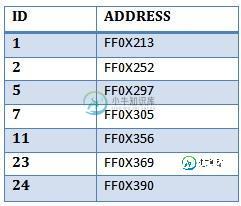 为什么非聚簇索引扫描比聚簇索引扫描更快?
为什么非聚簇索引扫描比聚簇索引扫描更快?问题内容: 据我所知,堆表是没有聚簇索引并且没有物理顺序的表。我有一个具有12万行的堆表“扫描”,并且正在使用以下选择: 如果为“ id”列创建非聚集索引,则将获得 223次物理读取 。如果删除非聚集索引并更改表以使“ id”成为主键(以及聚集索引),则将获得 515次物理读取 。 如果聚集索引表如下图所示: 为什么聚簇索引扫描的工作方式类似于表扫描?(或者在检索所有行的情况下更糟)。为什么不使用
-
Elasticsearch聚合:如何使用术语聚合的“其他”结果获取bucket?
我使用聚合从嵌套字段收集数据并卡住了一点 文件示例: ES允许通过rectangle.attributes._id来分组数据,但是有没有办法让一些“其他”桶把没有添加到任何组中的文档放在那里?或者,也许有一种方法可以通过创建查询来为文档创建桶。我认为桶将是完美的,因为我需要使用“其他”文档进行进一步的聚合。或者也许有一些很酷的解决方法 我使用这样的查询进行聚合 然后得到这个结果 这样的结果将是完美
-
弹性搜索:深度嵌套聚合下的reverse_nested聚合不起作用
Elasticsearch版本:2.3.3 基本上,标题说明了一切。如果二个嵌套聚合下使用reverse_nested,尽管文档似乎通过限定范围(请参阅结果中的最后一个字段),但其后面的聚合不会以某种方式工作。 这里我准备了一个例子——一个文档是一个学生的注册日期和考试历史。 映射: 试验文件: 聚合查询(无实际意义): 结果是: ...您可以在其中看到聚合“newest_exam_date”不起
-
有没有办法使git超过http超时?
问题内容: 我有一个自动运行git clone /pull的脚本(这实际上发生在jenkinsCI中,但我的问题更笼统)。远程git服务器基于HTTPS。带有git客户端的计算机具有不稳定的DSL Internet连接,因此有时会重新连接并更改IP地址,从而丢失所有现有连接。当git客户端运行时连接失败时,客户端将永远不会成功,但也不会因超时而失败,因此我的脚本会挂断。 我想设置客户端,使其在一段
-
Android Google Map Utils聚类距离
问题内容: 我正在使用Android Google Map utils启用标记的群集。我正在用10 当我按下按钮时,我会呼叫: 我的八个标记靠近给定区域,因此它们聚集在一起,我可以看到一个蓝色的球,其中心有数字八。其他两个标记远离另一组,但实际上彼此接近。 我现在看到的是一个带有八个标记的群集,而远处只有一个标记。仅当我放大单个标记(实际上是两个)的区域时,我才能看到两个标记。 我想显示八个标记的