《政采云》专题
-
JMeter:如何根据列值读取csv文件中的特定行数据,并将该列的值传递给采样器?
我不熟悉Jmeter,也不熟悉如何使用POC对web应用程序进行负载测试。 我正在尝试做的事情: 我总共有4个用户登录(外科医生)。每个登录都与'n'个病人相关联。 我已经创建了2个CSV文件 1。一个带有外科医生的用户登录和密码 2。另一个CSV文件包含PatientName、PatientID和与该患者相关联的外科医生,如下所示。 null 线程组(4个用户,按1秒递增时间,1个循环)-CSV
-
发送javax时发生异常。邮政MessaginException:530 5.7.57 SMTP;客户端未通过身份验证,无法在从发送邮件期间发送匿名邮件
这仅适用于(smtp.office365.com)smtp。
-
由于政策原因,应用程序一直被谷歌应用商店拒绝,但只使用READ_SMS,尝试了几个核心功能,但仍未通过。
我的应用程序仅使用READ_SMS作为“敏感权限”,我们使用它来访问SMS消息并扫描我们发送的特定文本以进行交易验证。 应用程序“短信和通话记录权限”页面上设置的当前核心功能:基于短信的资金管理 我还尝试了“基于短信的金融交易和相关活动,其中访问被限制为金融短信交易(例如,5位数字的消息)”,但仍然被拒绝 它自2019年以来一直在商店直播,并成功通过了50多次更新,但几个星期以来,我们一直无法通过
-
我正在编写一个PHP函数来搜索Wordpress模板文件中的邮政编码数组。为什么我的函数不会返回一个值?
该函数现在的目的是遍历多个逗号分隔的邮政编码列表(zip_codes_serviced的高级自定义字段),并将其与特定的邮政编码匹配(用于测试目的为33606)。如果匹配,则该函数应打印与该邮政编码相关联的城市和州域。这里是佛罗里达州坦帕市。参见下面的函数: 然后我这样调用函数: 这不是应该打印出城市和州的字段在页面上吗?当我把逻辑放在函数外部时,它可以工作,但我不能让它在函数内部工作。有人有什么
-
在片段着色器中,为什么我不能使用平面输入整数来索引采样2D的统一数组?
我想指定渲染精灵阵列时要使用的纹理。所以我在它们的顶点数据中放置了一个纹理索引,并将它作为一个平面值从顶点着色器传递到片段着色器,但不能像预期的那样使用它来索引采样器数组,因为编译器认为它是“非常量”。相反,我不得不求助于下面令人厌恶的代码。有人能解释一下这是怎么回事吗?
-
在节点js中采用AES/GCM/Nopadding算法对有效载荷进行密钥加密和iv加密,在java中进行解密
-
如何让线程组中的所有采样器为一个用户完全运行,然后从jmeter中的第二个用户开始?
我有一个jmeter脚本,其中有3个用户 线程组内部有3个控制器。 我想它应该完全运行第一个用户的第一个控制器,然后从第二个用户开始。 目前它正在运行第一个控制器3次,然后第二个控制器3次,然后运行
-
错误:C2679二进制 '==': 找不到运算符,该运算符采用“constd::string”类型的右操作数(或者没有可接受的转换
我已经为一个员工管理系统编写了代码,该系统将员工类对象存储到一个向量中,在我尝试编译之前没有错误,我得到了错误:C2679二进制 '==': 找不到运算符,该运算符需要一个类型为“constd::string”的右操作数(或者没有可接受的转换)。但是我不确定为什么会有任何帮助,谢谢!
-
如何按行ID进行分析,其中每一行将被重新采样(重新分析)10次,然后再进入R中的下一行?
我是R方面的初学者,正在处理数据,我需要从von Mises分布中随机抽样每行10次。我已经计算了数据的浓度参数(kappa),并且正在使用包CircStats中的rvm()生成随机样本。对于每一个真实的观察,我有一个冯·米塞斯的平均值(以度数为单位,下面的“示例”栏): Obs例1 1 69.43064 2 2-41.80749 3 3 133.83900 4 4-12.82486 5 5-13
-
对于普罗米修斯来说,高标签基数但低度量/标签计数和不频繁的采样是可接受的用例吗?
我有一个监控用例,我不完全确定它是否适合普罗米修斯,我想在深入研究之前征求意见。 我要存储的内容的数字: 只有1米。该指标有1个标签,其中有1,000,000到2,000,000个不同值。这些值是量规(但如果它们是计数器,会有什么不同吗?)采样率为每5分钟一次。保留数据180天。 如果我有100万个不同的标签值,估计存储大小: (根据普罗米修斯文档中的公式:retention_time_secon
-
如果用户是其他证券开户交易用户,采用什么方法可以引导用户来东方财富证券开户交易?
本文向大家介绍如果用户是其他证券开户交易用户,采用什么方法可以引导用户来东方财富证券开户交易?相关面试题,主要包含被问及如果用户是其他证券开户交易用户,采用什么方法可以引导用户来东方财富证券开户交易?时的应答技巧和注意事项,需要的朋友参考一下
-
javascript - 前端监控针对静态资源加载时间采集,PerformanceResourceTiming有办法知道资源是否是通过协商缓存加载的吗?
除了deliveryType外,有兼容性更好的方案了解是否是通过缓存加载的吗
-
我刚刚开始学习Java。我正在尝试制作一个采用十进制的程序。但是当我输入小数时,它会给我错误
包装com.Pramesh; 导入Java . util . scanner; public class PrameshShrestha { public static void main(String[] args) { }
-
我有一个抽象的类w/1 setter方法-参数是一个对象。我想要一个通用的参数,它采用扩展它的类的类型
我想要的是: 我想要一个泛型,用来扩展抽象类“DogKennel”的类,而不是“公共空插入狗(对象对象)”方法中的“对象”。例如,如果我创建了一个名为“RetrieverDogKennel”的类来扩展“DogKennel”,我希望“RetrieverDogKennel”类的“插入狗(...)”方法中的参数只接受“检索”对象。虽然它看起来不像这个“插入狗(检索检索)”,但该方法会像它一样,只允许在其
-
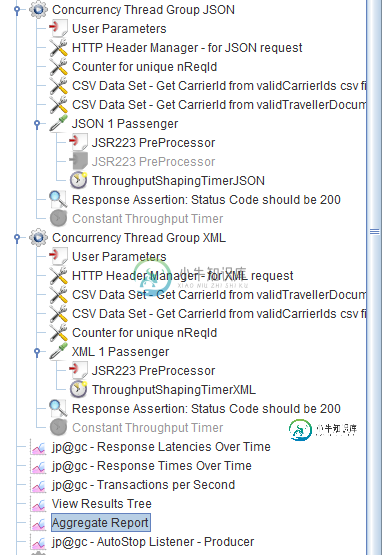 如何使用两个(或更多)并发线程组实现预期的RPS,每个线程组都有自己的采样器和吞吐量成形计时器?
如何使用两个(或更多)并发线程组实现预期的RPS,每个线程组都有自己的采样器和吞吐量成形计时器?在JMeter 5.4.1中,我在测试计划中使用了2个并发线程组,每个线程组都有如下配置: 每个线程组下面都有一个HTTP采样器,每个HTTP采样器都有一个贯穿成型计时器 我的意图是能够在最初的X秒内在每个采样器上实现1个RPS,但显然,它正在两个采样器之间拆分1RPS并试图总共实现1个RPS,即使每个并发线程组都有自己独立的整个整形定时器。 我的预期是,采样器将产生约1个RPS负载,总计约2个。