《差旅壹号》专题
-
在AngularJS中可观察到的和promise之间的差异。[副本]
在AngularJS中可观察到的和promise之间的区别?在angular 2和angular 4版本中,promise和观测值有哪些变化?解释这种情况的例子会有很大帮助。
-
Spring批处理中Step、Tasklet和Chunk之间的差异[已关闭]
spring batch中的Step、Tasklet和Chunk之间有什么区别。? 此外,如何通过Spring Batch并行执行步骤。?
-
带有udf的Pyspark groupby:在本地机器上的性能较差
我正在尝试对由几个每日文件(每个15GB)组成的巨大数据集进行一些分析。为了更快,仅出于测试目的,我创建了一个非常小的数据集,其中包括所有相关场景。我必须分析每个用户的正确操作顺序(即类似于日志或审计)。 为了做到这一点,我定义了一个udf函数,然后应用了一个groupby。下面的代码重现了我的用例: 这给我带来了以下结果: 是不是太慢了? 我正在用一台现代笔记本电脑和康达。我使用conda na
-
在Thymeleaf中链接绝对URL时th:href和href之间的差异
-
比较两个数据流并并排输出它们的差异
我想我可以做一个逐行和逐列的比较,但有没有更简单的方法?
-
 Apache Spark:客户端和集群部署模式之间的差异
Apache Spark:客户端和集群部署模式之间的差异TL;DR:在Spark独立集群中,客户端和集群部署模式之间有什么区别?如何设置应用程序运行的模式? 我们有一个带有三台机器的Spark独立集群,它们都带有Spark 1.6.1: 主机,也是使用运行应用程序的地方 2台相同的工作机 2)如何使用选择应用程序将运行在哪个上?
-
由于消极前瞻的位置而导致的比赛差异?
我对正则表达式有很多困惑,我正在努力解决它们。这里有以下字符串: 我的两个不同正则表达式,其中我只更改了点的位置: 为什么第一个正则表达式吃最后一个“e”? 这个否定的前瞻性是如何使这个量词不贪婪的?我的意思是为什么它不能使用{end}之外的字符?
-
计算浮点数时可能出现的最大舍入误差
我正在用Java开发一个时间关键型算法,因此没有使用。为了处理舍入误差,我设置了一个误差上限,在这个上限之下,不同的浮点数被认为是完全相同的。现在的问题是,这个界限应该是什么?或者换句话说,当对浮点数(浮点数加、减、乘、除)执行计算操作时,可能出现的最大舍入误差是什么? 通过我做的一个实验,似乎的范围就足够了。 PS:这个问题与语言无关。 编辑:我使用的是数据类型。这些数字是通过的方法生成的。 编
-
 Apache NiFi中处理器属性和Flowfile属性之间的差异
Apache NiFi中处理器属性和Flowfile属性之间的差异我目前的理解是,NiFi处理器属性是特定于该处理器的。那么,向处理器添加新属性将只在该处理器内可见,而不会传递到以后的处理器块? 这就是为什么需要添加在flowfile遍历数据流时保留在flowfile中的元数据: 那么,允许用户在处理器中添加定义和执行所需的自定义属性有什么价值呢?它是否类似于创建可以在其他属性中使用的变量?
-
Laravel在速度和返回内容量上有很大的差异
我一直在测试Laravel,我运行了以下查询: 数据库只包含1条记录,我var_dump$site,我得到的输出类似于下面,除了返回了近900,000个字符。 如果我保持查询简单,例如: 输出为: 对象(照亮\数据库\雄辩\收集)#121(1){[“项目”:受保护]= 这是相当少(1,600个字符),运行第一个查询时的性能很慢,我做了什么错事,因为我担心性能(为什么第一个查询这么慢)。 谢谢
-
SWIG:导入百分比和包含百分比之间的差异
SWIG文档对这两个指令解释如下: > :“SWIG提供了另一个带有指令的文件包含指令。的目的是从另一个SWIG接口文件或头文件收集某些信息,而不实际生成任何包装代码。此类信息通常包括类型声明(例如,typedef)以及可能用作接口中类声明基类的C类。" 我的问题是这两个指令之间有什么区别,使用它们的利弊是什么? 顺便说一下,我只是想了解一些背景信息。我有一个简单的C-python扩展,当我使用上
-
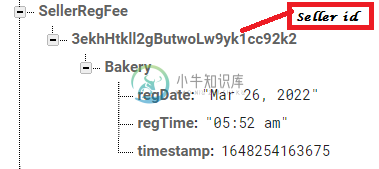 根据firebase节点中保存的时间戳计算日期差
根据firebase节点中保存的时间戳计算日期差在我的应用程序中,它使用android studio和firebase数据库,卖家只要支付注册费,就可以订阅特定的商店(例如面包店)两年。注册时,我正在将注册日期和时间保存到firebase实时数据库中,如图所示: 两年后,我想向卖家展示一个祝酒词,表示订阅期已过。为此,我需要减去注册日期(我可以从fire base节点中获取)和当前日期,我知道如何获得如下所示的当前日期 我只想从上面的代码中减去
-
Cosmosdb sql api和Cosmosdb cassandra api之间的存储差异是什么
大多数文章都提到,如果我们使用Cosmos Db并新建应用程序,我们应该使用Cosmos Db sql api。Mongo api和cassandra api可以在你的应用程序已经与实际的Mongo和cassandra集成,并且我们希望快速迁移到cosmosdb而不改变生态系统的情况下使用。 但是当我们在azure中创建一个新的cosmosdb集群时,它要求api类型。这意味着除了api(查询)接
-
使用循环Java查找多个日期中的最大差异
我试图找出几个日期之间的最大差异,这怎么可能?答案应该是01012001-01012011。我想找出两个列表之间最大的日期间隔,这怎么可能?
-
如何打印差异为1的列表中元素的间隔?
我在下面写的代码保存了进程在中拥有cpu时的时间戳。如果进程当时拥有CPU。例如,如果列表如下所示: 控制台的输出应该是这样的: 我怎么能这么做呢?这就是我迄今为止所做的