《差旅壹号》专题
-
版本差异?Java中的正则表达式转义
似乎正则表达式转义在不同版本的Java中工作方式不同。 > 在Java openjdk 16.0中。1.编辑工作做得很好 在Java openjdk 11.0中。11引发此编译错误: 我知道,我通常对是安全的。我的问题: 自从哪个版本改变了这种行为?为什么会这样?
-
差异性。bind()到arrow函数()=>在React中的用法
假设我有一个函数,它更新状态并将其映射到一个onPoint到一个
-
局部变量和全局变量之间的差异
本文向大家介绍局部变量和全局变量之间的差异,包括了局部变量和全局变量之间的差异的使用技巧和注意事项,需要的朋友参考一下 在本文中,我们将了解局部变量和全局变量之间的区别。 局部变量 通常在函数内部声明它。 如果未初始化,则将垃圾值存储在其中。 在函数开始执行时创建。 功能终止后,它将丢失。 由于可以通过单个功能访问局部变量/数据,因此无法进行数据共享。 需要将参数传递给局部变量,以便它们可以访问函
-
一维(1D)和二维(2D)数组之间的差异
本文向大家介绍一维(1D)和二维(2D)数组之间的差异,包括了一维(1D)和二维(2D)数组之间的差异的使用技巧和注意事项,需要的朋友参考一下 在本文中,我们将了解一维数组和二维数组之间的区别。 一维数组 它有助于存储具有相似数据类型的元素的单个列表。 总字节数计算为变量数组的数据类型与数组大小的乘积。 C ++声明 Java声明 二维数组 它有助于存储“列表列表”或“数组数组”或“一维数组数组”
-
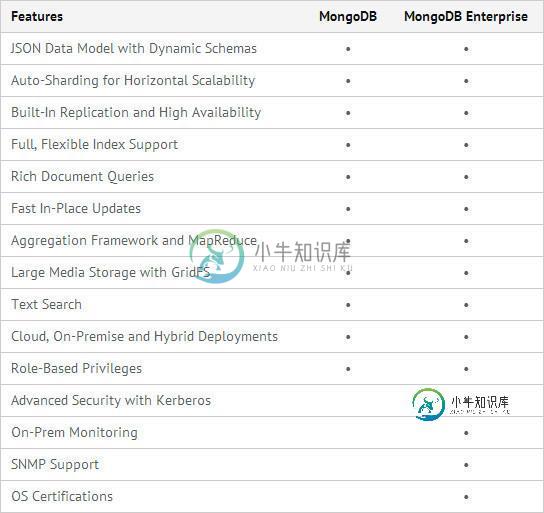 MongoDB社区版和企业版的差别对照表
MongoDB社区版和企业版的差别对照表本文向大家介绍MongoDB社区版和企业版的差别对照表,包括了MongoDB社区版和企业版的差别对照表的使用技巧和注意事项,需要的朋友参考一下 MongoDB社区版本和企业版本差异主要体现在安全认证、系统认证等方面,具体信息参考下表: 版本特性 社区版本 企业版本 JSON数据模型、自由模式 支持 支持 水平扩展的自动分片功能 支持 支持 内置副本以及高可用性 支持 支持 完整的、可扩展的索引支撑
-
Flink中保存点和检查点之间的差异
我知道stackoverflow上也有类似的问题,但在调查了其中几个之后,我知道 > 他们正在使用不同的存储格式 但这些并不是令人困惑的地方,我不知道什么时候该用一个,什么时候该用另一个。 考虑以下两种情况: 如果由于某种原因(例如错误修复或意外崩溃)需要关闭或重新启动整个应用程序,那么我必须使用保存点来恢复整个应用程序
-
Spring切入点指示符差异(在vs执行中)
使用“Eclipse memory Analyzer”分析了应用程序服务器的“堆转储”之后,我发现我的应用程序消耗了450 MB,而”类的实例消耗了这450MB中的30%. 的每个实例(大约)占用6 MB,这是因为每个实例都管理与java.lang.Reflect.Method实例匹配的缓存,而且令人惊讶的是,缓存了很多java方法(我的pointcut表达式没有提到的方法)。 在阅读了Sprin
-
Amazon EC2和AWS Elastic Beanstalk之间的差异[已关闭]
我们不允许在Stack Overflow上提出有关专业服务器或网络相关架构体系管理的问题。您可以编辑问题,使其成为Stack Overflow的主题。 EC2和Beanstalk有什么区别?我想知道关于SaaS、PaaS和IaaS的情况。 要在Wordpress中部署web应用程序,我需要一个可扩展的托管服务。如果有什么比我的目的更好的,也请告诉我。 仅供参考-我想托管和部署多个Wordpress
-
assertEquals(Double,Double)和assertEquals(double,double,delta)之间的Junit差异
问题内容: 我进行了一个junit测试,使用以下命令声明了两个Double对象: 很好,然后我决定将其更改为使用原始double,除非您也提供了增量,否则该结果被弃用了。 所以我想知道在assertEquals中使用Double对象还是原始类型有什么区别?为什么不使用不带增量的对象,但不推荐使用不带增量的基元呢?Java是否在后台执行了已经考虑了默认增量值的操作? 谢谢。 问题答案: 没有断言方法
-
Java匹配与JavaScript匹配之间的结果差异
问题内容: 做一个简单的测试时,我就在用Java编写正则表达式 但是在JavaScript中 这里发生了什么?我可以使我的Java regex模式“ q”的行为与JavaScript相同吗? 问题答案: 在JavaScript中,返回与使用的正则表达式匹配的子字符串。在Java中,检查整个字符串是否与正则表达式匹配。 如果要查找与正则表达式匹配的子字符串,请使用Pattern和Matcher类,例
-
即时编译与堆栈替换之间的差异
问题内容: 他们两个几乎都做同一件事。确定该方法很热,然后编译而不是解释。使用OSR,您只需在编译后立即转到编译版本,而不像JIT,后者是在第二次调用该方法时调用已编译的代码。 除此之外,还有其他区别吗? 问题答案: 通常,即时编译是指在运行时编译本机代码并执行它,而不是(或除了)进行解释。某些虚拟机(例如Google V8)甚至都没有解释器;这些虚拟机甚至没有解释器。他们通过JIT编译执行的每个
-
计算两个Java日期实例之间的差异
问题内容: 我在Scala中使用Java的类,想比较一个Date对象和当前时间。我知道我可以使用getTime()计算增量: 但是,这仅long代表我几毫秒。有没有更简单,更好的方法来获取时间增量? 问题答案: 不幸的是,JDK API严重损坏。我建议使用Joda时间库。 Joda Time具有时间间隔的概念: 编辑:顺便说一句,乔达有两个概念:用于表示两个时刻之间的时间间隔(表示上午8点至上午1
-
.NET和T-SQL之间的字符串比较差异?
问题内容: 在我编写的测试案例中,字符串比较似乎在SQL Server / .NET CLR之间的工作方式不同。 此C#代码: 将输出: 此SQL Server代码: 将输出: 为什么会有所不同? 问题答案: 这在此处记录。 Windows归类(例如)使用Unicode类型的归类规则。SQL排序规则没有。 这导致在两者之间对连字符的区别对待。
-
考虑行之间的“差异”对行进行分组
问题内容: 我有一个表,其中包含开始时间(在示例中使用数字以使其保持简单)以及事件的持续时间。 我想确定“块”及其开始时间和结束时间。 每当前一行的结束时间(开始时间+持续时间)(按开始时间排序)与当前行的开始时间之间的差值为时,应开始一个新的“块”。 这是我的测试数据,包括在注释中尝试进行图形解释的尝试: 第一个块开始于,结束于。由于与下一行的区别是,开始另一个块,终止于。 我可以使用来识别块的
-
使用标准偏差使用mysql删除异常值
问题内容: 我使用下面的查询删除异常值(标准偏差的1.5倍)。 但是它给出了这个错误: 询问: 我不知道这是什么意思。 问题答案: 您可以诱使MySQL通过另一个子选择来做到这一点