《汇川》专题
-
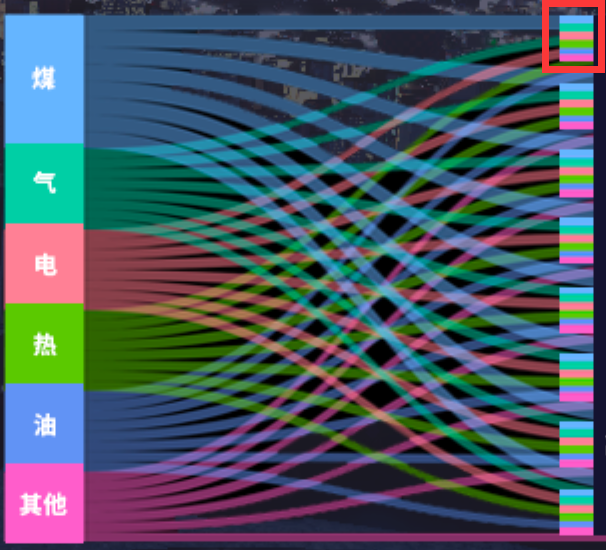 javascript - 如图, echarts桑吉图, 右侧节点的颜色, 如何由汇聚于此的线段颜色组成?
javascript - 如图, echarts桑吉图, 右侧节点的颜色, 如何由汇聚于此的线段颜色组成?翻了好久api和案例都没看到。 就像如图“红框”里的, 右侧某一个区块内的颜色, 不是普通桑吉图指定的固定颜色。 右侧颜色是由:汇聚于此的线段颜色组成。 并且要根据汇聚的颜色的数量, 区分不同色块的高度。 求问这个该如何实现?
-
在Android上使用最新gRPC插件时发生汇编错误->输入隐藏在--proto\u路径中(Gradle 7.0.1)
我正在尝试更新一个Android项目以使用最新的gradle插件(7.0.1),从当前使用的3.6.4。为了做到这一点,考虑到该项目使用的是原型,我需要更新原型和gRPC依赖项,因为当前的依赖项与最新的插件不兼容。 为了使用最新的依赖版本,我遵循了https://github.com/grpc/grpc-java。我将依赖更新为以下版本: 我正在使用最新的protobuf插件 并使用以下代码块生成
-
我怎么能保证一个汇集的AKKA演员只发送和接收来自自己的儿童演员?
我有几个演员在一个池子里。我希望这些演员中的每一个都能创造出儿童演员。问题是,当我创建子角色并保存引用时,我永远不知道哪个子角色将获得池化角色发送给它的消息。该池被创建为smallstMailBox池。在池演员的构造函数中,我这样做: 这是我的孩子。我做一些花样。有人问,也有人说,但结果不是同一个孩子。首先我做一个: 后来我一遍又一遍地做: (adReceive和adSend是AkkaDocume
-
通过Maven surefire-report在汇总格式的单个文件中的单元测试类中的测试执行时间
问题内容: 谁能让我知道如何通过单个文件在一个单元测试类中获得每个单元测试所花费的时间?我已经看到我的每个测试都有文件。基本上,我正在寻找一个汇总了所有执行时间的文件。如果可能,还应按每个测试的执行时间对结果进行排序。 我在MacOSX 10.12.6上使用Maven 3.5和surefire-plugin 2.4.2。 问题答案: 在目前没有让你这样做。它将所有结果写入单独的文件中。如果您觉得这
-
当使用带有代码拆分的汇总时,有没有什么方法可以保留包的目录结构?
考虑到这样的项目结构: 其中文件导入,使用以下配置: 输出结构如下: 当使用代码拆分来减少项目中的冗余代码时,如果不同目录中有多个具有相同文件名的模块,则当rollup写入输出目录时,它会创建一个平面结构。它足够聪明,可以识别多个文件具有相同的名称,并附加一个数字来区分它们。虽然这是工作代码,但在需要它们的页面上维护对这些模块的引用变得很困难——开发人员必须知道哪个编号对应于哪个文件。 在输出多个
-
汇合和卡桑德拉:获取数据异常:无法将数据反序列化到Avro,未知的神奇字节
我遵循了http://www.confluent.io/blog/kafka-connect-cassandra-sink-the-perfect-match/我可以从avro控制台向cassandra插入数据。现在我正在尝试将其扩展到使用水槽,我的机器中设置了水槽,它将拾取日志文件并将其推送到kafka,尝试将我的数据插入cassandra数据库。在文本文件中,我正在放置数据 {“id”: 1,
-
在使用Vue sfc汇总构建的Vue 2组件库中使用Vue 2 Composition API时,为什么会出现错误?
我正在使用vue sfc汇总构建一个组件库。该库以Vue 2为目标,但使用Vue 2 Composition API,以便在时机成熟时更容易移植到Vue 3。 将库发布到npm后,我使用Vue CLI创建了一个空白Vue 2项目(启用TypeScript以Vue 2为目标)。 在中,我安装了组合API作为插件。 然后,在我从库中导入了一个组件进行测试。 然而,当我在浏览器中运行这个时,我得到了以下
-
通过maven surefire报告以汇总格式在单个文件中执行单元测试类中的测试的时间
谁能让我知道如何通过在单个文件中获得单元测试类中每个单元测试所花费的时间?我已经看到我的它有每个测试的文件。基本上,我正在寻找一个单一的文件,所有的执行时间总结。如果可能,还可以按每个测试的执行时间对结果进行排序。 我用的是maven 3.5
-
从全局环境中调用函数,其中包含 dplyr::汇总或变异中的隐式数据帧变量(来自调用 env?)
我想在全局环境中创建一个函数列表,并根据需要在调用中调用它们以突变或汇总,这样它就可以使dplyr代码不那么冗长。问题在于,函数必须使用在数据帧内定义的变量,而不是全局 env。这可能都与对象舀取有关,这对我来说有点棘手。 对于以下所有代码,请加载所需的库: 例如:使用数据集,我想a变量,并使用以下三个函数 我可以在电话中定义它们,总结如下,这很好: 我还可以将函数定义为表达式,然后计算调用中的表
-
使用gdb在指定的可执行文件之外单步执行汇编代码会导致错误“找不到当前函数的边界”
问题内容: 我不在gdb的目标可执行文件之外,甚至没有对应于该目标的堆栈。无论如何,我都想单步执行,以便我可以验证汇编代码中发生的事情,因为我不是x86汇编方面的专家。不幸的是,gdb拒绝执行此简单的程序集级调试。它允许我在适当的断点处设置和停止,但是一旦我尝试单步执行,gdb就会报告错误“找不到当前函数的边界”,并且EIP不会更改。 额外细节: 机器代码是由gcc asm语句生成的,我从objd
-
就汇编语言而言,如果一个结构太大而无法放入寄存器,那么该结构如何通过值返回?[副本]
在 C 中,可以按值返回用户定义类型。在 x86-64 中,ASM 按值返回是通过将返回值移动到 RAX 并将存储的上一个 RIP 值弹出到 RIP 中以返回到调用方来实现的。如何通过值返回大于 RAX 的结构或实际上任何类型的数组?
-
为从目录中读取光栅、将数据汇总到单个光栅并输出新光栅而创建的循环的索引不起作用
我有几个目录,里面都是每日的气候数据。我需要将每日栅格合并为每周栅格,一些是通过值的总和,一些是通过值的平均值。到目前为止,我已经在目录(其中包含每日光栅文件)中创建了一个文件名向量,并为编写了一个
-
c编译器如何处理无符号和有符号整数?为什么无符号和有符号算术运算的汇编代码是相同的?
我在看的书:CS-app 2。c有无符号和有符号的int类型,并且在大多数架构中使用二进制补码算法来实现有符号值;但是学了一些汇编代码之后,发现很少有指令区分无符号和有符号。所以我的问题是: > 区分有符号和无符号是编译器的责任吗?如果是,它是如何做到的? 谁实现两个补码算法——CPU还是编译器? 添加更多信息: 在学习了更多的指令后,实际上有一些指令区分有符号和无符号,例如setg、seta等。
-
汇流HDFS接收器连接器:Kafka主题与普通字符串格式的HDFS在拼花格式失败与Avro模式必须是一个记录错误
我已经在我的虚拟机中安装了docker confluentinc/cp-kafka-connect:4.0.0映像。我有兴趣获取 kafka 主题,它是镶木地板格式的 hdfs 纯文本数据(字符串格式)。 我完成了以下配置。 /etc/kafka/connect-standard.properties /etc/Kafka-connect-HDFS/快速启动-hdfs.properties 在独立
-
请在以下词汇里找出你所理解的部分,并谈谈其含义、来源或使用场景:VR\AR\MR、ASO、魔性、阿里月饼门、开口跪、套路、CP、吃瓜观众
本文向大家介绍请在以下词汇里找出你所理解的部分,并谈谈其含义、来源或使用场景:VR\AR\MR、ASO、魔性、阿里月饼门、开口跪、套路、CP、吃瓜观众相关面试题,主要包含被问及请在以下词汇里找出你所理解的部分,并谈谈其含义、来源或使用场景:VR\AR\MR、ASO、魔性、阿里月饼门、开口跪、套路、CP、吃瓜观众时的应答技巧和注意事项,需要的朋友参考一下 VR/AR/MR:虚拟现实/增强现实/混合现