《后面的秋招会越来越卷吗》专题
-
 秋招美团后端一面
秋招美团后端一面面试官很专业,比较严肃,但不是咄咄逼人那种,觉得你的回答没问题(或者你说不会)就说ok,有问题就会根据你说的话继续深究,跑题会直接打断,还是有点流汗了 timeline 投递7.30——笔试、AI面试8.10——第二次笔试8.17——一面8.26 全长70min,有些问题忘了 开始 自我介绍 手撕,两道 两个有序链表合并为一个,简单 给定两个字符串s和t(只含小写字母,长度1e4),求t中是否有子
-
 美团后端秋招一面
美团后端秋招一面有一说一,暑期实习面美团二面的面试官态度就感觉很恶劣(虽然最后oc了)。这次一面感觉是最恶心的一次面试了😅面试官全程摆着一副脸。 1. 问实习或者学校里学的东西有没有什么之后经常用到工作中的? 后面讲到了分库分表,问我为什么要分表,我说提升性能,又问为什么会提升性能,我从索引角度说了下,又问为什么知道是单表超过1000w或者1000w行要分表,怎么知道的,,,,,一直问下去问了很多,最后问b+树
-
 虾皮秋招后端二面
虾皮秋招后端二面自我介绍 ●介绍一下java的并发问题,以及java是通过什么去解决这个并发问题的,如synchorized,voliate等 ●voliate是怎么做到可见性的,是变量前还是变量后,为什么需要这个可见性 ●java中还有没有别的实现可见性的关键字或者技术 ●介绍一下java的反射是什么,使用场景是什么,反射的底层是什么实现的 ●aop是怎么进行切入点切入的 ●介绍一下spring,为什么要用到s
-
 虾皮秋招后端一面
虾皮秋招后端一面自我介绍 四个场景题: select ..... where B = 20 and C > 200, select .... where A = 10 and B = 20 and C = 30,如何建立索引最高效 4TB的文件,文件每一行都存储一行数字,如何高效判断一个数字在不在这个文件里面,限定内存 40亿数字,限定100M,如何找到最大的100个数字 如何设计一个更加高效的LR
-
 美团秋招后端一面
美团秋招后端一面已经提前入职团子了,分享下秋招面经~ 八股: 1,指针和引用的区别,常引用了解吗,简单介绍下 2,说下多态,多态的作用和使用场景 3,构造函数和析构函数可以是虚函数吗 4,C++中内存区域分布是怎样的 5,拷贝构造函数介绍下,如何用 6,浅拷贝和深拷贝区别 7,虚拟地址了解吗 8,虚拟内存作用(进程隔离,内存连续,mmap),优势和缺点 9,七层网络模型,每层的作用 10,TCP三次握手四次挥手的
-
 秋招太卷,春招捡漏——24春招总结
秋招太卷,春招捡漏——24春招总结今天盲审通过了,悬着的心终于落下(牛客许愿好灵)。简单总结一下自己的24届春招历程,给大家提供一个参考。 个人背景:211本中9硕,一段大厂测开实习(没人问,1%的概率),3月份没卷到大厂后端,找了份国企后端实习(基本没写代码),一个秒杀项目。只投后端开发,秋招拿了些小厂的offer,大厂颗粒无收,阿里百度,简历笔试挂,大厂只有美团和腾讯进了二面,但是项目经不起拷打也是挂了。因为最初是打算进国企的
-
在Python中超越工厂
问题内容: 从Java到Python,有人告诉我工厂不是Pythonic。因此,我正在寻找 一种 执行以下操作的Python方法。(我过分简化了我的目标,因此不必描述整个程序,这很复杂)。 我的脚本将读取人员名称(以及有关人员的一些信息),并由此构造人员类型的对象。名称可以重复,每个名称只需要一个Person实例。这些人也可能属于男人和女人的子类。 一种实现方法是创建一个PersonFactory
-
6.1. 文件系统跨越
6.1. 文件系统跨越 无论你用什么方法使用文件,你都要在某个地方指定文件名。在很多情况下,文件名会作为fopen()函数的一个参数,同时其它函数会调用它返回的句柄: <?php $handle = fopen('/path/to/myfile.txt', 'r'); ?> 当你把被污染数据作为文件名的一部分时,漏洞就产生了: <?php $handle = fopen("/path/to/{$_
-
 蔚来 秋招前端一二面面经
蔚来 秋招前端一二面面经⏱️投递时间线 7.25 投递 -> 8.2 笔试 -> 8.12一面 -> 8.23 二面 🗃️面经: 一面:(1h) 自我介绍。 熟悉React还是Vue,问了一些React的东西,主要是hooks相关的。 说一下let和const的区别。 说一下js的作用域有哪些。 讲一下Nodejs的事件循环,浏览器的事件循环也可以说一下。 问了一下Rust的ownership相关问题。(因为我的博客上
-
不确定为什么会发生越界异常
获取一个越界异常,但不明白原因。我的递归函数每次都调用自己,从数组列表中删除一个项,直到它为空。一旦它为空,就应该填充行,然后我们将值添加回列表。我想在最后一个元素上,由于列表长度的原因,它抛出了一个异常,它不想删除最后一个元素。有什么办法可以绕过这个吗?有没有可能是不同的错误? 预期的结果将是根据数独规则随机填充董事会[][]。相反,我们在线程“main”java.lang.IndexOutOf
-
 越凡创新-成都-线下面试-Java
越凡创新-成都-线下面试-Java越凡创新-成都-线下面试 spi 类加载器 类加载的几个过程:加载、验证、准备、解析、初始化。然后是使用和卸载了 1. 加载(Loading) 加载阶段是将类的字节码文件加载到内存中,并创建一个对应的Class对象。 2. 验证(Verification) 验证阶段会对字节码进行验证,以确保其符合Java虚拟机规范。 3. 准备(Preparation) 准备阶段是为类的静态变量分配内存空间,并设
-
 快手java后端一面(秋招以来体验最差)
快手java后端一面(秋招以来体验最差)面试官那边网络不好,他说我面试别人都没问题,态度极其不耐烦; 面试官:我看你的鼠标光标,不在页面内,这样会被判作弊。我表示很无语!!! 整个面试过程充斥着面试官对我的鄙视,好像在说你这么差, 你个菜鸡,你怎么好意思让我面试你的? 面试体验总结:我只想说,你在我这个应届生的时候,也不见得你比我强,这个工作你不想干可以不干,有的是人干!!! 1、自我介绍; 2、时延如何优化? 3、快排时间复杂度、二分
-
我正在对长度为10000到75000的整数数组进行合并排序。我的时间越来越奇怪了。为什么会这样?
我正在为我的算法类做一个赋值,我必须证明内部合并排序的时间复杂度为O(n logn)。为此,我制作了长度从10000个元素到75000个元素的数组。然后,我将随机数加载到10000以下的数组中,并将数组长度与排序所需的时间一起输出到控制台。 奇怪的结果是,有些数组需要约15毫秒的给定或获取,而另一些数组则需要0毫秒,即使数组的长度要长数万个整数。你知道为什么吗?我可以上传输出的屏幕截图,但需要有人
-
 2023.9.9 好未来一面 前端 秋招
2023.9.9 好未来一面 前端 秋招项目有什么亮点,拷打 平常如何学习前端 计网一些基础 (刚睡醒懵的答得不太好) 编译型语言与解释性语言的差别 弱类型语言一定是解释性语言吗 一些工作场景问题:当你接触一门新的架构语言比如React,uniapp 如何在工作中能快速上手 当项目架构为TS类型但是引入的包为JS类型,该怎么处理 说说对BFC的理解,有哪些方式可以创建BFC 如何实现CSS三栏布局 CSS如何实现省略号 算法题 手撕 二
-
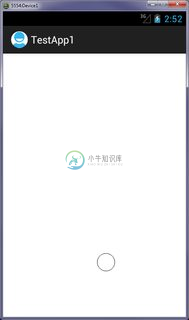 为什么像素密度越高的设备屏幕空间越小?(日食AVD)
为什么像素密度越高的设备屏幕空间越小?(日食AVD)在Eclipse的AVD中,我创建了两个除了密度值之外完全相同的设备。设备1具有240的;设备2具有160。两者的分辨率均为480x800。 有人能给我解释一下为什么设备1屏幕上的元素看起来“更大”?既然它们具有相同的分辨率,它们不应该显示相同数量的像素吗?如果有的话,因为设备1的密度更高,它不应该显示更多的细节/屏幕不动产吗? 设备1 设备2 Screeshots-(单击以获取更大的变体) 如上