《梅卡曼德机器人实习》专题
-
机器学习:聚类分析
监督学习使用标记数据对 (x,y) 学习函数:X\rightarrow Y 。但是,如果我们没有标签呢?这类没有标签的学习方式被称为无监督学习。 无监督学习:如果训练样本全部无标签,则是无监督学习。例如聚类算法,就是根据样本间的相似性对样本集进行聚类试图使类内差距最小化,类间差距最大化。 主要用途: 自动组织数据。 理解某些数据中的隐藏结构。 在低维空间中表示高维数据。
-
机器学习:梯度下降
迭代与梯度下降求解 求导解法在复杂实际问题中很难计算。迭代法通过从一个初始估计出发寻找一系列近似解来解决优化问题。其基本形式如下
-
机器学习:Rademacher复杂度
对于给定训练集 {D}' ,我们希望基于学习算法 L 学得的模型所对应的假设 h 尽可能接近目标概念 c。 为什么不是希望精确地学到目标概念c呢?因为机器学习过程受到很多因素的制约: 获得训练结果集 {D}' 往往仅包含有限数量的样例,因此通常会存在一些在 {D}' 上“等效”的假设,学习算法无法区别这些假设。 从分布 D 采样得到的 {D}' 的过程有一定偶然性,即便对同样大小的不同训练集,学得结果也可能有所不同。
-
机器学习:特征降维
主成分分析是一种降维方法,通过将一个大的特征集转换成一个较小的特征集,这个特征集仍然包含了原始数据中的大部分信息,从而降低了原始数据的维数。换句话说就是减少数据集的特征数量,同时尽可能地保留信息。降维是将训练数据中的样本(实例)从高维空间转换到低维空间,该过程与信息论中有损压缩概念密切相关。同时要明白的,不存在完全无损的降维。
-
机器学习:基本概念
机器学习即Machine Learning,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。目的是让计算机模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断完善自身的性能。简单来讲,机器学习就是人们通过提供大量的相关数据来训练机器。
-
 网易机器学习一面
网易机器学习一面【写面筋积累好运】 半小时的第一次面试,也是时隔1个月来的面试,希望不是kpi吧。 #网易信息集散地# #23届找工作求助阵地# 项目没有怎么问,基本上是问的项目里面的八股文。 手写某某网络传播公式。 手写xgb的计算公式。 解释用到的网络结构。 问dataset和dataloader的区别。 问python的迭代器什么的(不会) 手撕了一个回溯算法的题,写出来了,但是面试官说没有看到输出,慌得一
-
 机器学习算法面试
机器学习算法面试问题答案可关注公众号 机器学习算法面试,回复“资料”即可领取啦~~ 1.机器学习理论 1.1 数学知识 1.1.1 机器学习中的距离和相似度度量方式有哪些? 1.1.2 马氏距离比欧式距离的异同点? 1.1.3 张量与矩阵的区别? 1.1.4 如何判断矩阵为正定? 1.1.5 距离的严格定义? 1.1.6 参考 1.2 学习理论 1.2.1 什么是表示学习? 1.2.2 什么是端到端学习? 1.2
-
 美团机器学习面经
美团机器学习面经8.6笔试 四道算法题+三道多选题,算法题简单到中等难度 8.15一面 总结:全程1个小时,面试官人很好,会引导,会告诉你简历怎么改还有面试方面的问题,并且提问问题我回答之后面试官都会说一下自己的看法和正确的解答,我觉得还挺有帮助的。 先确认面试者信息,并介绍了下自己,然后让我自我介绍 挑一个自己参与度高的项目讲一讲 挖各种细节,挖的很深,所有流程都问得很仔细,并且看得出面试官有在思考和针对提问
-
我们可以在 react 本机写入该卡后使 NFC NDEF 卡密码保护吗
我正在使用react-native-nfc管理器包从我的应用程序读写NFC卡,我想从我的应用程序写入我的卡,没有其他应用程序可以更改数据。我已经从playstore中浏览了多个应用程序,其中一个是NFC工具,因为它有密码保护功能,而我在react-native-nfc管理器中无法获得该功能。有人能告诉我吗,我应该如何在反应本机或任何其他方式中应用密码保护NFC功能,而不使卡只读
-
Stanford CoreNLP的德语解析器的依赖项为null
-
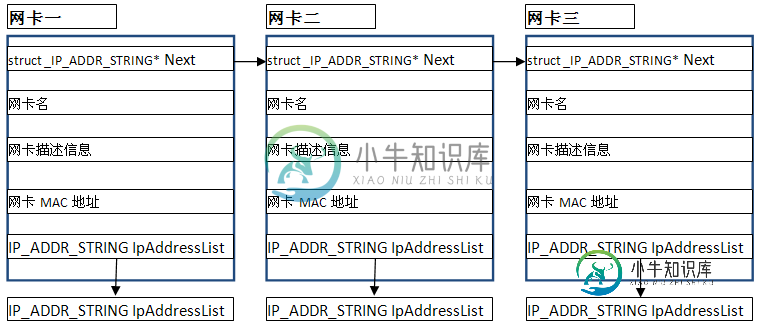 C++获得本机所有网卡的IP和MAC地址信息的实现方法
C++获得本机所有网卡的IP和MAC地址信息的实现方法本文向大家介绍C++获得本机所有网卡的IP和MAC地址信息的实现方法,包括了C++获得本机所有网卡的IP和MAC地址信息的实现方法的使用技巧和注意事项,需要的朋友参考一下 一台机器上可能不只有一个网卡,但每一个网卡只有一个MAC地址,而每一个网卡可能配置有多个IP地址;如平常的笔记本电脑中,就会有无线网卡和有线网卡(网线接口)两种;因此,如果要获得本机所有网卡的IP和MAC地址信息,则必须顺序获得
-
对存储在卡桑德拉数据库上的 JSON 对象进行查询火花
我在cassandra DB上构建了结构来存储操作系统数据的时间序列数据,如服务、进程和其他信息。为了理解如何使用Cassandra来存储JSON数据并通过条件的CQL查询检索数据,我倾向于简化模型。因为在整个模型数据库中,我将拥有比report_object更复杂的类型,如hashMap数组的hashMap,例如:Type
-
新的卡桑德拉项目 - 阿斯蒂亚纳克斯还是Java驱动程序?
我正在用Cassandra开始一个新项目(并计划使用最新的稳定版(1.2.x))。我尝试过几种不同的Java库,如Hector、Astyanax、Cassandra jdbc。。。 其中,(简而言之)我的选择是阿斯蒂亚纳克斯。但后来我也发现并尝试了数据堆栈的Java驱动程序,它支持新的CQL二进制协议,如果你只使用CQL,它要干净得多。而且1.0.0 GA版本似乎很快就会发布。 你会推荐哪一个?谢
-
什么是最好的方式来坚持大OneTo多国协会在卡桑德拉?
在 RDB 中 A 和 B 之间具有较大的一到许多关联(约 1 详细地说,A是B的持久性集,由于一些永久性的业务过程,它应该不断发生轻微的变化。B中的一些可能会被添加,其他一些可能会被删除。以可分页的方式选择B非常重要。 由于将数据存储迁移到Apache Cassandra,考虑该关系的数据模型。 我想最好的解决方案是将A存储为一行,其中列标识为B。 色谱柱系列A: 这是一个好方法吗?如何实现它?
-
基于时间戳列的时间序列数据的卡桑德拉数据清除
我每天都在cassandra中存储时间序列数据。我们希望每天归档/清除超过2天的数据。我们正在使用Hector API来存储数据。有人能建议我每天删除超过2天的cassandra数据的方法吗?对cassandra行使用TTL方法是不可行的,因为删除数据的天数是可配置的。现在表格中没有时间戳列。我们计划添加时间戳列。但问题是,时间戳不能单独用于where子句,因为这个新列不是主键的一部分。请提供您的