《内存》专题
-
Java:什么是 Java 的内存模型?
在了解什么是 Java 内存模型之前,先了解一下为什么要提出 Java 内存模型。 之前提到过并发编程有三大问题 CPU 缓存,在多核 CPU 的情况下,带来了可见性问题 操作系统对当前执行线程的切换,带来了原子性问题 译器指令重排优化,带来了有序性问题 为了解决并发编程的三大问题,提出了 JSR-133,新的 Java 内存模型,JDK 5 开始使用。 简单总结下 Java 内存模型是 JVM
-
 伙伴系统管理动态内存
伙伴系统管理动态内存主要内容:可利用空间表中结点构成,分配算法,回收算法,总结前面介绍了系统在分配与回收存储空间时采取的边界标识法。本节再介绍一种管理存储空间的方法—— 伙伴系统。 伙伴系统本身是一种动态管理内存的方法,和边界标识法的区别是: 使用伙伴系统管理的存储空间,无论是空闲块还是占用块,大小都是 2 的 n 次幂(n 为正整数)。 例如,系统中整个存储空间为 2 m 个字。那么在进行若干次分配与回收后,可利用空间表中只可能包含空间大小为:2 0、2 1、2 2、…、
-
限制Vaadin会话的内存消耗
是否可以限制会话和与之相关的请求可以使用的内存量? 例如,我希望将每个用户会话限制为一兆字节。此限制应适用于处理请求时创建的任何对象。有可能吗?
-
添加图像时PDFBox内存不足
我正在使用PDFBox从我的webapp中提取数据并将其放入PDF。我有一个方法,在每个PDF页面上绘制标题。但是,当我向每个页面添加图像时,文档的内存就会耗尽。我想知道有没有人有什么解决的办法?下面是我的drawHeader方法: public static void drawHeader(PDDocument doc,PDPage page,PDPageContentStream conten
-
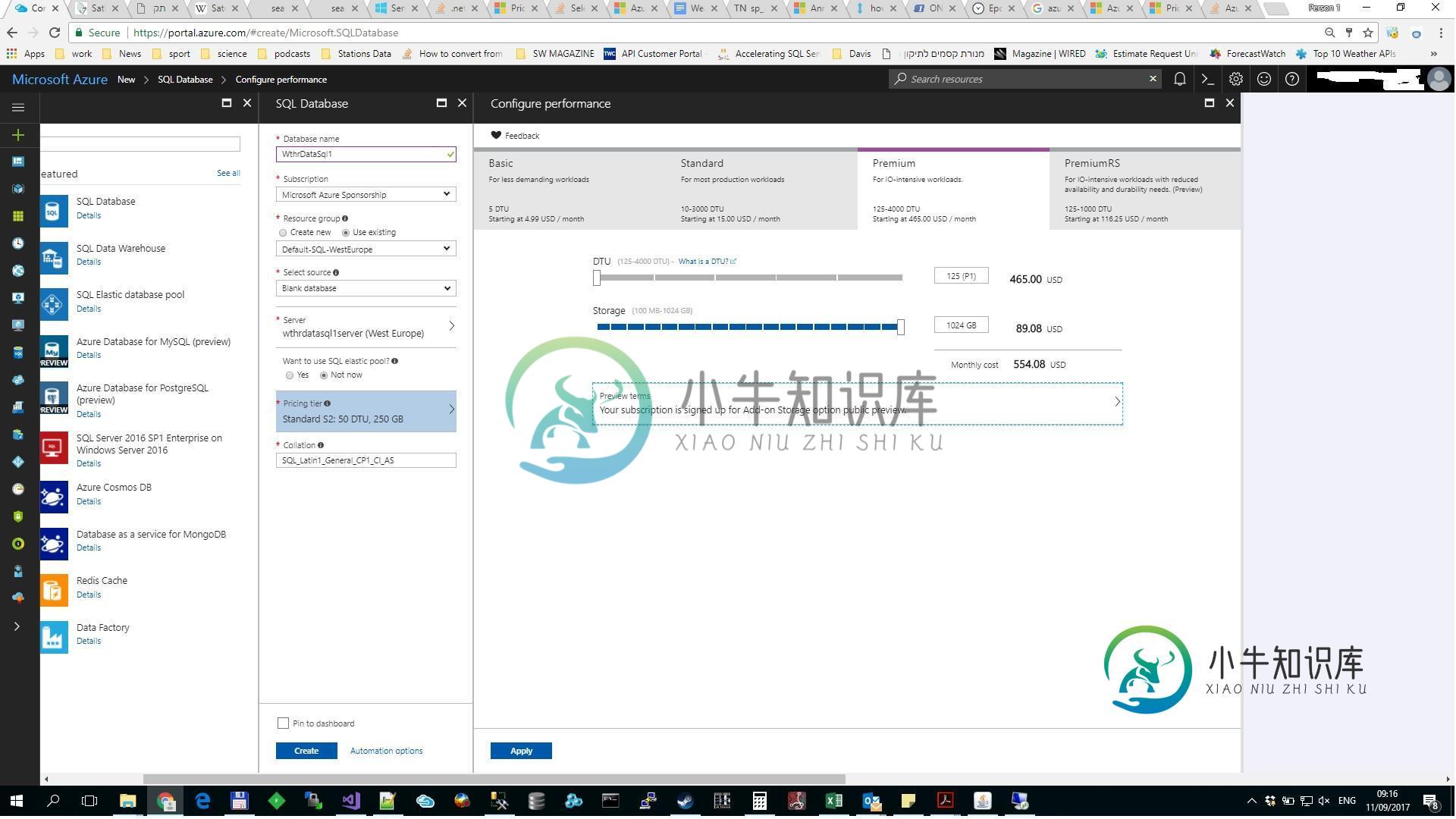 具有2TB内存的Azure高级SQLDB
具有2TB内存的Azure高级SQLDB在单个数据库的Azure定价中,请参见链接 它指出:在以下地区可以使用1 TB以上的高级存储层:美国东部2、美国西部、西欧、东南亚、日本东部、澳大利亚东部、加拿大中部、加拿大东部、德国中部、美国弗吉尼亚州。计划更广泛地提供。在其他地区,高级层中的最大存储容量限制为1 TB。 当我创建SQL数据库时,我尝试使用高级125 DTU设置2 TB的内存,但不能超过1 TB。 我在西欧 我不想在1750 D
-
离堆内存是Java/JVM标准吗?
我在阅读HBase文档时遇到了离堆读取路径,据我所知,离堆是内存中的一个地方,Java在那里存储垃圾回收器无法触及的对象。我还去搜索了一些方便使用离堆内存的libs,并找到了Ehcatche,但是,我找不到任何关于他的oracle或JVM的官方文档。那么,这是JVM的标准功能,还是某种程度的攻击,如果是,那么底层的类和技术是什么。
-
如何用Clang发现内存泄漏
我已经在我的机器(ubuntu)中安装了Clang,以便在我的C代码中查找内存泄漏。我写了一个示例代码来检查它的工作情况,如下所示: 我在互联网上找到了一些编译选项 和 但它们都没有出现内存泄漏的迹象。 扫描构建:使用“/usr/bin/clang”进行静态分析 扫描构建:删除目录“/tmp/scan-build-2015-07-02-122717-16928-1”,因为它不包含报告 扫描构建:未
-
热点Java/JVM如何存储内存?
除了这些地方之外,hostspot JVM进程还在哪里存储内存: 烫发 终身制发电 伊甸园空间 从空间 到空间 代码缓存 也就是说:热点进程可以保留哪些可能的方式 我能想到的一些答案(让我知道这些是不是真的): 用于线程栈的虚拟内存没有用这些数字表示 任何加载的dll或文件。 编辑: 给出的一些其他答案: Java.exe本身 JNI方法可以分配内存本身 任何本机代码(例如来自DLL)都可以分配内
-
谷歌驱动器,上传内存流
这段代码运行良好: 有人能帮我修一下密码吗?
-
 JVM提交的堆内存多于Xmx
JVM提交的堆内存多于Xmx我有这些jvm参数集
-
SpringBoot执行器InMemoryAuditEventRepository的内存泄漏
我在spring引导应用程序中面临内存泄漏,在使用Eclipse MAT进行堆转储分析之后,它指出了spring boot执行器中潜在的内存:精确地说是使用InMemoryAuditEventRepository(审计事件)。 禁用此内存审核事件的最佳方法是什么: 删除spring-boot-acturtor依赖项 management.endpoints.enabled-by-default=t
-
在Linux上搜索进程的内存
问题内容: 如何在Linux中搜索进程的内存状态?具体来说,我希望确定某些感兴趣的区域,并定期查看它们,有时可能会拨出新的价值。 我怀疑答案可能涉及对ptrace()的调用,并读取/ proc / [pid] / mem ,但是还需要继续。 问题答案: 我已经为所需的功能开发了一些代码。 memutil模块提供了进程内存区域迭代,并在ptrace模块和readmem可执行文件的帮助下读取pytho
-
OpenSSL函数EVP_EncryptFinal_ex中的内存泄漏
问题内容: 我根据教程实现了加密过程: http://www.openssl.org/docs/crypto/EVP_EncryptInit.html# 当我运行它通过低谷并得到以下报告: 我下载了OpenSSL的源代码。在ERR_put_error内部,我看到了ERR_get_state中的内存分配,并在err_clear_data内部释放了内存,但是累积了err_clear_data内部的逻辑
-
使用GDB进行Python内存调试
问题内容: 我们有一个使用OpenSSL的Python绑定的Linux应用程序,我怀疑它会导致随机崩溃。有时,我们会看到它崩溃并显示以下消息: Python致命错误:GC对象已被跟踪 这似乎是库方面的编程错误,或者是内存损坏的症状。给定一个核心文件,有什么办法知道它执行的最后一行Python源代码?还是如果它附加在GDB中?我意识到这可能是所有已编译的字节码,但是我希望那里有人解决了这个问题。当前
-
Erlang及其对堆内存的消耗
问题内容: 我在HP Proliant服务器上运行了高度并发的应用程序。该应用程序是我用erlang编码的文件系统索引器。它在文件系统上找到的每个文件夹中产生一个进程,并将所有文件路径记录在碎片化的Mnesia数据库中。(数据库由表的类型组成,其文件系统的屏幕快照可在 此处 查看。) 下面显示了完成文件系统的高强度工作的代码片段: 该函数是通用的,它需要两个。一个乐趣:与最热门目录一起使用,找到的