《58集团》专题
-
kubeadm canot联接集群
您的Kubernetes控制飞机已成功初始化! 要开始使用集群,您需要以普通用户的身份运行以下内容: mkdir-p$home/.kube sudo cp-i/etc/kubernetes/admin.conf$home/.kube/config sudo chown$(id-u):$(id-g)$home/.kube/config 和输出: 此节点已加入群集:*证书签名请求已发送到apiserv
-
Neo4j中的聚集图
我手头有多个Neo4j图,比如G1、G2和G3。如何有效地将所有图迁移到一个图中。在图中,G1、G2和G3具有标签G1、G2和G3,并且从不相互连接。 我使用Neo4j 2.3,但3.0也将被考虑。 谢谢 编辑 好的。我实际上使用的是Spring Date Neo4j,它很难连接到多个Neo4j实例。所以我决定把所有的图放到一个实例中,用标签来区分它们。这够清楚了吧?
-
SpringBoot Redis集成测试
-
 秋招凉经集锦
秋招凉经集锦双飞一本,23届Java求职0offer选手,感觉自己来牛客到现在还没做过什么贡献,牛油们的回帖非常热情诚恳,本着滴水之恩当涌泉相报的精神,随便写一些可能没什么用的秋招凉经,也算给自己秋招一个交待吧,如果能给路过的牛油一些帮助那就更好了。 一、经纬恒润(一面挂) 二、兰亭集势(三面HR挂) 一面: 二面: 三、西安趣联科技-实习岗(挺看好公司发展的,二面挂) 一面: 线程池怎么创建,核心参数有哪些
-
 集度c++一面,40min
集度c++一面,40min算法题两道,各给15分钟,是否存在根节点到叶子结点和等于某个某个数值的路径,链表重排 c++,epoll和poll,rpc(自己的项目),智能指针 反问#面经##校招##秋招#
-
MongoDB查询大集合
我有一个名为“Prices”的MongoDB集合,我试图查询“startDate”和“endDate”之间的价格。 该集合每10秒存储一次价格,但是当查询此集合以绘制图形时,每1-2分钟的价格才是真正重要的。 我尝试用两种不同的方式编写此查询: 方法1:使用{$gte:startDate,$lte:endDate} 此方法引发以下错误: 如果删除排序('-timestamp')行,并再次运行此查询
-
多集群Kafka设置
我想建立一个多kafka集群,大约有3个zookeeper实例,每个集群中有3个kafka代理,每个kafka经纪人大约有5个主题和5个分区。有什么设置指南可以参考吗? PS:我可以找到带有多个Kafka代理的单个zookeeper实例的信息,但不能找到带有多个zookeeper实例的设置。
-
TestNG + Spring集成测试
主要内容:1. 项目依赖,2. Spring组件,3. TestNG + Spring在本教程中,我们将演示如何使用TestNG测试Spring的组件。 使用的工具 : TestNG 6.8.7 Spring 3.2.2.RELEASE Maven 3 Eclipse IDE 1. 项目依赖 为了演示,首先创建一个名称为:TestngSpringIntegration 的 Maven 项目。 要将Spring与TestNG集成,您需要包依懒,添加以下内容: 创建文件:pom.xml
-
.NET Core垃圾收集
主要内容:垃圾收集的优势,垃圾收集的条件,阶段过程在本章中,我们将介绍垃圾收集的概念,垃圾收集是.NET托管代码平台最重要的特性之一。 垃圾收集器(GC)管理内存的分配和释放。 垃圾收集器用作自动内存管理器。 我们不需要知道如何分配和释放内存或管理使用该内存的对象的生命周期 每当使用关键字声明对象或将值类型装箱时,都会进行分配。分配通常非常快。 当没有足够的内存分配一个对象时,GC必须收集和处理垃圾内存以使内存可用于新的分配。 这个过程被称为垃圾
-
Java16 垃圾收集器
Java 15 使 ZGC、Z 垃圾收集器成为标准功能。它是 Java 15 之前的一个实验性功能。它是低延迟、高度可扩展的垃圾收集器。 ZGC 是在 Java 11 中作为一项实验性功能引入的,因为开发人员社区认为它太大而无法提前发布。 即使在机器学习应用程序等海量数据应用程序的情况下,ZGC 也具有高性能和高效工作。它确保在处理数据时不会因垃圾收集而长时间停顿。它支持 Linux、Window
-
Java15 垃圾收集器
Java 15 使 ZGC、Z 垃圾收集器成为标准功能。它是 Java 15 之前的一个实验性功能。它是低延迟、高度可扩展的垃圾收集器。 ZGC 是在 Java 11 中作为一项实验性功能引入的,因为开发人员社区认为它太大而无法提前发布。从那时起,对这个垃圾收集做了很多改进,例如 - 并发类卸载 取消提交未使用的内存 支持班级数据共享 NUMA 多线程堆Pre-touch 最大堆大小限制从 4 T
-
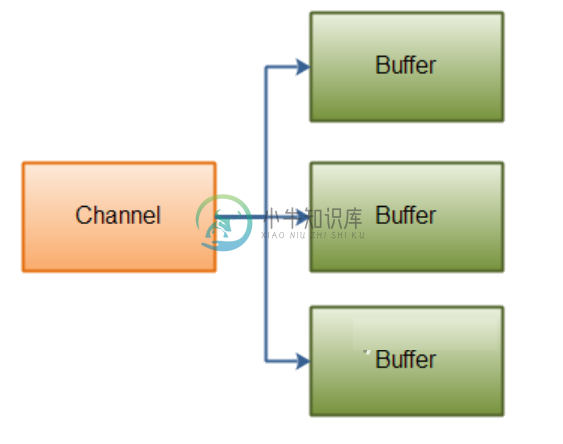 Java NIO 分散/聚集
Java NIO 分散/聚集主要内容:1 分散/聚集的介绍,2 分散读取,3 聚集写入1 分散/聚集的介绍 Java NIO带有内置的分散/聚集功能。分散/聚集是在读取和写入Channel中使用的概念。 从Channel分散读取是将数据读取到多个缓冲区中的读取操作。因此,通道将数据从通道“分散”到多个缓冲区中。 对Channel的聚集写入是一种将来自多个缓冲区的数据写入单个通道的写入操作。因此,通道将来自多个缓冲区的数据“聚集”到一个Channel中。 在需要分别处理传输数据的各个
-
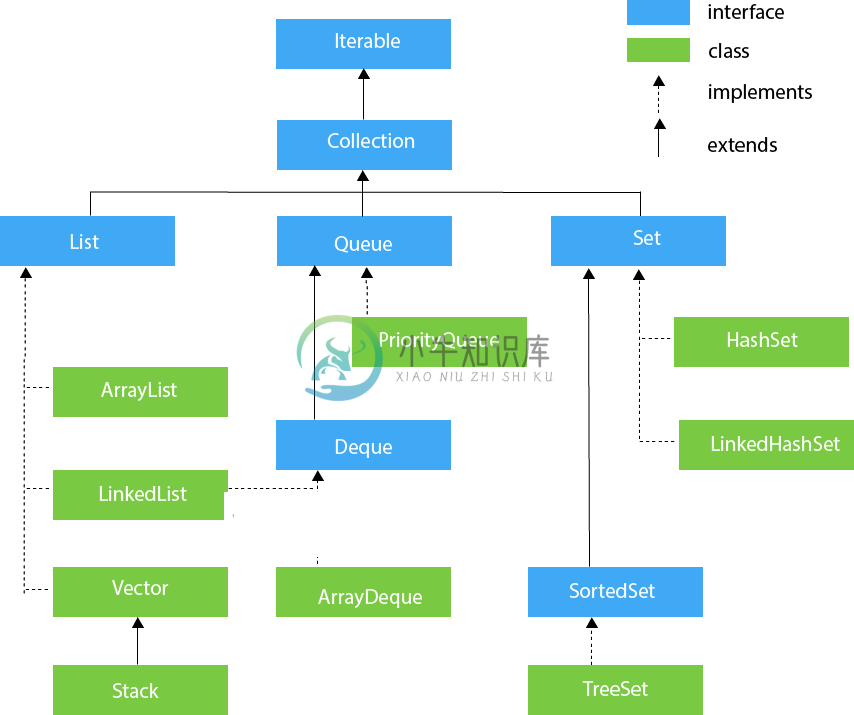 什么是Java集合
什么是Java集合主要内容:1 什么是Java集合,2 Java集合层次结构,3 Java Collection接口的方法,4 Iterator接口,5 Iterable接口,6 Collection接口,7 List接口,6 ArrayList,7 LinkedList,8 Vector,9 Stack,10 Queue接口,11 PriorityQueue,12 Deque接口,13 ArrayDeque,14 Set接口,15 HashSet,16 LinkedHashSet,17 SortedSet接口,
-
Spring Data Redis集成Fastjson
主要内容:1 XML配置方式,2 注解方式通常我们在 Spring 中使用 Redis 是通过 Spring Data Redis 提供的 RedisTemplate 来进行的,如果你准备使用 JSON 作为对象序列/反序列化的方式并对序列化速度有较高的要求的话,建议使用 Fastjson 提供的 GenericFastJsonRedisSerializer 或 FastJsonRedisSerializer 作为 RedisTempla
-
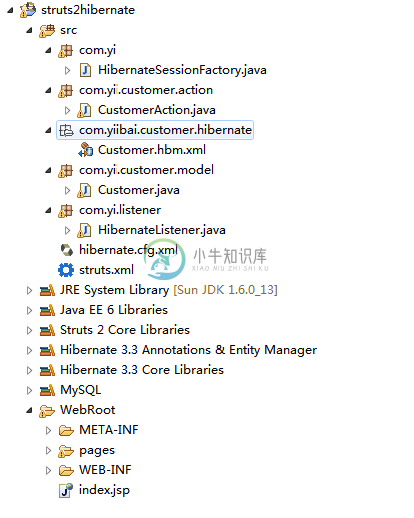 Struts2+Hibernate集成实例
Struts2+Hibernate集成实例主要内容:1. 工程目录结构,2. MySQL表结构脚本,4. Hibernate 相关配置,5. Hibernate ServletContextListener,6. Action,7. JSP 页面,8. struts.xml,9. 实例测试执行,参考在 Struts2 中,没有官方的插件集成Hibernate框架。但是,可以通过以下步骤解决方法: 注册一个自定义的 ServletContextListener 在 ServletContextListener 类, 初始化Hibernat