《石化盈科》专题
-
MongoDB查询优化
问题内容: 我希望从我的用户模型中检索一些信息,如下所示: 在主页中,我有一个 位置 过滤器,您可以在其中浏览来自国家或城市的用户。 所有字段还包含其中的用户数: 在主页上,然后我还有“学生和老师”页面,我希望仅提供有关这些国家和城市有多少老师的信息… 我想做的是创建一个对MongoDB的查询,以通过单个查询检索所有这些信息。 此刻查询如下: 问题是我不知道如何获取所需的所有信息。 我不知道如何获
-
C ++ JSON序列化
问题内容: 我想要一种尽可能自动地将对象序列化和反序列化为JSON的方法。 序列化: 对我来说,理想的方式是,如果我在实例JSONSerialize()中调用,它将返回带有JSON对象的字符串,该对象具有该对象的所有公共属性。对于那些原始值,这很简单,对于对象,它应该尝试调用每个JSONSerialize()或ToString()或类似的东西来递归序列化所有公共属性。对于集合,它也应该正确运行(只
-
初始化接口?
问题内容: 在当前的问题中(我将文件打印到Java中的物理打印机),我一直在疯狂地遍历代码,试图从所使用的每个类的javadoc中吞噬所有有用的丢失信息。 现在,我从以前的问题中抽出了很多代码,所以有相当一部分我不是自己写的。我注意到的问题是,我抓取的代码正在初始化一个对象,例如实现接口(Doc)的“SimpleDoc”并将其分配给该接口? 小代码段: 现在,据我所知,我们创建了对象。我熟悉继承,
-
自动并行化
问题内容: 您对将尝试获取代码并将其自动拆分为线程的项目有何看法(可能是编译时,可能是在运行时)。 看下面的代码: 这种代码可以自动拆分为两个并行运行的线程。您是否认为有可能?从理论上讲,我感觉这是不可能的(这使我想起了停顿的问题),但是我不能证明这种想法是正确的。 您认为这是一个有用的项目吗?有没有类似的东西? 问题答案: 在一般情况下是否可以知道一段代码是否可以并行化并不重要,因为即使您的算法
-
HashMap可序列化
问题内容: HashMap实现了Serializable接口;因此可以序列化。我已经看过HashMap的实现,Entry []表被标记为瞬态。由于Entry []表是存储Map的全部内容的表,如果无法序列化,则在反序列化期间如何构造Map 问题答案: 如果您查看源代码,将会看到它不依赖默认的序列化机制,而是手动写出所有条目(作为键和值的交替流): 这比数组要紧凑,数组可以包含许多空条目,链接链
-
 可视化测试
可视化测试主要内容:可视化检测系统可视化测试用于通过定义数据来检查软件故障发生的情况,开发人员可以快速识别故障原因,并清楚地表达信息,以便任何其他开发人员可以利用这些信息。 可视化测试旨在显示实际问题,而不仅仅是描述它,显着增加理解和清晰度,以便快速解决问题。 可视化意味着我们可以看到的。因此,可视化测试需要整个过程的视频录制。它捕获视频格式系统测试时发生的所有事情。测试仪将图片网络摄像头中的图片和来自麦克风的音频评论作为输入值。
-
 TensorFlow TensorBoard可视化
TensorFlow TensorBoard可视化TensorFlow包含一个可视化工具 - TensorBoard。它用于分析数据流图,也用于理解机器学习模型。TensorBoard的重要功能包括有关垂直对齐中任何图形的参数和详细信息的不同类型统计信息的视图。 深度神经网络包括有36,000个节点。TensorBoard有助于在高级块中折叠这些节点并突出显示相同的结构。这允许更好地分析关注计算图的主要部分的图。TensorBoard可视化非常具
-
规模化敏捷
在敏捷方法中,有两个流行的框架 - Scrum和看板。团队级别使用scrum和kanban作为框架。随着受欢迎程度的提高,行业开始灵活扩展以适应更大的组织。有两种流行的方法可以促进,它们是scrum框架和规模化敏捷框架(SAFe)。Scrum和看板是在组织内扩展敏捷的高起点。 Scrum中的Scrum Scrum是个人团队最具吸引力的敏捷框架。当几个Scrum团队在一个大项目上合作时,scrum的
-
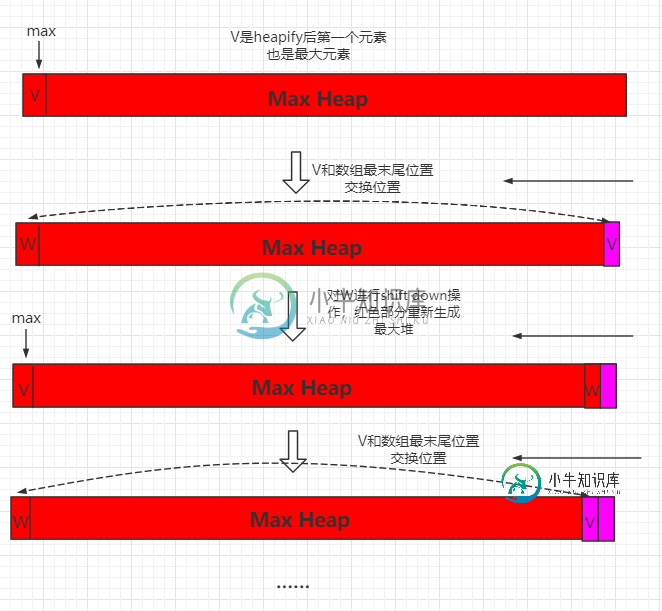 优化堆排序
优化堆排序主要内容:src/runoob/heap/HeapSort.java 文件代码:上一节的堆排序,我们开辟了额外的空间进行构造堆和对堆进行排序。这一小节,我们进行优化,使用原地堆排序。 对于一个最大堆,首先将开始位置数据和数组末尾数值进行交换,那么数组末尾就是最大元素,然后再对W元素进行 shift down 操作,重新生成最大堆,然后将新生成的最大数和整个数组倒数第二位置进行交换,此时到处第二位置就是倒数第二大数据,这个过程以此类推。 整个过程可以用如下图表示: Java 实
-
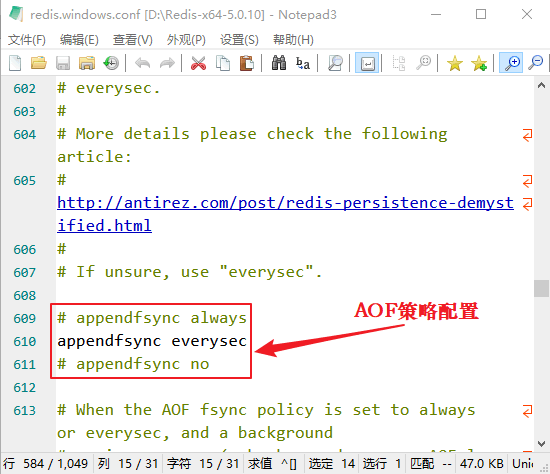 Redis AOF持久化
Redis AOF持久化主要内容:开启AOF持久化,AOF持久化机制,AOF策略配置,AOF和RDB对比AOF 被称为追加模式,或日志模式,是 Redis 提供的另一种持久化策略,它能够存储 Redis 服务器已经执行过的的命令,并且只记录对内存有过修改的命令,这种数据记录方法,被叫做“增量复制”,其默认存储文件为 。 开启AOF持久化 AOF 机制默认处于未开启状态,可以通过修改 Redis 配置文件开启 AOF,如下所示: 1) Windows系统 执行如下操作: 2) Linux系统 执行如下
-
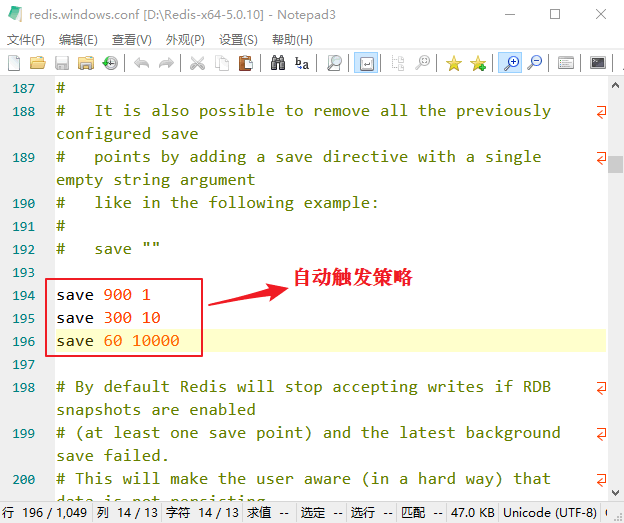 Redis RDB持久化
Redis RDB持久化主要内容:RDB快照模式原理,RDB持久化触发策略,RDB持久化优劣势Redis 是一款基于内存的非关系型数据库,它会将数据全部存储在内存中。但是如果 Redis 服务器出现某些意外情况,比如宕机或者断电等,那么内存中的数据就会全部丢失。因此必须有一种机制能够保证 Redis 储存的数据不会因故障而丢失,这就是 Redis 的数据持久化机制。 数据的持久化存储是 Redis 的重要特性之一,它能够将内存中的数据保存到本地磁盘中,实现对数据的持久存储。这样即使在服务器
-
 Spring MVC国际化
Spring MVC国际化主要内容:1. 配置 Spring MVC 的配置文件,2. 编写国际化资源文件,3. 在页面中获取国际化内容,4. 手动切换语言环境,示例国际化(Internationalization 简称 I18n,其中“I”和“n”分别为首末字符,18 则为中间的字符数)是指软件开发时应该具备支持多种语言和地区的功能。 换句话说,软件应该能够同时应对多个不同国家和地区用户的访问,并根据用户地区和语言习惯,提供相应的、符合用具阅读习惯的页面和数据。例如,为中国用户提供汉语界面显示,为美国用户提供提供英语界
-
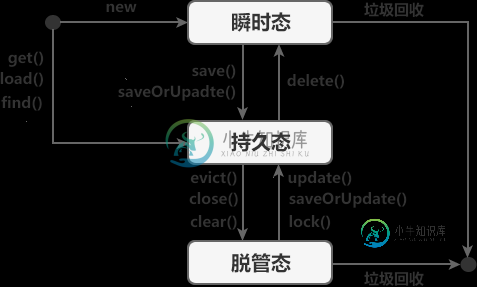 Hibernate持久化类
Hibernate持久化类持久化类(Persistent Object )简称 PO,在 Hibernate 中, PO 是由 POJO(即 java 类或实体类)和 hbm 映射配置组成。 简单点说,持久化类本质上就是一个与数据库表建立了映射关系的普通 Java 类(实体类),例如 User 类与数据库中 user 表通过映射文件 User.hbm.xml 建立了映射关系,此时 User 就是一个持久化类。 持久化类的规
-
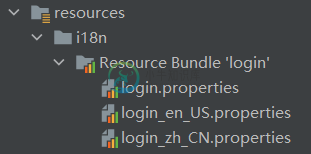 Spring Boot国际化
Spring Boot国际化主要内容:1. 编写国际化资源文件,2. 使用 ResourceBundleMessageSource 管理国际化资源文件,3. 获取国际化内容,验证,手动切换语言国际化(Internationalization 简称 I18n,其中“I”和“n”分别为首末字符,18 则为中间的字符数)是指软件开发时应该具备支持多种语言和地区的功能。换句话说就是,开发的软件需要能同时应对不同国家和地区的用户访问,并根据用户地区和语言习惯,提供相应的、符合用具阅读习惯的页面和数据,例如,为中国用户提供汉语界面显示
-
优化MongoDB调用
我有一个mongoDB集合,我正在使用java驱动程序从mongo集合中获取数据。 我有一个电话号码列表,我需要在mongoDB集合中搜索所有这些手机号码。 假设我有500个手机号码,目前从我的java代码来看,我会说: 现在的问题是我打了500次DB。。 我想知道是否有更好的方法来处理,例如在RDBMS中,我们如下所示 所以像上面的查询一样,单次调用就足够了,但是在in子句中传递给SQL的参数数