《埃克斯工业》专题
-
如何摆脱依赖错误加载詹金斯?
刚刚下载了詹金斯。战争和做了一个java-jar jenkins。war(在windows 8.1上) 去http://127.0.0.1:8080/manage,我明白了: 有依赖错误加载一些插件: 重复java-jarjenkins.war,每一次都打开战争包装。有没有他住的地方,这样你就可以从命令行运行他? 如何消除插件错误?
-
千分尺 - 普罗米修斯量规显示NaN
我试图在Spring Boot 2.0.0 .版本中使用Micrometer.io生成普罗米修斯指标 当我试图将列表的大小公开为Gauge时,它一直显示NaN。在留档中,它说; 你有责任对你用量规测量的状态对象保持强烈的引用。 我已经尝试了一些不同的方法,但我不能解决这个问题。这是我的代码和一些试验。 有人能帮忙解决这个问题吗?任何帮助都将不胜感激。
-
斯威夫特处理数字真的很慢吗?
在使用swift教程时,我开始编写一个自定义的方法来检查给定的是否为素数。 在编写完它之后,我意识到它工作正常,但发现在一些相当大的数字上执行有点慢(仍然比)。 所以我用objc编写了相同的代码,并且代码的执行速度快得多(是66倍)。 以下是swift代码: 和对象代码: 在中: 这就产生了:
-
普罗米修斯/格拉法纳反单调性
有没有办法使格拉法纳的普罗米修斯计数器真正单调? 每当服务器重新启动时,我的服务器上的计数器(使用Prometheus Java库)就会重置,Grafana中的计数器也会降至零。我在文档中找不到普罗米修斯查询的方法。Java库也没有提供使计数器在重新启动时持久化的方法。
-
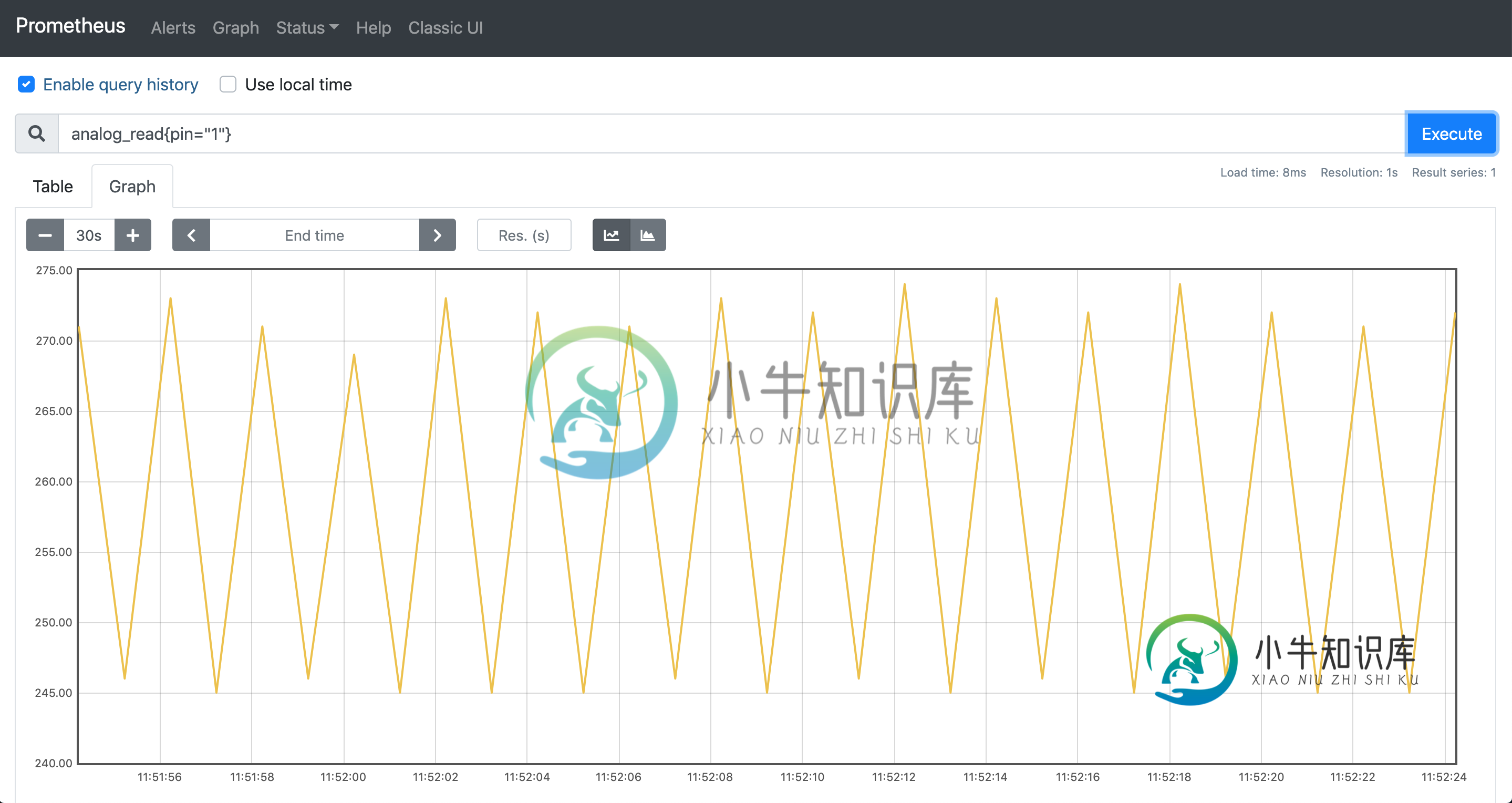 普罗米修斯和节点导出器(毫秒)
普罗米修斯和节点导出器(毫秒)我有一个带有prom客户端的node express应用程序,用于监视串行连接并向httpendpoint报告值,串行速度为9600波特,正在通过网络传输一些统计数据。Prometheus实例以1000毫秒的间隔配置作业,以针对该endpoint并获取度量。我希望能够在至少10毫秒的分辨率内看到这个指标,但似乎普罗米修斯图形分辨率不接受小于1秒的分辨率。我应该怎么做才能让普罗米修斯以至少10毫秒的
-
普罗米修斯组通过标签的子串
我试图解决一个问题,使总和和组查询普罗米修斯上的一个指标,其中的标签分配给度量值唯一的我的总和和和组的要求。 我有一个ElasticSearch索引的指标采样大小,其中索引名称被标记在指标上。索引是这样命名的,并放置在标签"index"中:
-
所有可能的毕达哥拉斯三元组
问题来了 找出所有毕达哥拉斯三元组中的1边、2边和斜边都不超过500。使用三重嵌套for循环,尝试各种可能性。 下面是我的尝试 但它没有成功,似乎是一个无限循环。请帮忙。 请注意:我是C语言的新手,我是自学的。而且,这不是家庭作业,我做问题陈述是因为这是表达问题的最佳方式。 编辑 右侧1侧2 运行成功(总时间: 1s) 编辑2 工作代码
-
用带卷的普罗米修斯存储数据
我应该在values.yaml之外添加一些东西吗?
-
将pod指标拉到外部普罗米修斯
我试图使用现有的Prometheus(集群外部)从EKS集群内部聚合所有的指标,EC2(CPU、ram、disk)和POD(CPU、ram、disk)。我开始使用node-exporter、kube-state-metrics添加数据,但我一直坚持部署metrics-server。使用helm I conf并安装它,和正在提取数据,但是有人能告诉我如何将所有这些都提取到外部的Prometheus吗
-
不带Spring的定制普罗米修斯公制
我需要为web应用程序提供自定义度量。问题是我不能使用Spring,而是必须使用jax-rsendpoint。要求非常简单。假设您有一个带有键值对的映射,其中键是度量名称,值是一个简单的整数,它是一个计数器。代码如下所示:
-
 Openshift 4.4-普罗米修斯无法看到度量
Openshift 4.4-普罗米修斯无法看到度量oc版本: 客户端版本:4.4.3服务器版本:4.4.3 Kubernetes版本:V1.17.1 图片:quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:6a5398997bd7ccddd8d0be0f0f2d9dcae8dddc01d54e6877437f07397c273048 在其他吊舱上没有任何错误,只在普罗米修斯操作员吊舱日志中
-
向普罗米修斯发布千分尺度量
响应于“/acturet/prometheus”的DistributionSummary可用的度量仅是度量的Sum、Max和Count。 我想显示在选定的时间量内API调用所用的平均时间。用于EX:API在过去5分钟内所用的平均时间。
-
 如何在詹金斯中执行硒2测试
如何在詹金斯中执行硒2测试> 我希望能够与Jenkins一起使用硒2。 我是两者的新手,所以请原谅我的无知。 我注意到了下面这个jenkins的插件,并安装了它。 我有一个基类如下: 我在Jenkins的Selenium插件上有以下配置: .. 一旦我尝试构建该项目并在Jenkins中运行JUnit selenium测试,它就成功构建,但它自己的测试失败了。( 编辑:我刚刚注意到您可以在Jenkins中构建后存档JUnit
-
将OWL公理转换为曼彻斯特语法
有没有办法将OWL公理转换成曼彻斯特语法?我知道OWL-API将允许您将曼彻斯特语法中的一个句子解析为OWL函数语法,但我需要做的正好相反。
-
朴素贝叶斯 - 共和党还是民主党
我们来看另一个数据集——美国国会投票数据,可以从 机器学习仓库 获得。 每条记录代表一个选民,第一列是分类名称(democrat, republican),之后是16条法案,用y和n表示该人是否支持。 残疾婴儿法案 用水成本分摊 预算改革 医疗费用 萨瓦尔多援助 校园宗教组织 反卫星武器 尼加拉瓜援助 MX导弹 移民法案 合成燃料缩减 教育支出法案 有毒废物基金 犯罪 出口免税 南非出口管控 文件