《埃克斯工业》专题
-
4.8.谢尔宾斯基三角形
另一个展现自相似性的分形是谢尔宾斯基三角形。 Figure 3 是一个示例。谢尔宾斯基三角形阐明了三路递归算法。用手绘制谢尔宾斯基三角形的过程很简单。 从一个大三角形开始。通过连接每一边的中点,将这个大三角形分成四个新的三角形。忽略刚刚创建的中间三角形,对三个小三角形中的每一个应用相同的过程。 每次创建一组新的三角形时,都会将此过程递归应用于三个较小的角三角形。 如果你有足够的铅笔,你可以无限重复
-
聚类 - GMM(高斯混合模型)
现有的高斯模型有单高斯模型(SGM)和高斯混合模型(GMM)两种。从几何上讲,单高斯分布模型在二维空间上近似于椭圆,在三维空间上近似于椭球。 在很多情况下,属于同一类别的样本点并不满足“椭圆”分布的特性,所以我们需要引入混合高斯模型来解决这种情况。 1 单高斯模型 多维变量X服从高斯分布时,它的概率密度函数PDF定义如下: 在上述定义中,x是维数为D的样本向量,mu是模型期望,sigm
-
温斯顿:如何旋转日志
问题内容: 使用Winston处理node.js的日志时,如何旋转日志。也就是说,如何在应用运行的每一天创建一个新文件? 问题答案: 温斯顿作家和维护者在这里。 每天登录到新文件是当前的一项开放功能请求:https : //github.com/flatiron/winston/issues/10。希望看到有人实施它。 也就是说,还有其他选择: 文件传输接受一个maxsize选项,当超过一定大小(
-
库伯内特斯入口设置
我试图设置Kubernetes入口,将外部http流量路由到前端pod(路径/)和后端pod(路径/rest/*),但我总是得到400错误,而不是主nginx索引。html。 所以我在第https://cloud.google.com/kubernetes-engine/docs/tutorials/http-balancer页尝试了谷歌库伯内特斯的例子,但我总是得到400个错误。有什么想法吗?
-
库伯内特斯云提供商
我是Kubernetes的新手,他们的概念我不太清楚:云提供商。 我已经使用RKE(Rancher引擎)安装了我的库伯内特斯集群。 我的集群设置在rancher2的顶部。 我的节点是托管OVH服务器的虚拟机。 我设法让运行中的应用程序具有L7入口和ClusterIP服务,但每次我尝试使用L4负载平衡器时,负载平衡器都处于挂起状态。根据https://github.com/rancher/ranch
-
斯特拉皮上传提供商
我正在使用下一个js,并希望strapi图像上传到我的下一个js公共文件夹。这似乎可以通过上传提供商,但没有使用它们的留档,我也找不到任何使用此的项目。谁能给我指出正确的方向?
-
尤里卡和库贝内特斯
我正在使用Spring Boot/Netflix OSS和Kubernetes组合一个概念验证来帮助识别gotchas。这也是为了证明普罗米修斯和Graphana等相关技术。 此服务以configServer-3481062421-tmv4d的名称结束运行。然后,我在配置服务器日志中看到异常,因为它试图找到eureka实例,但无法找到。 我在本地使用docker-compose和链接进行了相同的设
-
加特林斯卡拉进纸机
我试图将提供Id的馈线的值输入到。txt文件。他们有没有办法直接从feeder中提取值,而不必从每个会话中提取Id?
-
斯坦福核心NLP NER输出
我曾使用grep和awk从斯坦福CRF-NER的“内联XML”中提取英语文本中的命名实体,我希望在其他人类语言中使用相同的更大工作流。 我一直在尝试法语(西班牙语似乎给我带来了一个Java错误,这是另一个故事),并使用我得到标准文本输出,每个句子都有各种类型的注释,包括正确组合在一起的多单词实体,如下所示: 我知道解析它是可能的,但当我真的只是想要整个文件中的实体列表时,这似乎浪费了很多处理。 我
-
致命:无效 ID 詹金斯 IIS
我试图设置詹金斯拉,并建立一个项目从bitbucket。 我在IIS 8.5 Server 2012 r2上使用这个。我已经设置了Git和Bitbucket插件。 我已经建立了一个项目: 我不确定这是否是问题的一部分,但我的回购中只有这一个分支。 运行构建时,我收到以下错误,我找不到任何有关无效ID的信息,任何人都可以为我指出正确的方向吗? 它看起来像是从上次提交中获取哈希,然后说无效ID,我不确
-
库伯内特斯OOM杀人舱
我有一个简单的容器,它由安装在阿尔卑斯山上的OpenLDAP组成。它被安装为以非root用户身份运行。我能够使用我的本地Docker引擎运行容器而没有任何问题。但是,当我将其部署到我们的库伯内特斯系统时,它几乎立即被OOMKill杀死。我尝试在没有任何更改的情况下增加内存。我还查看了pod的内存使用情况,没有发现任何异常。 服务器启动为slapd-d debug-hldap://0.0.0.0:1
-
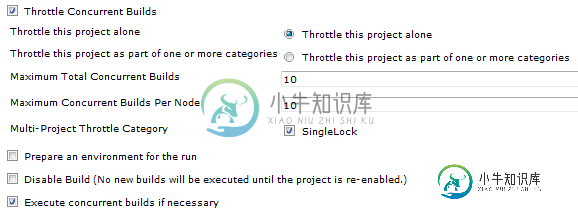 詹金斯油门并发构建
詹金斯油门并发构建我要求允许在单个从节点的单个Jenkins作业中进行并发构建。 因此,我启用了throttle concurrent build选项,并发布了我能够进行并发构建的帖子。但是,如果我给MaxNo of concurrent builds 7或大于7,那么它总是一次处理6个构建,第7个构建处于等待状态。 在这种情况下有没有限制?
-
如何离线安装詹金斯?
我可以在我的笔记本电脑上成功安装jenkins online。但是,当试图离线安装詹金斯(jenkins)时(在我无法连接到互联网的办公室工作站上),情况就不妙了。在经营詹金斯家族之后。命令行战争虽然jenkins已经成功安装,但一些插件却丢失了。我设法从帖子中获得了一些帮助,如何在Jenkins中手动安装插件? 但是每个插件都必须单独下载,然后复制到我的离线机器上。所以我耍了个花招。我复制了(在
-
斯坦福核心nlp java输出
我是Java和Stanford NLP工具包的新手,并试图在一个项目中使用它们。具体地说,我尝试使用Stanford Corenlp toolkit来注释文本(使用Netbeans而不是命令行),并尝试使用http://nlp.Stanford.edu/software/Corenlp.shtml#Usage上提供的代码(使用Stanford Corenlp API)。问题是:有人能告诉我如何在文
-
OpenJDK 17阿尔卑斯山图像
我正在寻找一个基于alpine的openjdk 17 docker图像。看起来我们这里有一个 https://hub.docker.com/layers/openjdk/library/openjdk/17-alpine/images/sha256-a996cdcc040704ec6badaf5fecf1e144c096e00231a29188596c784bcf858d05?context=ex