《分析》专题
-
无法将JSONObject转换为com。作语法分析分析地质点
我正在使用以下命令在JsonObject中保存geopoint: 在此之后,我将发送这个Jsonobject来解析云。 现在我试着用这个把它拿回来: 首先在线路上: 我得到了类型不匹配的错误。当我将其输入到parse对象中时,它运行良好;但是,当我尝试运行apk时,出现了以下错误:
-
使用频率分析/密码分析技术破译密码文本
本网站(https://www.guballa.de/substitution-solver)他做到了。 我必须通过频率分析来做到这一点(https://en.wikipedia.org/wiki/Frequency_analysis) 我面临的主要问题是,当我替换时,检查单词是否看起来像英语单词。 请指导我如何处理这个问题 谢谢哈基德
-
第10章 OpenCL的分析和调试 - 10.5 使用CodeXL分析内核
分析模式下,CodeXL可以当做静态分析工具使用。AMD显卡上,分析模式可以用来编译、分析和反汇编一个OpenCL内核。分析模式可选择界面方式和命令行方式。在这之后我们就称CodeXL为“内核分析器”。内核分析器也可以通过命令行使用,在CodeXL安装目录下,有一个CodeXLAnalyzer.exe,可以直接在命令行中执行。 内核分析器是一个离线编译器,还是一个分析工具。其能将内核源码编译成任意
-
 数据分析面试|美团商业分析2|秋招三面Offer
数据分析面试|美团商业分析2|秋招三面Offer笔试,8月15日,行测题,包括四部分:逻辑推理、数字判断、言语理解、资料分析。 一面,8月20日 1. 自我介绍。(主要经历是数据挖掘建模) 2. 介绍下实习中项目的脉络?遇到的困难?怎么解决?结果怎么样? 3. 除了技术上,做了哪些工作?(说明商分更重视业务能力) 4. 为什么到这家公司实习?答:想了解认识直播这个行业。(没有过相关行业思考的别给自己挖坑) 5. 追问:现在对于行业的认识和思考?
-
Python分部
问题内容: 我试图将一组从-100到0的数字归一化到10-100的范围,并且遇到了问题,只是注意到即使根本没有任何变量,这也无法评估我期望的方式: 浮动划分也不起作用: 如果除法的任一侧都转换为浮点数,它将起作用: 第一个示例中的每一边都被评估为一个int,这意味着最终答案将被转换为一个int。由于0.111小于.5,因此将其舍入为0。在我看来,这不是透明的,但我想是这样的。 有什么解释? 问题答
-
JDBC分页
问题内容: 我想使用JDBC实现分页。我想知道的实际情况是“如何分别从数据库中获取第1页和第2页的前50条记录,然后再获得50条记录” 我的查询是[数据表包含20,000行] 对于第1页,我可以获得50条记录,对于第2页,我想要获得下50条记录。如何在JDBC中有效地实现它? 我已经搜索过,发现这是跳过首页记录的方法,但是在大型结果集上花费一些时间,我不想花这么多时间。另外,我不想在查询中使用和+
-
ASP.NET 分页
本文向大家介绍ASP.NET 分页,包括了ASP.NET 分页的使用技巧和注意事项,需要的朋友参考一下 示例 ObjectDataSource 如果使用ObjectDataSource,几乎已经为您处理了所有事情,只需告诉GridViewAllowPaging并给它一个即可PageSize。 手动装订 如果手动绑定,则必须处理该PageIndexChanging事件。只需设置DataSource和
-
 Bootstrap 分页
Bootstrap 分页主要内容:分页(Pagination),实例,实例,实例,翻页(Pager),实例,实例,实例,分页更多实例本章将讲解 Bootstrap 支持的分页特性。分页(Pagination),是一种无序列表,Bootstrap 像处理其他界面元素一样处理分页。 分页(Pagination) 下表列出了 Bootstrap 提供的处理分页的 class。 Class 描述 示例代码 .pagination 添加该 class 来在页面上显示分页。 .disabled, .active 您可以自定义链接,
-
Bootstrap4 分页
主要内容:实例,当前页页码状态,实例,不可点击的分页链接,实例,分页显示大小,实例,面包屑导航,实例,分页的对齐方式,实例网页开发过程,如果碰到内容过多,一般都会做分页处理。 Bootstrap 4 可以很简单的实现分页效果。 要创建一个基本的分页可以在 <ul> 元素上添加 .pagination 类。然后在 <li> 元素上添加 .page-item 类,<li> 元素的 <a> 标签上添加 .page-link 类: 实例 <ul class="pagination"> <li class
-
 MongoDB分片
MongoDB分片主要内容:MongoDB 中的分片,分片实例分片是跨多台机器存储数据的过程,它是 MongoDB 满足数据增长需求的方法。随着数据的不断增加,单台机器可能不足以存储全部数据,也无法提供足够的读写吞吐量。通过分片,您可以添加更多计算机来满足数据增长和读/写操作的需求。 为什么要分片? 在复制中,所有写操作都将转到主节点; 对延迟敏感的查询仍会转到主查询; 单个副本集限制为 12 个节点; 当活动数据集很大时,会出现内存不足; 本地磁盘不够大;
-
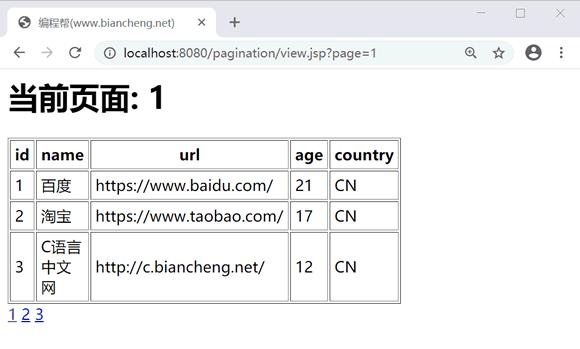 JSP分页
JSP分页主要内容:实现分页步骤,示例当数据有几万、几十万甚至上百万时,用户必须要拖动页面才能浏览更多的数据,很大程度的影响了用户体验。这时可以使用分页来显示数据,能够使数据更加清晰直观,且不受数量的限制。 分页的方式主要分为两种: 将查询结果以集合等形式保存在内存中,翻页时从中取出一页数据显示。该方法可能导致用户浏览到的是过期数据,且如果数据量非常大,查询一次数据就会耗费很长时间,存储的数据也会占用大量的内存开销。 每次翻页时只从数
-
MyBatis分页
MyBatis 的分页功能是基于内存的分页,即先查询出所有记录,再按起始位置和页面容量取出结果。 本节我们为查询网站记录增加分页功能,要求结果列表按照 id 升序排列(本节示例基于《 第一个MyBatis程序》一节的代码实现)。 WebsiteMapper 中方法如下。 相比原来的 selectWebsite 方法,增加了两个参数,起始位置(from)和页面容量(pageSize),用于实现分页查
-
apachekafka分区
我已经在kafka上工作了相当长的六个月,我对用户延迟和存储到主题分区中的数据有一些疑问。 问题1:最初,当我开始阅读Kafka并了解如何使用Kafka的功能时,我被教导说,一个只有一部分和一个复制因子的主题会创造奇迹。经过相当长的六个月的工作,将我的项目迁移到live之后,使用我的主题消息的消费者开始给我一个延迟。我阅读了许多关于消费者延迟的堆栈溢出答案,得出结论,如果我增加某个主题的分区和复制
-
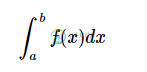 Scipy积分
Scipy积分主要内容:单积分,多重积分,双重积分当一个函数不能被分析积分,或者很难分析积分时,通常会转向数值积分方法。 SciPy有许多用于执行数值积分的程序。 它们中的大多数都在同一个库中。 下表列出了一些常用函数。 编号 示例 描述 1 单积分 2 二重积分 3 三重积分 4 n倍多重积分 5 高斯积分,阶数 6 高斯正交到容差 7 Romberg积分 8 梯形规则 9 梯形法则累计计算积分 10 辛普森的规则 11 Romberg积分 1
-
预分配
若一条代码不能向量化,你可以通过预分配任何输出结果已保存其中的向量或数组以加快for 循环。例如,这个代码用zeros函数把for循环产生的向量预分配。这使得for循环的执行显著加快。 r = zeros(32,1); for n = 1:32 r(n) = rank(magic(n)); end 上例中若没有使用预分配,MATLAB的注释器利用每次循环扩大r向量。向量预分配排除了该步骤